
Специалисту в области науки о данных приходится анализировать данные в любой форме, ведь они хранятся как в специальных SQL-базах, вроде PostgreSQL и MySQL, так и в старой доброй электронной таблице Microsoft Excel. Более того, иногда данные сохранены в нетрадиционном формате, например в PDF.
В этой статье вы узнаете, как скрейпить данные из файлов PDF и оформлять их подходящим для применения в Data Science образом с помощью специальных библиотек языка программирования Python.
Оглавление:
- Подготовка.
- Сохранение структуры данных при скрейпинге из PDF.
- Скрейпинг неструктурированных данных из PDF.
1. Выгрузка данных из файла PDF в объект Pandas.
2. Cоздание идентификаторов для отдельных записей.
3. Преобразование таблицы из длинной формы в широкую с помощью Pandas.
4. Объединение данных в единую финальную таблицу. - Выводы.
Подготовка
Ознакомьтесь со списком необходимых для выполнения руководства Python-библиотек.
- tabula-py: для скрейпинга текста из файлов PDF.
- re: для извлечения сугубо нужных данных с помощью регулярных выражений.
- pandas: для удобной работы с данными.
С помощью стандартного менеджера пакетов pip или любого другого установите две библиотеки из списка:
pip install tabula-py
pip install pandasСоздайте файл программы-скрейпера и импортируйте в него функционал библиотек для скрейпинга:
import tabula as tb
import pandas as pd
import reСохранение структуры данных при скрейпинге из PDF
Прежде всего, обсудим скрейпинг данных из файла PDF в изначально структурированном формате. В следующем примере показан скрейпинг таблицы: это хорошо структурированные данные, в них чётко определены строки и столбцы.
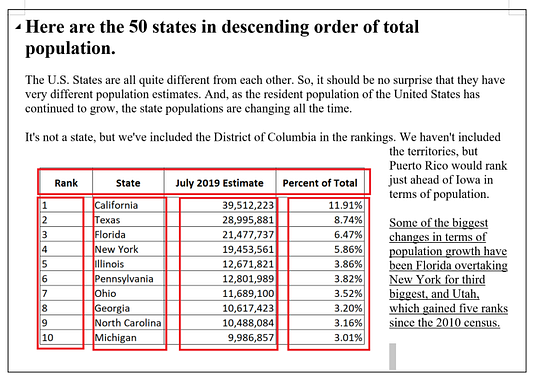
Если воспользоваться библиотекой tabula-py, то скрейппинг PDF-данных в структурированном виде упростится в разы. Просто введите в программу расположение табличных данных на PDF-странице, указав верхнюю правую, верхнюю левую, нижнюю правую и нижнюю левую координаты области. Если на странице только одна целевая таблица, то даже не нужно указывать координатами область скрейпинга. Более того, библиотека tabula-py в большинстве случаев определяет строки и столбцы автоматически.
file = 'state_population.pdf'
data = tb.read_pdf(file, area = (300, 0, 600, 800), pages = '1')Скрейпинг неструктурированных данных из PDF
Во второй части руководства обсудим задачу поинтереснее — получение текста из PDF-файла в неструктурированном формате.
Для успешного статистического анализа, визуализации данных и создания моделей машинного обучения просто необходимы “панельные данные” (“лонгитюдные данные”), то есть данные социальных исследований в табличной форме. Однако в 2021-м году многие необходимые для анализа данные доступны только в неструктурированном виде.
Например, сотрудники отдела кадров, скорее всего, хранят исторические данные о заработной плате не в табличной форме. На следующем скриншоте приводятся в пример как раз такие данные о заработной плате со смешанной структурой: в левой части находится информация об имени сотрудника, чистой сумме выплаты, дате выплаты и оплаченном времени, а в правой — о категории выплаты (PAY), ставке в час (RATE), количестве часов работы (HRS) и фактической сумме выплаты (AMT).
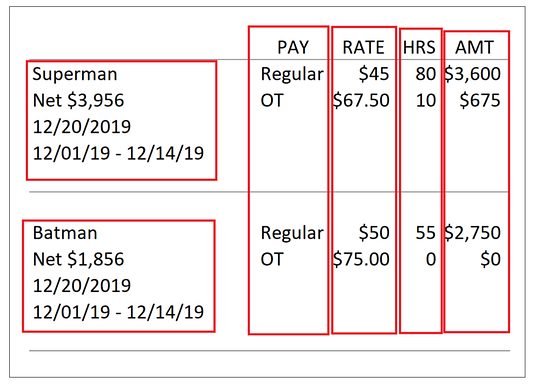
Для преобразования данных в лонгитюдный (табличный, панельный) формат необходимо выполнить несколько шагов.
- Шаг 1: выгрузка данных из файла PDF в объект Pandas.
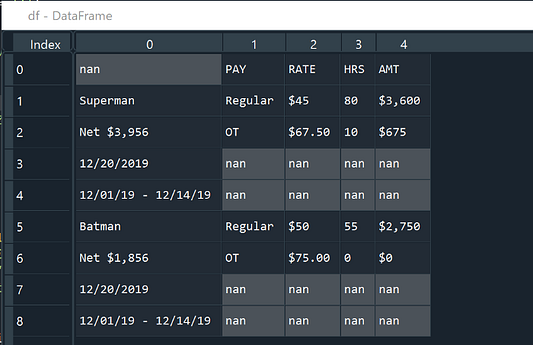
Подобно примеру со структурированными данными, в самом начале скрейпинга воспользуемся методом tb.read_pdf() для импорта неструктурированных, но на этот раз для правильного импорта потребуется вручную указать дополнительные параметры.
file = 'payroll_sample.pdf'
df = tb.read_pdf(file, pages='1', area=(0, 0, 1000, 1000), columns=[200, 265, 300, 320], pandas_options={'header': None}, stream=True)[0]- Параметры
areaиcolumns
В первой части руководства упоминалось определение области для скрейпинга с помощью координат. Теперь нам в любом случае потребуется вручную указать columns, чтобы определить местоположение всех необходимых для анализа колонок (одна колонка на левой секции и четыре колонки на правой секции).
- Параметры
streamиlattice
Когда в PDF-файле все ячейки таблицы разделены линиями сетки, стоит указать параметр lattice = True для автоматического определения каждой ячейки в таблице. Если же никакой сетки нет, то стоит указать параметр stream = True вместе с параметром columns для определения каждой ячейки вручную.
lattice(bool, необязательный параметр) — принудительное извлечение данных из PDF в “решетчатом” режиме. Применяется, когда каждую ячейку таблицы разделяют линейки, как в PDF из Microsoft Excel).stream(bool, необязательный параметр) — принудительное извлечение данных из PDF в “потоковом” режиме. Применяется, когда нет сетки, разделяющей ячейки в таблице.
- Шаг 2: создание идентификаторов для отдельных записей.
После выполнения предыдущего шага некоторые данные для работы уже получены. Теперь мы воспользуемся библиотекой Python Pandas для манипулирования табличными данными, хранящимися в экземпляре класса pandas.DataFrame — это такой специальный “контейнер-таблица” в идеальном для аналитики данных формате.
Для начала создаем столбец, чтобы разместить в нем новые ячейки с идентификаторами записей о сотрудниках. Легко заметить, что имя сотрудника из примера данных (Супермен и Бэтмен) стоит учитывать при определении границы между записью о Супермене и записью о Бэтмене. Каждое имя сотрудника уникально отформатировано: начинается с заглавной буквы и заканчивается строчной. В таком случае для идентификации по имени сотрудника как раз подойдёт регулярное выражение ‘^[A-Z].*[a-z]$’. После поиска регулярным выражением достаточно применить Pandas-функцию cumsum (кумулятивная сумма), а идентификаторы для записей создадутся сами.
df['border'] = df.apply(lambda x: 1 if re.findall('^[A-Z].*[a-z]$', str(x[0])) else 0, axis = 1)
df['row'] = df['border'].transform('cumsum')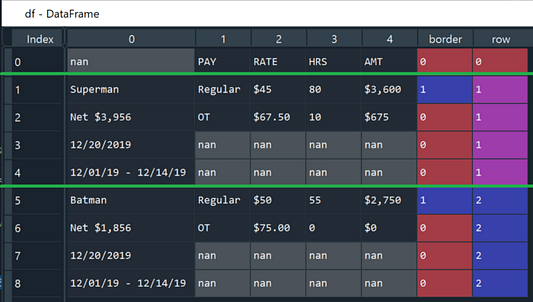
- Шаг 3: преобразование таблицы из длинной формы в широкую с помощью Pandas.
Начнём с определения терминов “длинные данные” (“long data”) и “широкие данные” (“wide data”).
- Таблица, хранящаяся в “длинной” форме, содержит по одному столбцу для каждой переменной в системе.
- Таблица, хранящаяся в “широкой” форме, распределяет данные о переменной по нескольким столбцам.
Теперь постараемся изменить форму данных в левой и правой секциях таблицы из примера выше.
- Для левой секции таблицы создаем новый
pandas.DataFrameпод названием “employee” (сотрудник), состоящий из столбцовemployee_name(имя сотрудника),net_amount(чистая сумма выплаты),pay_date(дата выплаты) иpay_period(оплаченный период). - Для правой секции таблицы тоже создаем отдельный
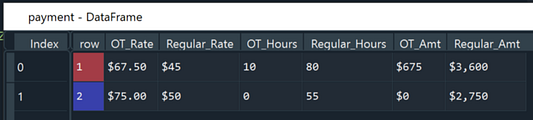
pandas.DataFrameпод названием “payment”, состоящий из столбцовOT_Rate(ставка в час при категории “OT”),Regular_Rate(ставка в час при категории “Regular”),OT_Hours(количество часов работы категории “OT”),Regular_Hours(количество часов работы категории “Regular”),OT_Amt(фактическая сумма выплаты категории “OT”) иRegular_Amt(фактическая сумма выплаты категории “Regular”).
Преобразовать данные в широкую форму нам поможет функция из библиотеки Pandas под названием pivot.
# изменение формы левой секции таблицы
employee = df[[0, 'row']]
employee = employee[employee[0].notnull()]
employee['index'] = employee.groupby('row').cumcount()+1
employee = employee.pivot(index = ['row'], columns = ['index'], values = 0).reset_index()
employee = employee.rename(columns = {1: 'employee_name', 2: 'net_amount', 3: 'pay_date', 4: 'pay_period'})
employee['net_amount'] = employee.apply(lambda x: x['net_amount'].replace('Net', '').strip(), axis = 1)
# изменение формы правой секции таблицы
payment = df[[1, 2, 3, 4, 'row']]
payment = payment[payment[1].notnull()]
payment = payment[payment['row']!=0]
payment = payment.pivot(index = ['row'], columns = 1, values = [2, 3, 4]).reset_index()
payment.columns = [str(col[0])+col[1] for col in payment.columns.values]
for i in ['Regular', 'OT']:
payment = payment.rename(columns = {f'2{i}': f'{i}_Rate', f'3{i}': f'{i}_Hours', f'4{i}': f'{i}_Amt'})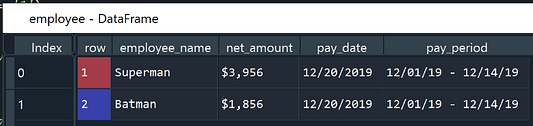
- Шаг 4: объединение данных в единую финальную таблицу.
Наконец, на основе идентификаторов строк с помощью функции merge() объединим два pandas.DataFrame — employee и payment — в единую таблицу данных о сотрудниках и платежах.
df_clean = employee.merge(payment, on = ['row'], how = 'inner')

Выводы
В 2021-м году сотрудники многих компаний все еще вручную обрабатывают данные из фалов формата PDF. Сегодня мы показали, как при помощи Python-библиотек tabula-py и Pandas сэкономить время и деньги, автоматизировав не только извлечение данных из файлов PDF, но и преобразование неструктурированных данных в панельные.
Примечание: перед любым скрейпингом внимательно изучите юридические условия и положения о распространении информации, опубликованные автором данных.
Читайте также:
- Как вычислить миллионное число Фибоначчи на Python
- 3 важных рекомендации Django-программистам
- Топ-15 лайфхаков для работы с Python
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Aaron Zhu: Scrape Data from PDF Files Using Python
 в Compose Material 3")




