
Практический пример машинного обучения
До сих по еще не было более удачного времени для машинного обучения. Благодаря доступным учебным онлайн ресурсам в Интернет, бесплатные инструменты с открытым исходным кодом, реализующие любые алгоритмы, который только можно себе вообразить, доступные и дешевые вычислительные мощности — доступные через облачные сервисы, такие как AWS, машинное обучение стало областью, демократизированной благодаря Интернету. Если есть ноутбук и желание учиться, можно легко опробовать любые современные алгоритмы за считанные минуты. Уже через весьма короткое время вы сможете разрабатывать практические модели, которые помогут вам в повседневной жизни или на работе (или даже перейти работать в сферу машинного обучения и начать зарабатывать деньги). В данной статье мы продемонстрируем вам полную реализацию модели машинного обучения на основе Random forest ‑ комитета регрессионных деревьев принятия решений. Этот метод призван служить практическим дополнением описанной концепции Random forest, однако этот материал можно читать и самостоятельно, при наличии представлений о самой идее дерева решений и Random forest. В дополнительной статье также подробно описывается, как можно улучшить предложенную здесь модель.
Конечно, здесь будет приводиться код на Python, однако досконального знания этого языка не потребуется, язык использован для демонстрации доступности машинного обучения с помощью распространенных сегодня ресурсов! Полный проект доступен на GitHub, а файл данных и Jupyter Notebook можно также загрузить с Google-диска. Все, что потребуется – ноутбук с установленным Python, запуск Jupyter Notebook, что позволит следовать за нашим дальнейшим описанием. (Для установки Python и запуска ноутбука Jupyter ознакомьтесь с руководством). Здесь будет несколько важных тем для понимания машинного обучения, но я постараюсь сделать их ясными и указать дополнительные ресурсы для более подробного изучения всеми заинтересовавшимися.

Введение в проблему
Будем заниматься задачей прогноза максимальной температуры на следующий день в городе на основе метеорологических данных за прошлый год. Поскольку я живу в Сиэтле, штат Вашингтон, то можете смело взять данные для своего города с помощью NOAA Climate Data Online. Будем действовать, как будто бы у нас нет доступа к прогнозам погоды (да и вообще, интереснее делать собственные прогнозы, а не полагаться на чужие). У нас имеются данные за год с максимальными значениями температур, значения температуры за два прошедших дня и оценки друга, который уверен, что знает о погоде все. Такая задача называется контролируемой регрессионной задачей машинного обучения. Она контролируемая, поскольку имеются как функции (данные для города), так и переменные (температура), для которых мы хотим построить прогноз. В процессе обучения мы подаем Random forest и с характеристиками, и с целями, нейронная сеть должна научиться сопоставлять данные с прогнозом. Это регрессионная задача, поскольку целевое значение непрерывна(в отличие от дискретных классов классификации). Этого достаточно, поэтому давайте приступим!
План действий
Прежде чем погрузиться в программирование, мы должны краткое руководство, чтобы понимать, куда мы движемся. Нижеследующие шаги описывают основу процесса машинного обучения в том случае, когда у есть задача и модель:
- Поставить вопрос и определить требуемые данные
- Получить данные в доступном формате
- Доопределить / исправить отсутствующие точки данных / аномальные значения при необходимости
- Подготовить данные для модели машинного обучения
- Установите базовую модель
- Обучить модель на тренировочных данных
- Получить прогнозы по тренировочным данным
- Сравните прогнозы с известными целевыми наборами тестов и рассчитать коэффициент производительности
- Если производительность не удовлетворительна, отрегулировать модель, использовать больше данных или попробовать использовать другую технику моделирования
- Интерпретировать модель и представить результаты в визуальной и численной форме
Шаг 1 уже выполнен! Остался вопрос: «сможем ли мы предсказать максимальную температуру в городе завтра?» и помним, что нам, известны максимальные значения температуры за последний год в Сиэтле, штат Вашингтон.
Обработка данных
Во-первых, нам нужны некоторые данные. Чтобы пример был реален, я собрал данные о погоде для Сиэттла за 2016 год с помощью NOAA Climate Data Online. Как правило, около 80% времени, затрачиваемого на анализ данных, ‑ это сбор и очистка первичных данных, однако время на эти процедуры можно сократить с помощью использования высококачественных источников данных. Инструмент NOAA на удивление прост в использовании, и данные о температуре могут быть загружены в виде уже очищенных файлов csv, которые могут обрабатываться на таких языках, как Python или R. Полный файл данных доступен для загрузки всем, кто захочет повторить наши действия.
Следующий код Python загружает данные csv и отображает структуру данных:
# Pandas is used for data manipulation
import pandas as pd
# Read in data and display first 5 rows
features = pd.read_csv('temps.csv')
features.head(5)
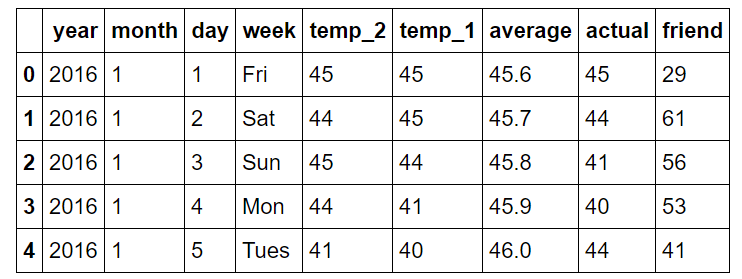
Информация выдается в виде чистых данных, причем каждая получаемая строка содержит одно наблюдение с переменными значениями в столбцах.
Ниже приведены комментарии для столбцов:
год: 2016 для всех точек данных
месяц: число за месяц года
день: число за день года
неделя: день недели в виде символьной строки
temp_2: максимальная температура за 2 предыдущих дня
temp_1: максимальная температура за 1 предыдущий день
среднее: историческая средняя температура
фактическое: максимальная измеренная температура
друг: прогноз нашего друга – случайное число в диапазоне 20 градусов ниже средней 20 градусами выше средней температур
Определение аномальных значений / потеря данных
Если посмотреть на размерность данных, то можно заметить, что имеется только 348 строк, что не соответствует 366 дням в 2016 году. Просматривая данные из NOAA, я заметил несколько недостающих дней – это отличный пример того, что собранные реальные данные никогда не бывают идеальными. Отсутствующие данные, неверные данные или резкие отклонения в значениях могут повлиять на анализ. В нашем случае недостающие данные не окажут существенного влияния благодаря высокому качеству данных, взятых из надежного источника. Также можно заметить, что у нас имеется девять столбцов, представляющих собой восемь функций и одну цель («фактическую»).
print('The shape of our features is:', features.shape)
The shape of our features is: (348, 9)
Чтобы определить, имеются ли аномальные значения, проведем сводные статистические расчеты.
# Descriptive statistics for each column features.describe()
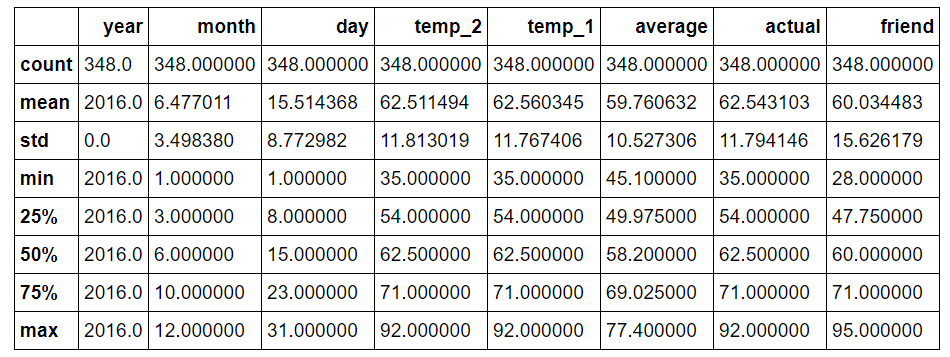
У нас не нашлось такие точек, которые сразу проявили себя как аномальные, также отсутствуют столбцы с нулевыми значениями результатов измерений. Другим методом проверки качества данных являются основные графики. Часто легче заметить аномалии на графике, чем в цифрах. Я оставил здесь фактический код, потому что построение на Python не наглядно, но я советую вам самим попробовать на компьютере полную реализацию (например, как и любой хороший специалист по обработке и анализу данных, я довольно часто строю графики с помощью код из Stack Overflow).
Только самостоятельно просматривая количественную статистику и графики, мы можем быть уверены в высоком качестве данных. Поскольку отсутствуют провалы в данных, несколько недостающих значений не окажут заметного влияния на анализ.
Подготовка данных
К сожалению, мы пока еще не дошли до того момента, когда можно просто загрузить данные в модель и получить ответ (хотя над этим ведется работа)! Нам предстоит сделать небольшую модификацию, чтобы наши данные стали понятны машине. Будем использовать Python-библиотеку Pandas для обработки данных, основываясь на известную структуру dataframe, которая по-сути представляет собой таблицу Excel из строк и столбцов.
Шаги, требующиеся для подготовки данных, зависят от используемой модели и собранных исходных данных, однако для любого прикладного машинного обучения всегда требуется некоторое количество манипуляций над данными.
Прямое кодирование
Первый наш шаг известен как прямое кодирование данных. Этот процесс принимает категориальные переменные (categorical variables) – дни недели, и преобразует их в числовое представление без произвольного упорядочения. Сокращенные названия дней недели для нас интуитивно. Наверняка, вы не найдете человека, не знающего, что «Пн» относится к первому дню рабочей недели, но машины не имеют интуитивных знаний. Компьютеры знают только цифры, и именно числа мы должны предоставить для машинного обучения. Можно было бы просто занумеровать дни недели числами с 1 по 7, но тогда алгоритм может придать большую важность значениям, приходящимся воскресенья, поскольку оно обозначено числом большей величины. Поэтому представим столбцы будних дней семью столбцами двоичных чисел. Это лучше проиллюстрировать наглядно. Прямое кодирование принимает следующий вид:
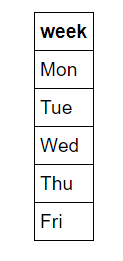
и принимает вид:
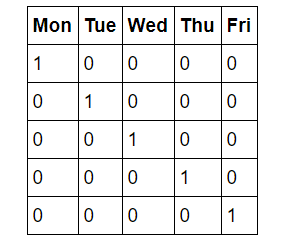
Итак, если точкой данных является среда, в столбце среды будет стоять единица и нуль – во всех остальных столбцах. Этот процесс можно реализовать в pandas одной строкой!
# One-hot encode the data using pandas get_dummies features = pd.get_dummies(features) # Display the first 5 rows of the last 12 columns features.iloc[:,5:].head(5)
Зафиксированные данные после прямого кодирования:

Форма наших данных теперь составляет 349 x 15, а все столбцы – это числа, что отлично подходит для алгоритма!
Возможности, цели и преобразование данных в массивы
Теперь нужно разделить данные на функции и цели. Цель, также называемая меткой, есть прогнозируемое значение, в нашем случае – фактическая максимальная температура, а функции – это все столбцы, используемые моделью для прогнозирования. Мы также преобразуем числовые дэйтафреймы Pandas в массивы Numpy, согласно работе алгоритма. (Я сохраняю заголовки столбцов, которые являются именами функций, списку, который будет использоваться для последующей визуализации).
# Use numpy to convert to arrays
import numpy as np
# Labels are the values we want to predict
labels = np.array(features['actual'])
# Remove the labels from the features
# axis 1 refers to the columns
features= features.drop('actual', axis = 1)
# Saving feature names for later use
feature_list = list(features.columns)
# Convert to numpy array
features = np.array(features)
Наборы данных для обучения и проверки
Теперь приступим к завершающему этапу подготовки исходных данных: разделение данных на обучающие и тестовые наборы. Во время обучения мы позволяем модели «видеть» ответы, в нашем случае – фактическую температуру, чтобы она могла узнать, как предсказать температуру на основе функций. Предполагаем, что имеется некоторая взаимосвязь между всеми функциями и целевым значением, и задача модели – изучить эти соотношения в процессе обучения. Затем, когда наступает момент оценки модели, мы просим ее сделать прогноз на тестовом наборе данных, в этом случае предоставлен доступ только к функциям (но не к ответам!). Поскольку у нас есть ответы для набора тестов, мы можем сравнить полученные прогнозы с истинными значениями, чтобы оценить точность модели. Как правило, при обучении модели мы произвольно разбиваем данные на обучающие и тестовые наборы, чтобы получить представление всех точек данных (например, если мы обучали модель на данных первых девяти месяцев года, а затем использовали данные последних трех месяцев для прогнозирования, то наш алгоритм не сможет хорошо сработать, потому что он не обучался на данных последних трех месяцев). Я установил случайное значение равным 42, что означает, что результаты будут одинаковыми при каждом запуске разбиения для получения воспроизводимых результатов.
Нижеследующий код разбивает набор данных в еще одну строку:
# Using Skicit-learn to split data into training and testing sets from sklearn.model_selection import train_test_split # Split the data into training and testing sets train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size = 0.25, random_state = 42)
Можем посмотреть на форму всех данных, чтобы убедиться, что все сделано правильно. Мы ожидаем, что количество функций обучения будет соответствовать количеству столбцов и количеству строк для соответствующих функций обучения, тестирования и меток:
print('Training Features Shape:', train_features.shape)
print('Training Labels Shape:', train_labels.shape)
print('Testing Features Shape:', test_features.shape)
print('Testing Labels Shape:', test_labels.shape)
Training Features Shape: (261, 14)
Training Labels Shape: (261,)
Testing Features Shape: (87, 14)
Testing Labels Shape: (87,)
Пока все в порядке! Напомним, чтобы получить данные в форме, приемлемой для машинного обучения, мы:
- Записали категориальные переменные в прямой кодировке
- Разбили данные на функции и метки
- Преобразовали их в формат массива
- Разделили данные на обучающие и тестовые наборы
В зависимости от исходного набора данных может потребоваться дополнительная работа, как-то удаление выбросов, внесение недостающих значений или преобразование временных переменных в циклические представления. Сначала эти шаги могут показаться случайными, но как только вы освоите базовый рабочий процесс, окажется, что он, главным образом, одинаков для любой задачи машинного обучения. Это относится и к процессу получения данных, пригодных для восприятия человеком, а затем и переводу в форму, понятную модели машинного обучения.
Организация основных данных
Прежде чем мы сможем получить и оценить прогнозы, необходимо установить базовый уровень, разумную меру, которую мы надеемся превзойти с помощью нашей модели. Если модель не сможет превзойти базовый уровень, будем рассматривать это как неудачную попытку, тогда придется попробовать другую модель или же признать, что машинное обучение не подходит для решения нашей задачи. Базовый прогноз для нашего случая может быть историческим максимальным средним значением температуры. Другими словами, наша базовая линия – это ошибка, которую мы получили бы, если бы просто прогнозировали среднюю максимальную температуру на все дни.
# The baseline predictions are the historical averages
baseline_preds = test_features[:, feature_list.index('average')]
# Baseline errors, and display average baseline error
baseline_errors = abs(baseline_preds - test_labels)
print('Average baseline error: ', round(np.mean(baseline_errors), 2))
Average baseline error: 5.06 degrees.
У теперь у нас есть цель! Если не сможем превзойти среднюю ошибку в 5 градусов, то придется пересмотреть подход в целом.
Тренировка модели
После проведения работы по подготовке данных, создание и обучение модели довольно просто осуществить с помощью Scikit-learn. Импортируем модель случайного регрессионного леса из skicit-learn, создаем экземпляр модели и тренируем (имя scikit-learn для обучения) модель на наборе данных для обучения. (Снова устанавливаем случайное состояние для воспроизводимых результатов). Процесс описывается тремя строками в scikit-learn!
# Import the model we are using from sklearn.ensemble import RandomForestRegressor # Instantiate model with 1000 decision trees rf = RandomForestRegressor(n_estimators = 1000, random_state = 42) # Train the model on training data rf.fit(train_features, train_labels);
Получение прогнозов на тестовом наборе
Пока наша модель обучилась поиску соотношений между функциями и целями. Следующий шаг – выяснить, насколько точна модель! Для этого сделаем прогнозы по тестовым функциям (модели запрещено видеть тестовые ответы). Затем сопоставим прогнозы с известными ответами. При выполнении регрессии мы должны убедиться, что используем абсолютную ошибку, потому что ожидаем, что некоторые наши ответы будут низкими, а некоторые – высокими. Нас интересует, как далек наш средний прогноз от фактического значения, поэтому берем абсолютное значение (как это делали и при составлении базовой линии).
Выполнение прогнозов с использованием модели – это еще одна однострочная команда в Skicit-learn.
# Use the forest's predict method on the test data
predictions = rf.predict(test_features)
# Calculate the absolute errors
errors = abs(predictions - test_labels)
# Print out the mean absolute error (mae)
print('Mean Absolute Error:', round(np.mean(errors), 2), 'degrees.')
Mean Absolute Error: 3.83 degrees.
Наша средняя оценка отклоняется на 3,83 градуса. Это в среднем на один градус больше по сравнению с исходным уровнем. Хотя это может показаться незначительным, но это на 25% лучше базового уровня, который, в зависимости от области и проблемы, может представлять собой, например, для крупной компании миллионы долларов.
Определение показателей эффективности
Чтобы представить наши прогнозы в перспективе, можем вычислить точность, используя среднюю относительную погрешность, выраженную в процентах, вычитаемую из 100%.
# Calculate mean absolute percentage error (MAPE)
mape = 100 * (errors / test_labels)
# Calculate and display accuracy
accuracy = 100 - np.mean(mape)
print('Accuracy:', round(accuracy, 2), '%.')
Accuracy: 93.99 %.
Выглядит неплохо! Наша модель научилась прогнозировать максимальную температуру в Сиэтле на следующий день с точностью в 94%.
Улучшение модели (при необходимости)
Сегодня процесс машинного обучения может осуществляться с помощью подстройки гиперпараметров. По-сути, это означает «подстройка параметров для повышения производительности» (настройки называются гиперпараметрами, чтобы отличать их от параметров модели, полученных во время обучения). Самый распространенный способ выполнения такой настройки — создать совокупность моделей с разными настройками, оценить их на одном наборе данных и посмотреть, какая из них подходит лучше всего. Конечно, делать это вручную – довольно утомительно, поэтому лучше воспользоваться автоматизированными методами из Skicit-learn. Для настройки гиперпараметров (Hyperparameter) часто нужно скорее проявить изобретательность, а не опираться на теоретические знания, а еще я все-таки рекомендую заглянуть в документацию! Точность 94% удовлетворительна для рассмотренной задачи, но учтите, что обычно первая построенная модель почти никогда не бывает самой эффективной моделью.
Интерпретация модели и отчет о результатах
Сейчас уже известно, что модель качественная, но все же она в значительной степени — черный ящик. Введем некоторые массивы Numpy для обучения, просим сделать прогнозы, оценить прогнозы и убедиться, что они разумны. Возникает вопрос: как эта модель получает результат? Есть два подхода, позволяющих заглянуть под капот Random forest: во-первых, можем посмотреть на одно дерево в лесу, а во-вторых, можем посмотреть на особенности, связанные с нашими объяснительными переменными.
Визуализация отдельного дерева решений
Одна из самых классных реализаций Random forest в Skicit-learn из общего числа возможных реализаций – можно изучить любые деревья в лесу. Мы выберем одно дерево и сохраним его как образ.
Следующий код берет одно дерево из леса и сохраняет его как изображение.
# Import tools needed for visualization
from sklearn.tree import export_graphviz
import pydot
# Pull out one tree from the forest
tree = rf.estimators_[5]
# Import tools needed for visualization
from sklearn.tree import export_graphviz
import pydot
# Pull out one tree from the forest
tree = rf.estimators_[5]
# Export the image to a dot file
export_graphviz(tree, out_file = 'tree.dot', feature_names = feature_list, rounded = True, precision = 1)
# Use dot file to create a graph
(graph, ) = pydot.graph_from_dot_file('tree.dot')
# Write graph to a png file
graph.write_png('tree.png')
Давайте посмотрим:
Вау! Это выглядит как широкое дерево с 15 слоями (на самом деле это еще достаточно маленькое дерево по сравнению с теми, что доводилось видеть мне). Можете самостоятельно скачать это изображение и изучить его подробнее, но чтобы упростить задачу, я ограничу глубину деревьев в лесу, для создания читаемого изображения.
# Limit depth of tree to 3 levels
rf_small = RandomForestRegressor(n_estimators=10, max_depth = 3)
rf_small.fit(train_features, train_labels)
# Extract the small tree
tree_small = rf_small.estimators_[5]
# Save the tree as a png image
export_graphviz(tree_small, out_file = 'small_tree.dot', feature_names = feature_list, rounded = True, precision = 1)
(graph, ) = pydot.graph_from_dot_file('small_tree.dot')
graph.write_png('small_tree.png');
Вот дерево уменьшенных размеров, аннотированное метками:
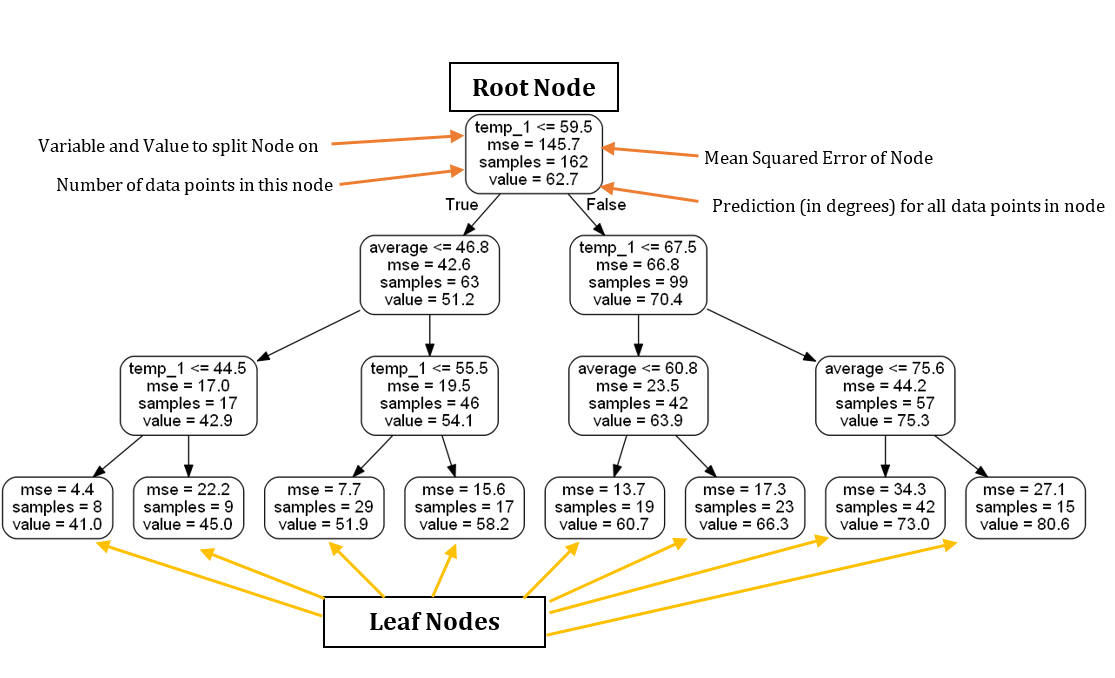 Основываясь исключительно на этом дереве, можем сделать прогноз для любой новой точки данных. Возьмем, например, прогнозы для среды, 27 декабря 2017 года. Переменными (фактическими) являются: temp_2 = 39, temp_1 = 35, average = 44 и friend = 30. Мы начинаем с корневого узла, и первый ответ True, потому что temp_1 ≤ 59.5. Двигаемся влево и сталкиваемся со вторым вопросом, который также является True как средний ≤ 46.8. Переместитесь вниз налево и на третий и последний вопрос, который также является True, потому что temp_1 ≤ 44.5. Поэтому мы заключаем, что наша оценка максимальной температуры составляет 41,0 градуса, что указано значением в листовом узле. Интересное наблюдение заключается в том, что в корневом узле имеется только 162 выборок, несмотря на 261 точку данных для обучения. Это объясняется тем, что каждое дерево в лесу обучается на случайном подмножестве точек данных с заменой (называемый упаковкой, сокращенной до инициализации программного обеспечения). (Можем отключить выборку с заменой и использовать все точки данных, установив bootstrap = False при создании леса). Случайная выборка точек данных в сочетании со случайной выборкой подмножества признаков в каждом узле дерева объясняет, почему модель называется «случайным» лесом.
Основываясь исключительно на этом дереве, можем сделать прогноз для любой новой точки данных. Возьмем, например, прогнозы для среды, 27 декабря 2017 года. Переменными (фактическими) являются: temp_2 = 39, temp_1 = 35, average = 44 и friend = 30. Мы начинаем с корневого узла, и первый ответ True, потому что temp_1 ≤ 59.5. Двигаемся влево и сталкиваемся со вторым вопросом, который также является True как средний ≤ 46.8. Переместитесь вниз налево и на третий и последний вопрос, который также является True, потому что temp_1 ≤ 44.5. Поэтому мы заключаем, что наша оценка максимальной температуры составляет 41,0 градуса, что указано значением в листовом узле. Интересное наблюдение заключается в том, что в корневом узле имеется только 162 выборок, несмотря на 261 точку данных для обучения. Это объясняется тем, что каждое дерево в лесу обучается на случайном подмножестве точек данных с заменой (называемый упаковкой, сокращенной до инициализации программного обеспечения). (Можем отключить выборку с заменой и использовать все точки данных, установив bootstrap = False при создании леса). Случайная выборка точек данных в сочетании со случайной выборкой подмножества признаков в каждом узле дерева объясняет, почему модель называется «случайным» лесом.
Кроме того, обратите внимание, что в нашем дереве только две переменных, которые мы использовали для получения прогноза! Согласно данному конкретному дереву принятия решений, остальные функции не важны для получения прогноза. Месяц года, день месяца и прогноз нашего друга совершенно бесполезны для прогнозирования максимальной температуры на завтра! Единственной важной информацией согласно нашему простому дереву является температура за предыдущий день и среднее значение за имеющийся период. Визуализация дерева увеличила наши знания о задаче, и теперь мы знаем, какие данные нужно искать, если попросят сделать прогноз повторно!
Значение переменных
Чтобы количественно оценить полезность всех переменных Random forest в целом, можем рассмотреть относительные значения переменных. Значения, возвращаемые в Scikit-learn, показывают, насколько включение определенной переменной может улучшить прогноз. Фактический расчет важности выходит за рамки этой статьи, но мы можем осуществить относительные сравнения между переменными на конкретных численных значениях.
В этом коде используется ряд трюков на языке Python, а именно: полный список, zip, сортировка и распаковка аргументов. Не столь важно, понятно ли вам все перечисленное в данный момент, но если вы хотите стать опытным Python-программистом, это те инструменты, которые вы должны иметь в своем арсенале!
# Get numerical feature importances
importances = list(rf.feature_importances_)
# List of tuples with variable and importance
feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)]
# Sort the feature importances by most important first
feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True)
# Print out the feature and importances
[print('Variable: {:20} Importance: {}'.format(*pair)) for pair in feature_importances];
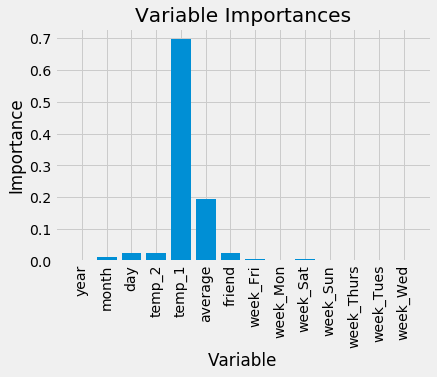
Variable: temp_1 Importance: 0.7
Variable: average Importance: 0.19
Variable: day Importance: 0.03
Variable: temp_2 Importance: 0.02
Variable: friend Importance: 0.02
Variable: month Importance: 0.01
Variable: year Importance: 0.0
Variable: week_Fri Importance: 0.0
Variable: week_Mon Importance: 0.0
Variable: week_Sat Importance: 0.0
Variable: week_Sun Importance: 0.0
Variable: week_Thurs Importance: 0.0
Variable: week_Tues Importance: 0.0
Variable: week_Wed Importance: 0.0
В верхней части списка находится temp_1, максимальная температура за предыдущий день. Можно прийти к интуитивному выводу о том, что наилучшим предиктором величины максимальной температуры в течение дня является величина максимальная температуры накануне. Вторым по значимости фактором является среднестатистическая максимальная температура, что также не удивительно. А вот друг оказался не очень полезным, так же, как и день недели, год, месяц и температура за два предшествующих дня. Такой результат вполне оправдывает себя ‑ мы интуитивно и не ожидаем, что день недели станет предиктором максимальной температуры, поскольку он не имеет никакого отношения к погоде. Более того, год одинаков для всех температурных значений и, следовательно, не дает нам информации для прогнозирования максимальной температуры.
В будущих реализациях модели мы сможем удалить те переменные, которые не имеют значения, причем производительность при этом не пострадает. Кроме того, если мы используем другую модель, скажем, машину с поддержкой обработки векторных данных, то сможем использовать функции случайных значений леса как своего рода метод выбора объектов. Давайте быстро создадим Random forest с двумя наиболее важными переменными: максимальной температурой за предшествующий день и историческим средним значением и посмотрим, как будет различаться производительность.
# New random forest with only the two most important variables
rf_most_important = RandomForestRegressor(n_estimators= 1000, random_state=42)
# Extract the two most important features
important_indices = [feature_list.index('temp_1'), feature_list.index('average')]
train_important = train_features[:, important_indices]
test_important = test_features[:, important_indices]
# Train the random forest
rf_most_important.fit(train_important, train_labels)
# Make predictions and determine the error
predictions = rf_most_important.predict(test_important)
errors = abs(predictions - test_labels)
# Display the performance metrics
print('Mean Absolute Error:', round(np.mean(errors), 2), 'degrees.')
mape = np.mean(100 * (errors / test_labels))
accuracy = 100 - mape
print('Accuracy:', round(accuracy, 2), '%.')
Mean Absolute Error: 3.9 degrees.
Accuracy: 93.8 %.
Это говорит о том, что в действительности не нужны те данные, которые мы собрали, для получения точных прогнозов! Если бы мы использовали эту же модель, то достаточно было бы собрать только две переменные и получить туже производительность. Для решения задачи калибровки потребуется взвешивать соотношение между снижением точности и дополнительным временем, необходимым для получения дополнительной информации. Умение найти верный баланс между производительностью и стоимостью является важным навыком инженера по компьютерному обучению и в конечном итоге будет определяться задачей!
К данному моменту мы уже рассмотрели почти все необходимое для базовой реализации Random forest при решении задачи контролируемой регрессии. Теперь можем быть уверены, что наша модель может прогнозировать максимальную температуру на следующий день с точностью 94% на основе годовых исторических данных. Поиграйте на этом примере или используйте модель в наборе данных по своему выбору. Завершу этот пост, показав несколько визуализаций. У меня две любимые части науки о данных — это графика и моделирование, поэтому, естественно, я должен построить диаграммы! Кроме того, что на диаграммы просто приятным смотреть, они могут помочь диагностировать используемую модель, потому что они в легко воспринимаемом глазом изображении вмещают огромное количество чисел.
Визуализации
Первая диаграмма, которую я построю, представляет собой простую столбцовую диаграмму характеристик функции, иллюстрирующую различия относительной значимости переменных. Процесс построения графика в Python не является интуитивно понятным, поэтому в конечном счет, приходится просматривать почти все на Stack Overflow, чтобы построить график. Поэтому не стоит беспокоится, если приводимый код покажется не совсем понятным, иногда полное понимание кода не обязательно для получения желаемого конечного результата!
# Import matplotlib for plotting and use magic command for Jupyter Notebooks
import matplotlib.pyplot as plt
%matplotlib inline
# Set the style
plt.style.use('fivethirtyeight')
# list of x locations for plotting
x_values = list(range(len(importances)))
# Make a bar chart
plt.bar(x_values, importances, orientation = 'vertical')
# Tick labels for x axis
plt.xticks(x_values, feature_list, rotation='vertical')
# Axis labels and title
plt.ylabel('Importance'); plt.xlabel('Variable'); plt.title('Variable Importances');
Затем можем построить весь набор данных с выделенными прогнозами. Это требует небольшого манипулирования данными, но в целом это не слишком сложно. Можно использовать этот график, чтобы определить, есть ли какие-либо выбросы в данных или в наших прогнозах.
# Use datetime for creating date objects for plotting
import datetime
# Dates of training values
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
# List and then convert to datetime object
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# Dataframe with true values and dates
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
# Dates of predictions
months = test_features[:, feature_list.index('month')]
days = test_features[:, feature_list.index('day')]
years = test_features[:, feature_list.index('year')]
# Column of dates
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
# Convert to datetime objects
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
# Dataframe with predictions and dates
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predictions})
# Plot the actual values
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# Plot the predicted values
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60');
plt.legend()
# Graph labels
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');
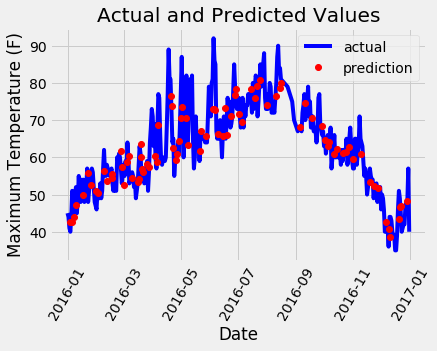
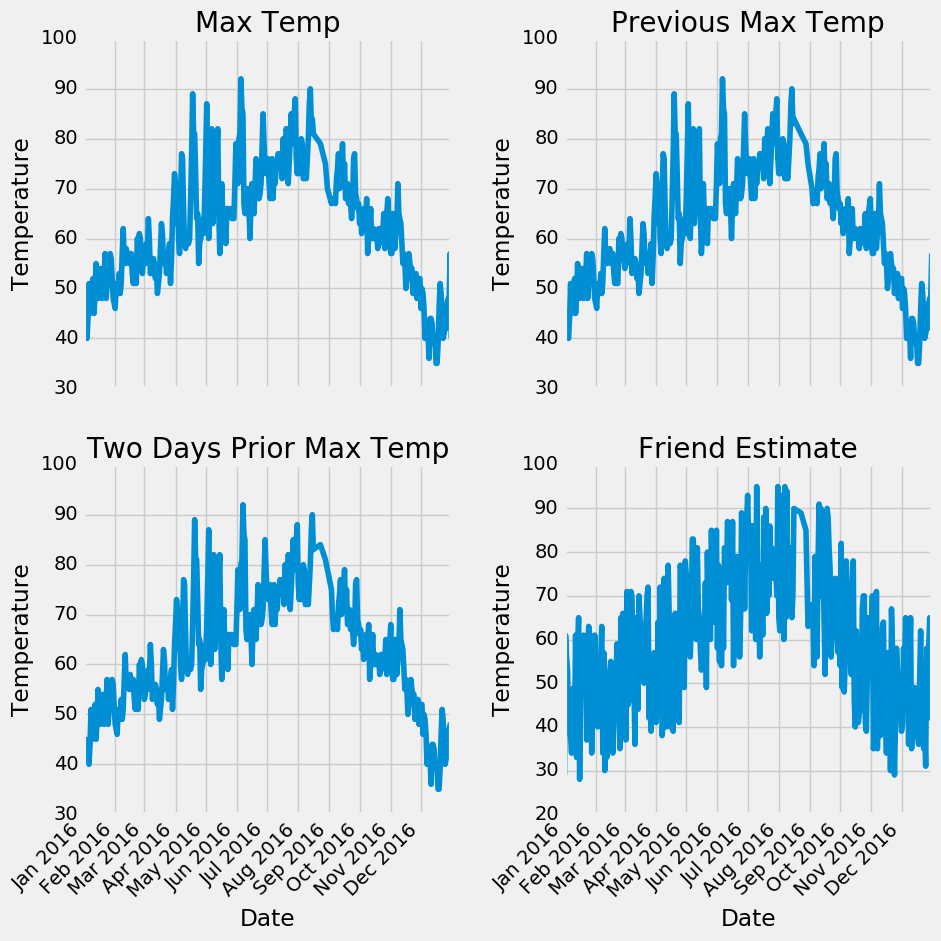
Потребуется совсем немного работы для получения красивого графика! Он не выглядит так, как если бы у нас имелись заметные выбросы, которые необходимо исправить. Чтобы дополнительно диагностировать модель, можем построить остатки (ошибки), чтобы убедиться, имеет ли наша модель тенденцию к прогнозу с преувеличением или, занижением прогнозируемых величин, можем увидеть, нормально ли распределены остатки. Однако я просто приведу заключительную диаграмму, показывающую фактические значения, температуру за предшествующий день, исторические средние и прогноз нашего друга. Это позволит нам увидеть разницу между полезными переменными и теми, которые менее полезны.
# Make the data accessible for plotting
true_data['temp_1'] = features[:, feature_list.index('temp_1')]
true_data['average'] = features[:, feature_list.index('average')]
true_data['friend'] = features[:, feature_list.index('friend')]
# Plot all the data as lines
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual', alpha = 1.0)
plt.plot(true_data['date'], true_data['temp_1'], 'y-', label = 'temp_1', alpha = 1.0)
plt.plot(true_data['date'], true_data['average'], 'k-', label = 'average', alpha = 0.8)
plt.plot(true_data['date'], true_data['friend'], 'r-', label = 'friend', alpha = 0.3)
# Formatting plot
plt.legend(); plt.xticks(rotation = '60');
# Lables and title
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual Max Temp and Variables');
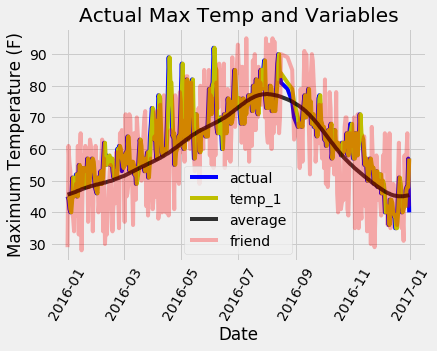
Несколько затруднительно различить все линии, но мы можем понять, почему максимальная температура за предыдущий день и максимальная историческая температура полезны для прогнозирования максимальной температуры, тогда как наш друг – не является полезным (не отказывайтесь от советов друга, просто не придавайте его прогнозам слишком большой вес!). Такие графики часто оказываются полезными, поэтому стоит сделать их заблаговременно, таким образом мы можем выбрать переменные, которые могут быть использованы и для диагностики. Как и в случае квартета Anscombe, графики часто позволяют понять гораздо больше, чем просто изучение числовых значений, и должны быть частью любого рабочего процесса машинного обучения.
Выводы
На этих графиках мы завершили процесс машинного обучения! Теперь, если хотим улучшить нашу модель, сможем попробовать разные гиперпараметры (настройки), попробовать другой алгоритм или более хороший подход для более детального сбора данных! Производительность любой модели прямо пропорциональна количеству действительных данных, которые она может извлечь, а мы использовали очень ограниченный объем информации для обучения. Я бы рекомендовал, вам попытаться улучшить эту модель и поделиться результатами. Так вы сможете глубже разобраться в теорию Random forest и его приложениях, используя многочисленные открытые онлайн-ресурсы (причем, бесплатно). Для тех, кто ищет одну книгу как с теорией, так и с примерами реализаций моделей машинного обучения на Python, настоятельно рекомендую Hands-On Machine Learning with Scikit-Learn and Tensorflow. Более того, надеюсь, что все, кто повторил все шаги вместе с нами убедились, насколько стало доступно машинное обучение, и теперь готовы присоединиться к гостеприимному и полезному сообществу машинного обучения.
Перевод статьи William Koehrsen: Random Forest in Python





