
Введение
Если хотите, можете пропустить вводную часть и переходить сразу к подробному разбору реализации.
Когда я только начинал работать с языком Go, то немного скептически относился к его синтаксису и уровню детализации. Однако через пару месяцев постепенно стал влюбляться в его простоту, удобство для восприятия человеком, превосходство в производительности и малый объем используемой памяти по сравнению с другими языками.
Особенный интерес к языку вызывали у меня широкие возможности его конкурентной модели. Но, несмотря на все это очарование первого времени знакомства с новым языком, у меня возникли кое-какие трудности с пониманием того, как эта модель работает.
Так как я не укладывался в сроки, то сразу перешел к примеру реализации шаблона вместо того, чтобы сначала освоить основы конкурентности. Это было ошибкой!
Поэтому настоятельно рекомендую начинать с изучения документации. Ведь то, что в Go конкурентное выполнение осуществляется с такой простотой, не означает, что программирование кода с конкурентным выполнением будет очень легким для понимания.
Тем не менее я очень постараюсь максимально упростить все, о чем здесь в статье пойдет речь. Кроме того, в статье приводится репозиторий на GitHub с реализацией этого шаблона и тестами для примера использования.
Подробный разбор реализации
Прежде чем идти дальше, стоит заметить, что в этой статье говорится не о концепциях конкурентности, а о том, как осуществляется в условиях конкурентности взаимодействие компонентов шаблона с целью конкурентного выполнения набора определенных задач.
На следующей схеме в обобщенном виде показан шаблон конкурентного выполнения Worker Pool. Более глубокое и подробное описание того, что на ней происходит, приведено ниже. (Ознакомьтесь также и с версией схемы большего размера здесь. Она сделана для лучшего понимания!).
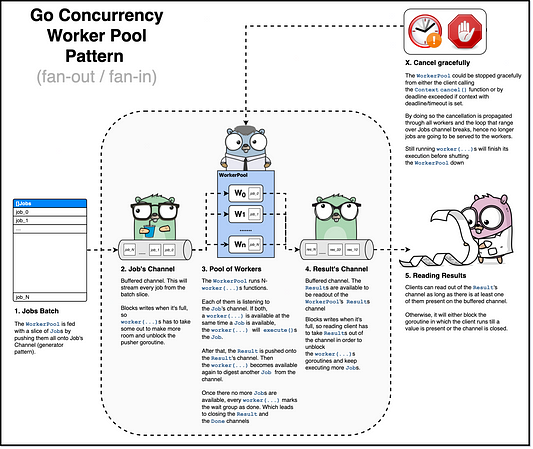
1. Пакет задач
Сначала создается минимальная рабочая единица Job, состоящая из ExecutionFn, которая позволила бы писать пользовательскую логику для Job, с тем чтобы возвращать Result. Последний — это либо value, либо error.
... [опущено для краткости]
type jobMetadata map[string]interface{}
type Job struct {
Descriptor JobDescriptor
ExecFn ExecutionFn
Args interface{}
}
func (j Job) execute(ctx context.Context) Result {
value, err := j.ExecFn(ctx, j.Args)
if err != nil {
return Result{
Err: err,
Descriptor: j.Descriptor,
}
}
return Result{
Value: value,
Descriptor: j.Descriptor,
}
}На втором этапе используется шаблон конкурентного выполнения generator для потоковой передачи всех рабочих единиц Job в пул рабочих процессов WorkerPool. Что здесь происходит? Создание потока из перебора по определенному клиентскому срезу рабочих единиц Job с добавлением каждой из них в соответствующий канал Job. Этот канал используется для одновременной передачи в WorkerPool.
... [опущено для краткости]
func (wp WorkerPool) GenerateFrom(jobsBulk []Job) {
for i, _ := range jobsBulk {
wp.jobs <- jobsBulk[i]
}
close(wp.jobs)
}2. Канал рабочих единиц «Job»
Это буферизованный канал, т. е. канал с ограниченным счетчиком рабочих процессов. Когда этот канал заполняется, при любой дальнейшей попытке записи происходит блокировка текущей горутины (в нашем случае это горутина генератора потока из первого этапа). В любой момент при наличии в канале какой-либо рабочей единицы Job она будет использована функцией Worker для последующего выполнения. Таким образом канал разблокируется для новых записей Job, поступающих от generator из предыдущего пункта.
3. Пул рабочих процессов «WorkerPool»
Это основная часть пазла, она состоит из результатов Result, рабочих единиц Job и канала Done, а также того количества рабочих процессов Worker, которые размещаются в пуле. Здесь в разных горутинах порождается столько рабочих процессов Worker, сколько указывает счетчик рабочих процессов. То есть происходит их веерообразное увеличение.
Сами рабочие процессы Worker забирают из канала рабочие единицы Job, когда те доступны. А затем выполняют эти Job и публикуют результат Result на канале Result. Рабочие процессы Worker делают все это до тех пор, пока в контексте Context не вызвана функция cancel(). В случае ее вызова цикл обрывается и WaitGroup помечается как Done(). Это очень похоже на то, что можно назвать уничтожением рабочего процесса Worker.
// ... [опущено для краткости]
func worker(ctx context.Context, wg *sync.WaitGroup, jobs <-chan Job, results chan<- Result) {
defer wg.Done()
for {
select {
case job, ok := <-jobs:
if !ok {
return
}
// выполнение рабочих единиц job с многократной передачей результатов в канал результатов results и уничтожением рабочих процессов
results <- job.execute(ctx)
case <-ctx.Done():
fmt.Printf("cancelled worker. Error detail: %v\n", ctx.Err())
results <- Result{
Err: ctx.Err(),
}
return
}
}
}После того, как рабочие процессы забирают из канала все доступные рабочие единицы Job, пул рабочих процессов WorkerPool завершает выполнение, закрывая свои каналы Done и Result.
... [опущено для краткости]
type WorkerPool struct {
workersCount int
jobs chan Job
results chan Result
Done chan struct{}
}
func New(wcount int) WorkerPool {
return WorkerPool{
workersCount: wcount,
jobs: make(chan Job, wcount),
results: make(chan Result, wcount),
Done: make(chan struct{}),
}
}
func (wp WorkerPool) Run(ctx context.Context) {
var wg sync.WaitGroup
for i := 0; i < wp.workersCount; i++ {
wg.Add(1)
// веерообразное увеличение горутин рабочих процессов
// чтение с канала рабочих единиц jobs и
// добавление подсчетов в канал результатов
go worker(ctx, &wg, wp.jobs, wp.results)
}
wg.Wait()
close(wp.Done)
close(wp.results)
}4. Канал результатов «Results»
Хотя рабочие процессы запускаются в разных горутинах, они публикуют результаты Result выполнения рабочих единиц Job, многократно передавая их в канал результатов Result. То есть происходит нечто обратное их веерообразному увеличению. Клиент пула рабочих процессов WorkerPool считывает этот источник, даже когда канал закрыт по любой из указанных выше причин.
5. Считывание результатов
Клиенты пула рабочих процессов WorkerPool считывают канал результатов Result, пока в буферизованном канале есть хотя бы один из них. В противном случае при считывании пустого канала Result происходит одно из двух: либо клиентская горутина блокируется (пока в канале не появится какое-нибудь значение), либо канал закрывается.
Цикл for обрывается, как только закрытый канал Done пула рабочих процессов WorkerPool возвращается и двигается дальше.
// ... [опущено для краткости]
func TestWorkerPool(t *testing.T) {
wp := New(workerCount)
ctx, cancel := context.WithCancel(context.TODO())
defer cancel()
go wp.GenerateFrom(testJobs())
go wp.Run(ctx)
for {
select {
case r, ok := <-wp.Results():
if !ok {
continue
}
i, err := strconv.ParseInt(string(r.Descriptor.ID), 10, 64)
if err != nil {
t.Fatalf("unexpected error: %v", err)
}
val := r.Value.(int)
if val != int(i)*2 {
t.Fatalf("wrong value %v; expected %v", val, int(i)*2)
}
case <-wp.Done:
return
default:
}
}
}X. Вызов «Cancel» для нормального завершения выполнения
В любом случае, когда клиенту необходимо нормально завершить выполнение WorkerPool, он либо вызывает функцию cancel() в данном контексте Context, либо настраивает продолжительность времени ожидания, определяемую с помощью метода Context.WithTimeout.
Какой бы из этих двух вариантов ни происходил, оба в итоге завершаются вызовом функции cancel(): один явно, а другой по истечении времени ожидания. А закрытый канал Done возвращается из контекста Context, который распространится на все функции Worker. Это приводит к тому, что цикл for select прерывается и рабочие процессы Worker прекращают использовать рабочие единицы Job из канала. После этого WaitGroup помечается как done (завершено). И тем не менее уже запущенные рабочие процессы завершат выполнение своих рабочих единиц до закрытия пула рабочих процессов WorkerPool.
Заключение
Благодаря использованию этого шаблона удается осуществлять конкурентное выполнение рабочих задач Job, делая его более эффективным и согласованным.
На первый взгляд шаблон может показаться сложным для понимания. Поэтому, пытаясь в нем разобраться, лучше не торопиться. Особенно тем, кто еще только знакомится с конкурентной моделью GoLang.
Облегчить понимание шаблона способен подход к каналам как трубам, по которым данные перетекают из стороны в сторону. Причем объем данных, которые эти трубы вмещают, ограничен. Поэтому при необходимости добавить больше данных нужно просто освободить для них дополнительное место. А для этого надо сначала какие-то данные от туда убрать и подождать. В то же время, чтобы использовать эти трубы, в них должно что-то быть. А если нет пока, то ждем, когда что-то появится. Так эти трубы используются для передачи и обмена данными через горутины.
Полная реализации для этого шаблона находится в репозитории на GitHub.
Спасибо за внимание, и надеюсь, что статья была вам полезной!😉
Читайте также:
- Обработка сигналов в операционных системах семейства Unix на Golang
- Реализация интерфейсов в Golang
- Бенчмарки в Golang: тестируем производительность кода
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Lucas Godoy: Explain to me Go Concurrency Worker Pool Pattern like I’m five





