
Обработка естественного языка или NLP (от англ. Natural language processing) — одна из самых известных областей науки о данных. За последнее десятилетие она приобрела большую популярность как в промышленных, так и в академических кругах.
Но правда в том, что NLP — это далеко не новая область. Стремление человека к тому, чтобы компьютеры понимали наш язык, существовало с момента их создания. Да, те старые компьютеры, которые с трудом могли запустить несколько программ одновременно, всё же успели познакомится со сложностью естественных языков.
Естественный язык — это любой человеческий язык, такой как английский, арабский, русский и т. д. Насколько трудно сделать так, чтобы компьютер понимал естественные языки, зависит от их структуры. Более того, когда мы говорим, то часто по-разному произносим слова, наши акценты отличаются, независимо от того, используем ли мы родной язык или иностранный. Мы также часто склонны «жевать» слова во время разговора, чтобы быстрее донести мысль, не говоря уже обо всех сленговых словах, которые появляются каждый день.
Цель этой статьи — пролить свет на историю естественной обработки языка и её подразделы.
Начало развития NLP
Естественная обработка языка — это междисциплинарная область на стыке информатики и лингвистики. Существует бесконечное количество способов, чтобы соединить слова и составить из них предложение. Конечно, не все эти предложения будут грамматически правильными или даже иметь смысл.
Люди могут их различать, но компьютер — нет. Более того, нереально загрузить в него словарь со всеми возможными предложениями на всех возможных языках.
На ранних этапах учёные предлагали разделять любое предложение на набор слов, которые можно обрабатывать индивидуально, что гораздо проще, чем обрабатывать предложение целиком. Этот подход аналогичен тому, с помощью которого обучают новому языку детей и взрослых.
Когда мы только начинаем учить язык, нас знакомят с его частями речи. Для примера возьмём английский язык. В нём есть 9 основных частей речи: существительные, глаголы, прилагательные, наречия, местоимения, артикли и др. Эти части речи помогают понять назначение каждого слова в предложении.
Однако недостаточно знать категорию слова, особенно для тех, которые могут иметь более одного значения. Например, слово «leaves» может быть формой глагола « to leave» (англ. уходить) или формой множественного числа существительного «leaf» (англ. лист).
Поэтому компьютерам необходимо базовое понимание грамматики, чтобы обращаться к ней в случае замешательства. Таким образом появились правила структуры фраз.
Они представляют собой набор правил грамматики, по которым строится предложение. В английском языке оно образуется с помощью именной и глагольной группы. Рассмотрим предложение: «Anne ate the apple» (англ. Энн съела яблоко). Здесь «Anne» — это именная группа, а «ate the apple» — это глагольная группа.
Различные предложения формируются с использованием разных структур. По мере увеличения количества правил структуры фраз можно создавать дерево синтаксического анализа, чтобы классифицировать каждое слово в конкретном предложении и прийти к его общему значению.
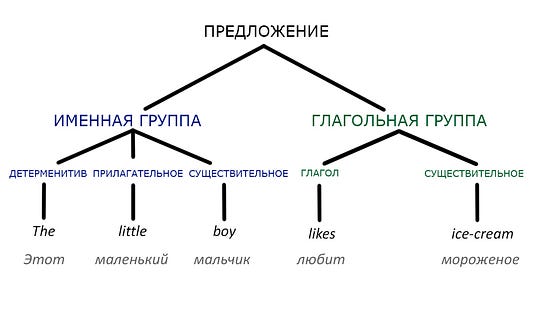
Всё это отлично работает, если предложения просты и ясны. Но проблема в том, что они могут быть достаточно сложными, или в них могут использоваться не совсем однозначные слова или неологизмы. В этом случае компьютерам будет сложно понять, что имелось в виду.
Подразделы NLP
Обработка текста
Чат-боты — один из хорошо известных примеров NLP. Изначально чат-боты были основаны на системе правил. Это означало, что специалисты должны были закодировать сотни, а возможно, и тысячи правил структуры фраз, чтобы чат-бот корректно ответил на данные, которые вводит человек. Таким примером является Eliza. Это чат-бот, разработанный в 1960-х годах и пародирующий диалог с психотерапевтом.
Сегодня большинство чат-ботов и виртуальных помощников создаются и программируются с использованием методов машинного обучения. Эти методы основываются на многочисленных гигабайтах данных, собранных во время разговоров между людьми.
Чем больше данных будет передано модели машинного обучения, тем лучше будет работать чат-бот.
Распознавание речи
Чат-боты про то, как компьютеры понимают письменный язык. А что насчёт устной речи? Как компьютеры могут превратить звук в слова, а затем понять их значение?
Распознавание речи — второй подраздел обработки естественного языка. Это тоже совсем не новая технология. Она была в центре внимания многих исследователей в течение последних десятилетий. В 1970-х годах в Университете Карнеги-Меллона была разработана Harpy. Это была первая компьютерная программа, которая понимала 1000 слов.
В то время компьютеры не были достаточно мощными для распознавания речи в реальном времени, если только вы не говорили очень медленно. Это препятствие было устранено с появлением более быстрых и мощных компьютеров.
Синтез речи
Синтез речи во многом противоположен распознаванию речи. С помощью этой технологии у компьютера появилась возможность издавать звуки или произносить слова.
Первым в мире устройством для синтеза речи считается VODER (англ. Voice Operating Demonstrator — модель голосового аппарата). Оно было разработано Гомером Дадли из компании Bell Labs в 1930-х годах. У VODER было ручное управление. С тех пор многое изменилось.
В системах распознавания речи и чат-ботах предложения разбиваются на фонемы. Чтобы произнести определенное предложение, компьютер сохраняет эти фонемы, преобразовывает и воспроизводит.
Такой способ соединения фонем был и остаётся причиной того, что речь компьютера звучит очень роботизировано, поскольку на границах сшивки элементов часто возникают искажения.
Конечно, со временем звучание стало лучше. Использование современных алгоритмов в новейших виртуальных помощниках, таких как Siri, Cortana и Alexa, подтверждает то, что мы далеко продвинулись. Однако их речь по звучанию по-прежнему немного отличается от человеческой.
Заключение
Обработка естественного языка — общее название области, которое охватывает множество подразделов. Во всех них обычно используют модели машинного обучения, в основном нейросети, и данные множества разговоров между людьми.
Поскольку человеческие языки постоянно и стихийно развиваются, а компьютеру нужны чёткие и структурированные данные, при обработке возникают определённые проблемы и страдает точность. Кроме того, методы анализа текстов сильно зависят от языка, жанра, темы — всегда требуется дополнительная настройка. Однако сегодня многие задачи обработки естественного языка всё же решаются с применением глубокого обучения нейронных сетей.
Обработка естественного языка или NLP (англ. Natural Language Processing) — направление на стыке информатики и лингвистики, которое даёт возможность компьютерам понимать человеческий, т. е. естественный язык. Сейчас это одна из самых популярных областей науки о данных. Однако она существует с момента изобретения компьютеров.
Именно развитие техники и вычислительной мощности привело к невероятным достижениям в сфере NLP. Технологии синтеза и распознавания речи становятся такими же востребованными, как и технологии, работающие с письменными текстами. Разработка виртуальных помощников, таких как Siri, Alexa и Cortana, свидетельствует о том, насколько далеко продвинулись учёные.
Так что же необходимо знать, чтобы начать заниматься естественной обработкой языка? Нужна ли степень по информатике?
Чтобы стать специалистом по NLP, никакие степени не понадобятся. Всё, что вам потребуется, это изучить и попрактиковать определённые навыки, а также создать несколько проектов, чтобы подтвердить свои знания.
В начале пути в сфере обработки естественного языка может быть сложно. Объём информации в интернете огромен и может сбивать с толку или вести не туда. Я, как человек, который сам через это прошёл, решила написать статью и поделиться коротким и чётким руководством для старта.
1. Основы лингвистики
По сути, NLP — это про изучение языков. Разработчик пытается объяснить компьютеру, как понимать мудрёную письменную и устную речь человека.
Я занялась NLP, потому что меня всегда интересовали языки и то, как они образовывались и развивались с течением времени. Однако говорить на каком-то языке не означает полностью понимать его логику.
Чтобы иметь прочную основу для начала работы в NLP, необходимо полностью осознавать базовую логику языка, которому вы пытаетесь «научить» компьютер. Этот язык не обязательно должен быть вашим родным. Вы даже можете выучить новый при разработке проекта для его анализа.
Я не имею в виду, что нужно получать степень по лингвистике или что-то в этом роде. Я пытаюсь сказать, что понимание того, как языки решают различные проблемы, может оказаться полезным при разработке и анализе приложений для NLP. Более того, зная о межъязыковом влиянии, вы можете создавать многоязычные приложения.
Я рекомендую начать изучение основ лингвистики для обработки естественного языка с книги Эмили М. Бендер «Основы лингвистики для естественной обработки языка» (англ. Emily M. Bender Linguistic Fundamentals for Natural Language Processing).
2. Манипуляции со строками
«Язык», на котором вы пытаетесь анализировать и создавать приложения, обычно имеет форму строк. Даже если это приложение для распознавания речи, она всё равно преобразовывается в текст перед анализом.
Поэтому первый шаг, который вам нужно освоить перед погружением в основные техники NLP, — это манипуляции со строками с использованием любого языка программирования.
Если у вас нет опыта программирования, то рекомендую начать с Python. Он широко используется в различных областях науки о данных, включая NLP. Если у вас уже есть опыт программирования на других языках, то освоить манипуляцию со строками не составит труда.
3. Регулярные выражения
После того, как вы освоите операции со строками с помощью встроенных функций на выбранном вами языке программирования, следующим шагом будут регулярные выражения.
Это один из самых мощных и эффективных методов обработки текста. У регулярных выражений своя терминология, условия и синтаксис. Некоторые разработчики рассматривают их как мини-язык программирования. Они помогут обобщить правила и сделать приложения для обработки тестов более эффективными.
4. Очистка данных
Качество результата работы зависит от входных данных. Поэтому важно, чтобы они были подготовлены наилучшим образом. Этот навык применим не только к проектам по NLP, но и ко всем областям науки о данных. Однако подходы к очистке данных различаются в зависимости от задач и целевых результатов.
При подготовке текста к обработке и анализу мы обычно удаляем все знаки препинания. Это помогает улучшить вариативность слов в тексте. Также существуют различные типы слов, например стоп-слова, которые можно удалить для более эффективного анализа.
Три основных шага очистки текста для NLP:
- переведите все слова в нижний регистр;
- удалите стоп-слова (это часто используемые слова, которые не вносят дополнительную информацию в текст);
- приведите все слова к первоначальному корню.
5. Анализ текста
Наконец-то мы подошли к разделу навыков непосредственно из обработки естественного языка. Получив чистый набор данных, вы будете готовы создавать модели и начинать анализировать текст. Но для этого вам нужно немного знать терминологию из NLP.
Вот пять основных навыков и их значение:
- n-граммы — это тип вероятностной языковой модели, используемой для предсказания следующего элемента в последовательности слов;
- токенизация — это процесс разбиения предложения на отдельные слова или токены: глаголы, существительные, местоимения и т. д.;
- стемминг — это процесс нахождения основы для заданного слова, например cleaning => clean, но это не всегда работает;
- POS tagging — процесс обработки текста, задачей которого является определение части речи слова и присвоение ему соответствующего тега;
- лемматизация — процесс приведения заданного слова к его словарной форме.
6. Основы машинного обучения
Воспользовавшись основными навыками обработки языка, мы получаем корпус — набор данных после очистки текста и выполнения других основных задач NLP. Далее его необходимо проанализировать и извлечь полезную информацию. Для этого понадобится алгоритм машинного обучения.
Давайте рассмотрим два наиболее часто используемых алгоритма:
- Алгоритм кластеризации: применяется для поиска закономерностей в данных, таких как тональность, количество и частота используемых слов. Он подходит для обнаружения ложных новостей или неточной информации.
- Алгоритм классификации: используется для размещения текста в заранее определённых тегах. Его наиболее известное применение — сортировка входящих писем по папкам «входящие» или «спам».
7. Оценочные метрики
Это очень важный пункт, о котором обычно забывают. Каждый раз, когда вы применяете модель машинного обучения к данным, необходимо оценивать её результаты. Для каждой модели нужны свои метрики.
Вот некоторые из них:
- матрица неточностей;
- точность;
- F-score (среднее гармоничное значение между точностью и полнотой);
- ROC-кривая (англ. Receiver Operating Characteristic — рабочая характеристика приёмника).
Более подробную информацию вы можете узнать в материалах лекции из Массачусетского университета в Амхерсте (материалы на англ. яз.).
8. Глубокое обучение
Глубокое обучение полезно для определённых задач, требующих нелинейности пространства признаков. Оно предоставляет улучшенные модели с более высокой точностью и качественными результатами.
Один из самых часто используемых методов глубокого обучения в NLP — рекуррентные нейронные сети. К счастью, нет необходимости знать, как реализовать этот алгоритм или множество других, благодаря открытым библиотекам, таким как Keras и Scikit-learn, написанным на языке Python.
А что действительно нужно сделать, так это научиться эффективно использовать алгоритм, изучая его способ работы и узнавая, какие он даёт результаты.
9. Создание проектов
У меня этот шаг под номером 9, но его необходимо выполнять параллельно со всеми предыдущими шагами. Всегда сразу применяйте свои знания на практике. Это единственный способ проверить, насколько вы их усвоили.
При этом, чем больше вы знаете, тем более крутые приложения вы можете создавать. Вот несколько идей, которые можно опробовать, когда у вас будет достаточно знаний.
- приложение для тематического моделирования;
- идентификатор языка;
- генератор хайку;
- приложение, мониторящее социальные сети.
Таких идей ещё много. Дерзайте.
10. Научные статьи
Все подразделы науки о данных являются активными областями исследований. Как специалисту по данным в целом и специалисту по обработке естественного языка в частности, вам необходимо быть в курсе последних разработок в этой сфере. Единственный способ это сделать — следить за недавно опубликованными научными статьями о NLP.
Мне удобно создавать оповещения в Google Академии о новых публикациях по конкретным темам, которые меня интересуют: я получаю электронное письмо, как только они выходят.
Заключение
Иногда изучение нового навыка или получение новых знаний — довольно сложная задача. Но если не бросать это на полпути, а продолжать практиковаться и постоянно расширять базу знаний, вы достигнете своей цели.
«Мы можем делать всё, что захотим, если будем придерживаться этого достаточно долго», — Хелен Келлер.
Освоение обработки естественного языка может быть трудной задачей из-за огромного количества информации в интернете. Я надеюсь, что эта статья поможет вам сориентироваться в процессе обучения и сделает его немного проще.
Читайте также:
- Пять отличных Python-библиотек для data science
- Значение Data Science в современном мире
- Шесть рекомендаций для начинающих специалистов по Data Science
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Sara A. Metwalli: NLP 101: Towards Natural Language Processing





