
Я заканчиваю факультет компьютерных наук. Предложений по трудоустройству не получил. Хотел бы в течение месяца стать специалистом по обработке данных, не тратя деньги на дорогостоящие курсы. Не могли бы вы мне помочь?
Подобное желание изъявляют тысячи выпускников вузов. Им не хватает четкого ориентира в приобретении навыков, необходимых для того, чтобы стать специалистом по обработке данных. Наука о данных — очень популярная область, которая прельщает многих высокими доходами и возможностью работать на дому. Поэтому вышеописанные ожидания вполне понятны. Однако кто-то должен помочь вчерашнему выпускнику стать специалистом по обработке данных, причем незамедлительно. Имея за плечами более десяти лет академического и отраслевого опыта, я могу предложить быстрое решение, которое поможет всем претендентам достичь своей цели.
Для начала стоит выяснить, зачем нужен специалист по обработке данных и какие требования к нему предъявляют бизнесмены-работодатели. После этого поговорим о роли науки о данных в современном мире.
Потребность в специалистах по обработке данных
Главная вопрос любого бизнесмена — “Как мне развить свой бизнес?”. Вот как он рассуждает:
В прошлом у меня были тысячи и миллионы клиентов. Я собрал огромное количество данных об их покупках. Может ли кто-нибудь помочь мне понять их покупательские привычки, предпочтения, характер покупок? Это дало бы мне расширенную информацию о том, что они купят в следующий раз. Тогда я смогу управлять продуктовыми запасами и планировать рекламную деятельность.
Вот тут-то и нужен специалист по обработке данных. Попробуем понять, как он может помочь своему работодателю решить вышеуказанные бизнес-задачи.
Начнем с требований, которые предъявляются к работе этого специалиста.
Работа специалиста по обработке данных
Этот человек разрабатывает модель машинного обучения, обучает ее на данных, накопленных за прошлые годы, а затем использует для прогнозирования будущего. Звучит просто, не так ли? Да, это так просто.
Еще недавно многие представляли это как очень сложную задачу, требующую массу навыков. Скажите, чтобы водить машину, вам нужно изучать автомобильную инженерию? То же самое относится и к Data Science. Вам нужно лишь понять, как создается модель машинного обучения.
Как разрабатывается модель МО
Процесс разработки модели машинного обучения тривиален. Вот стандартные этапы разработки модели:
- Очистка данных.
- Предварительная обработка данных.
- Создание наборов данных для обучения/проверки.
- Выбор алгоритма.
- Обучение модели.
- Тестирование модели.
- Вывод на основе невидимых данных.
Эти этапы неизменны независимо от решаемой проблемы — будь то регрессия, классификация или кластеризация. Не зависят они и от типа обучения — контролируемого или неконтролируемого. Речь идет о классическом МО, которое за последние несколько лет доказало свои преимущества, о чем свидетельствуют многочисленные исследовательские проекты. Есть достижения и в других направлениях МО, таких как:
- нейронные сети;
- ГНС (глубинные нейросети);
- предварительно обученные модели;
- стимулированное обучение.
Сосредоточимся на классическом МО, открывающем массу возможностей для трудоустройства.
Если вы вникнете в перечисленные этапы МО, то легко поймете, что самый “напряжный” из них — выбор алгоритма. Остальные этапы выглядят как стандартные процедуры, каковыми и являются на самом деле. Код, написанный для этих этапов, будет оставаться неизменным для всех ваших моделей.
Наверняка вы думаете: “Вот бы раздобыть шаблон для разработки модели!” Однако это уже не проблема: к настоящему моменту вложено огромное количество ресурсов в создание шаблонов для сотен алгоритмов МО. Они представлены на рынке, разработанные и испытанные высококлассными специалистами по анализу данных. Вы можете повторно использовать эти шаблоны. Компания, которая их поставляет, — BlobCity (я, однако, ищу в Гугле и другие подобные сайты).
Краткий обзор BlobCity AI Cloud
BlobCity AI Cloud — это проект с открытым исходным кодом, который предоставляет 1000+ готовых шаблонов кода для алгоритмов машинного обучения, с высокой точностью распределенных по группам. Предоставляется бесплатный доступ к обучению и коммерческому использованию этих алгоритмов.
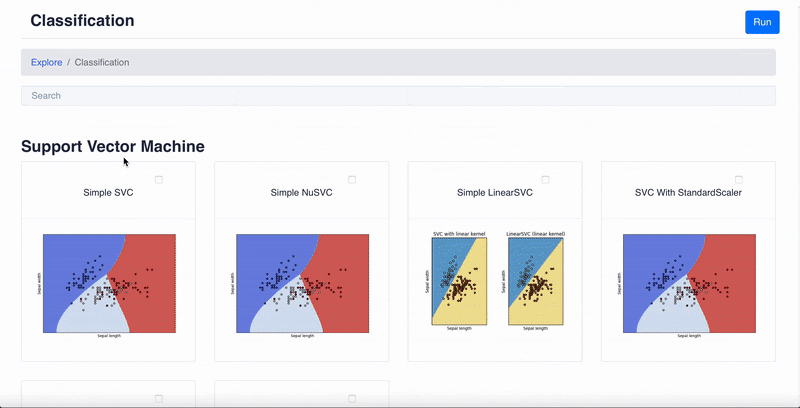
Все алгоритмы, как было сказано, распределены по различным группам. Допустим, вы хотите изучить работу алгоритмов классификации — выберите соответствующую группу. В ней вы найдете множество алгоритмов, включая:
- SVM (support vector machine — метод опорных векторов);
- дерево решений;
- kNN (k-nearest-neighbor — алгоритм получения К-ближайшего соседнего результата);
- наивный байесовский алгоритм.
Вам также предложат несколько вариаций каждого из этих алгоритмов. Чтобы воспользоваться шаблоном, просто подключите к нему свой набор данных, укажите характеристики и задачи и выполните все команды. Шаблон обучит модель на вашем наборе данных и предоставит вам результаты оценки. Все очень просто.
Вы можете изменять параметры предварительной обработки данных и модели, чтобы посмотреть, как они влияют на точность прогнозирования модели. Можете запустить любые другие алгоритмы, поставив им те же задачи, чтобы выяснить, какие алгоритмы работают эффективней с вашим набором данных. На сайте вы также найдете несколько Cloudbook’ов, по сути, Jupter-ноутбуков, созданных сообществом ИИ.
BlobCity выделил несколько групп по следующим направлениям:
- классификация;
- регрессия;
- кластеризация;
- EDA (estimation of distribution algorithms — оценка алгоритмов распределения);
- уменьшение размерности;
- анализ временных рядов;
- обработка естественного языка;
- аудиовизуальные эффекты.
Последняя, аудиовизуальная группа, позволяет разрабатывать модели машинного обучения на наборах данных изображений, видео и аудио. Осмелюсь заметить, что работа на этом сайте проведена колоссальная: охвачено большинство алгоритмов машинного обучения, созданных на этой планете, а также представлены все типы данных — двоичные, текстовые, изображения, аудио и видео.
На мой взгляд, BlobCity максимально упростил для всех новичков изучение сотен алгоритмов, предоставив в одном месте курируемые, технически проверенные шаблоны кода. Профессиональные исследователи данных, которые уже по опыту знают, какой алгоритм им следует использовать, могут просто применить нужный шаблон к своим наборам данных.
К слову, специалисты из BlobCity принимают участие в открытом исходном коде на Github.
Я не встречал ни одного другого сайта, предоставляющего более 1000 готовых шаблонов кода (по моим наблюдениям их количество растет — несколько дней назад их было 600) для алгоритмов машинного обучения.
Заключение
Чтобы быстро освоить навыки специалиста по обработке данных, сосредоточьтесь на сотнях алгоритмов, представленных на рынке. Посмотрите, как они работают с различными наборами данных и сравните результаты. Изучите влияние на их производительность методов предварительной обработки данных, таких как масштабирование, нормализация, выбор функций.
Как только вы изучите работу различных алгоритмов, подумайте об использовании передовых инструментов, например Auto, чтобы найти наиболее эффективный алгоритм.
Обратите внимание на то, что вам не нужно изучать реализации алгоритмов. Реализации, предоставляемые в scikit-learn и нескольких других библиотеках, выполняются высококвалифицированными разработчиками. Не воображайте, что вы справились бы с этой работой лучше, чем они. Просто доверяйте их реализациям и учитесь их использовать.
Такие компании, как BlobCity, предоставляют множество шаблонов кода, разработанных на основе этих реализаций, чтобы еще больше упростить вашу работу. Удачи вам в быстром освоении науки о данных!
Читайте также:
- ТОП-4 официальных сайта МО-библиотек и способы их использования
- Наука о данных простым языком
- Как предварительно обработать данные и текстовые сообщения из социальных сетей
Читайте нас в Telegram, VK и Дзен
Перевод статьи Poornachandra Sarang: Use These Tools to Learn Data Science Faster





