
Что такое лингвистическое моделирование?
Лингвистическое моделирование — это построение систем или моделей, которые могут обрабатывать лингвистическую информацию (учебный материал) и выдавать нечто похожее на результат обработки человеческого языка.
Задачи лингвистического моделирования:
- поиск определенных лингвистических данных (например, данных корпуса);
- разработка гипотез;
- проверка гипотез.
Зачем нужно лингвистическое моделирование?
Если коротко, то лингвистическое моделирование помогает программисту решить следующие задачи:
- упрощает выбор подходящего вида лингвоанализа;
- позволяет спрогнозировать результативность выбранного вида анализа и исключить альтернативные варианты;
- обеспечивает готовыми алгоритмами, оптимизирующими процесс компьютерной обработки текста.
Общепринятыми понятиями в лингвистическом моделировании являются:
Синтаксис: совокупность правил, которые определяют структуру предложений определенного языка. Синтаксис включает в себя порядок слов, грамматику, иерархическую структуру, согласование, субкатегоризацию.
Фразовая структура: комбинация слов, образующих фразу. Фразы могут быть именными (NP), глагольными (VP), предложными (PP) и т. д.
Конституент/зависимость: конституент — структура, состоящая из отдельных слов или их цепочек; зависимость — сочетание слов, одно из которых зависит от другого. К примеру, детерминатив (DT) и прилагательное (ADJ) могут зависеть от существительного (N).
Синтаксический анализ: установление взаимосвязи между словами или лексемами с помощью вычислительного алгоритма. В Python заложено несколько пакетов обработки естественного языка (NLP), которые используются для синтаксического анализа.
Поскольку разные структуры предложений с одними и теми же словами могут иметь разные значения, синтаксический анализ может помочь понять текст.
POS-разметка (частеречная разметка)
Как известно, POS-разметка является одним из основных компонентов лингвистического моделирования. Она выполняется в два этапа:
- разделение текста на предложения на основе пунктуации;
- выделение лексем (маркирование): разбиение предложения по границам слов.
Классы слов, или лексические категории слов:
- содержательные слова (открытые классы): существительные, глаголы, прилагательные, наречия;
- функциональные слова (закрытые классы): детерминативы, местоимения, предлоги, союзы, дополнительные элементы.
Разделение слов на части речи (POS) происходит на основе их формальных признаков.
Использование NLP-инструментов для POS-разметки
Здесь мы будем записывать предложения на языке python с помощью пакета библиотеки NLTK для POS-разметки.
# импорт nltk
import nltk
# некоторые дополнительные компоненты для сегментации, токенизации
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
# загрузка универсального набора тегов
nltk.download('universal_tagset')
# импорт класса word_tokenize
from nltk.tokenize import word_tokenize
# применение маркера слова к текстовой строке и нахождение тега POS
nltk.pos_tag(word_tokenize("In the present study, we examine the outcomes of such a period of no exposure on the neurocognition of L2 grammar:"), tagset='universal')Грамматика с фразовой структурой (PSG)
PSG (phrase structure grammar) — замена последовательности слов без изменения значения предложения. Такая последовательность слов рассматривается как непосредственная составляющая.
Базовые правила PSG :
- NP -> DET N
- VP -> V NP
- S -> NP VP
Специфические правила:
- NP -> (Det)(AdjP+) N
- NP -> NP (PP+)
- NP -> PP CP
- AdjP -> (AdvP) Adj
- AdvP -> (AdvP) Adv
- PP -> P NP
- VP -> V
- VP -> (AdvP+) V (AdvP+)
- VP -> (AdvP+) V (NP) (NP) (AdvP+) (PP+) (AdvP+)
Знак “+” означает одно или несколько событий.
Графическое представление синтаксических деревьев
Для построения синтаксического дерева структуры предложения используется принцип восходящего анализа (“снизу вверх”). Следующие шаги помогут осуществить этот анализ:
- Промаркируйте POS-тегами все слова в предложении.
- Найдите фразы.
- Постройте дерево в обратном порядке (сверху вниз).
- Проверьте правильность построения дерева с помощью правил.
Ниже приведен пример синтаксического дерева, построенного для предложения Peter prefers the flight from Denver (“Питер предпочитает рейс из Денвера”):
Peter -> NP
prefers -> V
the -> Det
flight -> N
from -> P
Denver -> NP
NP -> Det N
NP -> NP PP
PP -> P NP
VP -> V NP
S -> NP VPДля проверки решения используйте NLTK:
import nltk
from nltk import Production, CFG
# грамматика
cgrammar = nltk.CFG.fromstring("""
S -> NP VP
VP -> V NP
PP -> P NP
NP -> NP PP | Det N | 'Peter' | 'Denver'
V -> 'prefers'
P -> 'from'
N -> 'flight'
Det -> 'the'
""")
# печать грамматики
print(cgrammar, '\n')
sent = ['Peter', 'prefers', 'the', 'flight', 'from', 'Denver']
# Используйте анализатор диаграмм
cparser = nltk.ChartParser(cgrammar)
for tree in cparser.parse(sent):
print(tree)
# постройте деревья
import svgling
svgling.draw_tree(tree)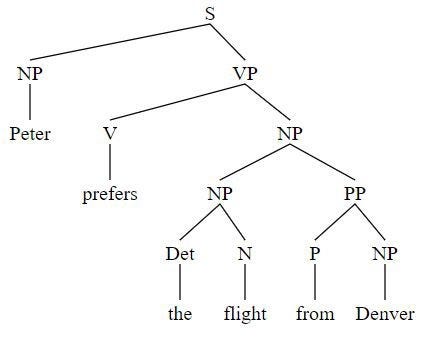
Результат построения синтаксического дерева
Неоднозначная грамматика
В предложении могут встретиться различные типы неоднозначности:
- лексическая неоднозначность;
- частеречная неоднозначность;
- структурная неоднозначность;
- неоднозначность вложения;
- неоднозначность координации.
NLTK поможет обнаружить два разных дерева неоднозначного предложения. Для демонстрации неоднозначности ниже приводится фраза I shot an elephant in my pajamas (“Я застрелил слона в пижаме”):
import nltk
a_grammar = nltk.CFG.fromstring("""
S -> NP VP
PP -> P NP
NP -> Det N | Det N PP | 'I'
VP -> V NP | VP PP
Det -> 'an' | 'my'
N -> 'elephant' | 'pajamas'
V -> 'shot'
P -> 'in'
""")
sent = ['I', 'shot', 'an', 'elephant', 'in', 'my', 'pajamas']
parser = nltk.ChartParser(a_grammar)
for tree in parser.parse(sent):
print(tree)Результаты вывода могут быть следующие:
(S
(NP I)
(VP
(VP (V shot) (NP (Det an) (N elephant)))
(PP (P in) (NP (Det my) (N pajamas)))))
(S
(NP I)
(VP
(V shot)
(NP (Det an) (N elephant) (PP (P in) (NP (Det my) (N pajamas))))))Рисуем деревья:
import os
import svgling
from nltk.tree import Tree
from nltk.draw.tree import TreeView
# используем строчный формат
t1 = Tree.fromstring('(S(NP/I)(VP(VP(V/shot)(NP(Det/an)(N/elephant)))(PP(P/in)(NP(Det/my)(N/pajamas)))))')
svgling.draw_tree(t1)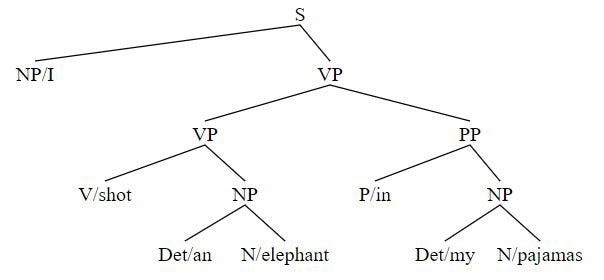
t2 = Tree.fromstring('(S(NP/I)(VP(V/shot)(NP(Det/an)(N/elephant)(PP(P/in)(NP(Det/my)(N/pajamas))))))')
svgling.draw_tree(t2)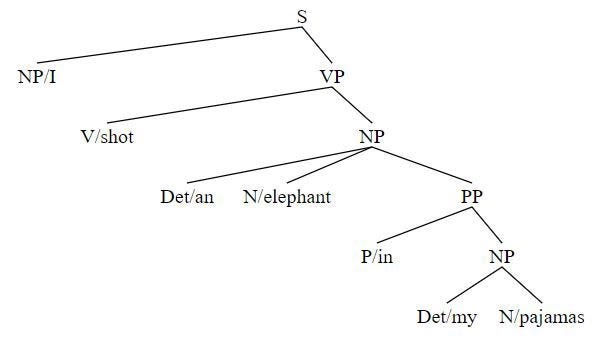
Контекстно-свободные грамматики (CFG)
CFG (context-free grammars) являются наиболее широко используемой формальной системой для моделирования структуры компонентов в естественных языках, таких как английский. Их также называют фразово-структурными грамматиками.
Вот правила генерации контекстно-свободной грамматики для предложений:
- The man wrote a letter and the girl bought a present (“Мужчина написал письмо, а девушка купила подарок”).
- The grandmother baked a cake and a bread (“Бабушка испекла пирог и хлеб”).
S -> S CONJ S | NP VP
NP -> Det N | NP CONJ NP
VP -> V NP
Det -> "the" | "a"
N -> "man" | "letter" | "girl" | "present" | "grandmother" | "cake" | "bread"
V -> "wrote" | "bought" | "baked"
CONJ -> "and"Анализ CFG
Существует два способа анализа строки, исходя из данной грамматики.
- сверху вниз;
- снизу вверх.
В первом случае мы начинаем с S и постепенно выводим предложение; во втором — действуем в обратном порядке, начиная с предложения и приходя к S.
Восходящий синтаксический анализатор, реализованный в NLTK, аналогичен методу “снизу вверх”. Он действует в двухфазном режиме “сдвиг-свертка”: перемещает входные данные в стек и заменяет верхние элементы одним элементом. Это продолжается до тех пор, пока он не найдет S. Ограниченность возможностей восходящего синтаксического анализатора заключается в том, что он не может анализировать неоднозначное предложение.
import nltk
from nltk import CFG
grammar = nltk.CFG.fromstring("""
S -> S CONJ S | NP VP
NP -> Det N | NP CONJ NP
VP -> V NP
Det -> "the" | "a"
N -> "man" | "letter" | "girl" | "present" | "grandmother" | "cake" | "bread"
V -> "wrote" | "bought" | "baked"
CONJ -> "and"
""")
sr_parser = nltk.ShiftReduceParser(grammar, trace=2)
sent1 = 'the man wrote a letter and the girl bought a present'.split()
sent2 = 'the grandmother baked a cake and a bread'.split()
print('sent1:')
for tree in sr_parser.parse(sent1):
print(tree)
print('sent2:')
for tree in sr_parser.parse(sent2):
print(tree)Если мы запустим приведенный выше код, то увидим, что анализатор способен идеально проанализировать первое предложение. Но он не способен справиться с анализом второго предложения, так как оно неоднозначное. Анализатор не может действовать в обратном направлении, чтобы найти альтернативное решение. После нахождения NP и VP все просто сводится к S, а не к поиску других возможностей.
Чтобы преодолеть эту проблему, можно использовать анализатор диаграмм.
import nltk
from nltk import CFG
grammar = nltk.CFG.fromstring("""
S -> S CONJ S | NP VP
NP -> Det N | NP CONJ NP
VP -> V NP
Det -> "the" | "a"
N -> "man" | "letter" | "girl" | "present" | "grandmother" | "cake" | "bread"
V -> "wrote" | "bought" | "baked"
CONJ -> "and"
""")
chart_parser = nltk.BottomUpChartParser(grammar, trace=2)
sent1 = 'the man wrote a letter and the girl bought a present'.split()
sent2 = 'the grandmother baked a cake and a bread'.split()
print('sent1:')
for tree in chart_parser.parse(sent1):
print(tree)
print('sent2:')
for tree in chart_parser.parse(sent2):
print(tree)Вероятностный анализ
Вероятностный анализ — еще один способ преодолеть неоднозначность, создаваемую множественным анализированием. Этот вид анализа очень похож на CFG, только в нем каждое правило соотносится с вероятностью. Полная вероятность конкретной фразы (NP, VP и т.д.) должна составлять 1,0.
В NLTK загружены два алгоритма для PCFG (вероятностных CFG):
- анализатор Витерби PCFG, результаты которого отличаются большей вероятностью;
- анализатор внутренних диаграмм, выдающий все результаты с разной степенью вероятности.
Мы можете легко загрузить эти PCFG.
from nltk.grammar import PCFG, induce_pcfg, toy_pcfg1, toy_pcfg2
# Печать игрушечного PCFG, который уже находится в NLTK
print(toy_pcfg1)
# Анализатор Витерби
from nltk.parse import ViterbiParser
tokens = "I saw the man with the telescope".split()
viterbi_parser = nltk.ViterbiParser(toy_pcfg1, trace=2)
for tree in viterbi_parser.parse(tokens):
print('Viterbi Parser:',tree)
# Внутренний анализатор диаграмм с упорядочением очередей
from nltk.parse import pchart
inch_parser = nltk.InsideChartParser(toy_pcfg1, trace=2)
for tree in inch_parser.parse(tokens):
print('InsideChartParser:',tree)Мы также можем создать собственные PCFG. Нам просто нужно использовать функцию nltk.PCFG.fromstring() так же, как мы используем функцию nltk.CFG.fromstring(). Единственная разница в том, что на этот раз грамматики будут иметь определенную степень вероятности. Из этого следует, что изменение степени вероятности влияет на результат синтаксического анализа.
Анализ на основе грамматики зависимостей
Основная идея, лежащая в основе этой концепции, заключается в том, что в предложении обычно есть зависимые и самостоятельные элементы. Так, детерминативы и прилагательные, как правило, подчиняются существительным. Посмотрите, как эти зависимости проявляются в предложении JetBlue canceled our flight this morning which was already late (“JetBlue отменила наш утренний рейс, который уже задерживали”).
from nltk.grammar import DependencyGrammar
from nltk.parse import NonprojectiveDependencyParser
grammar = DependencyGrammar.fromstring("""
'canceled' -> 'JetBlue' | 'flight' | 'morning'
'flight' -> 'our' | 'was'
'morning' -> 'this'
'was' -> 'which' | 'late'
'late' -> 'already'
""")
# запуск анализатора
dp = NonprojectiveDependencyParser(grammar)
# анализ последовательности слов
g, = dp.parse(['JetBlue', 'canceled', 'our', 'flight', 'this', 'morning', 'which', 'was', 'already', 'late'])
# печать корневого элемента
print('Root: ', g.root['word'], '\n')
# обход дерева и данных, зависящих от печати
for _, node in sorted(g.nodes.items()):
if node['word'] is not None:
print('{address} {word}: {d}'.format(d=node['deps'][''],**node))
# печать дерева
print('\n Tree: \n',g.tree())Почему важен синтаксический анализ?
Задача синтаксического анализа — поиск правильного представления предложения в соответствии с его грамматикой. Поэтому синтаксический анализ можно использовать для обработки и передачи правильной структуры предложений.
Типичная NLP-задача — корректное определение частей речи в предложении. Это не всегда легко сделать, особенно в следующих примерах: “Печь была жарко натоплена” и “Мы любим печь пирожки”. Слово “печь” является существительным в первом предложении, однако во втором выступает глаголом.
Безошибочно расставить POS-теги позволяет синтаксический анализ. Вы можете выполнить анализ фразовой структуры или прибегнуть к анализу на основе грамматики зависимостей. Любой из этих инструментов поможет верно установить взаимосвязи между словами и точно определить части речи.
Читайте также:
- Обработка естественного языка в Python. Основы
- 10 бесплатных ресурсов для обучения обработке естественного языка
- Импорт в Python
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Mohammad Shafiqul Islam: Linguistic Modelling Techniques with Python





