
Введение
Вы любите SQL и хотите улучшить свои навыки выполнения SQL-запросов? Вы знаете, что индексация — отличный инструмент для оптимизации запросов, но при этом не уверены, что она из себя представляет, с какой целью и как используется?
Добро пожаловать! Вы оказались именно там, где нужно. Сейчас объясним суть индексации на простом и понятном языке.

Представьте, что вы состоите в команде по аналитике электронной коммерции на Amazon и работаете с огромным объемом данных, включающих миллионы строк. Для наглядности воспользуемся условной таблицей с именем product, содержащей 12 миллионов товаров. Кстати, именно такое количество и продается на Amazon, не считая книг, аудио и видеотехники, алкогольной продукции и услуг.
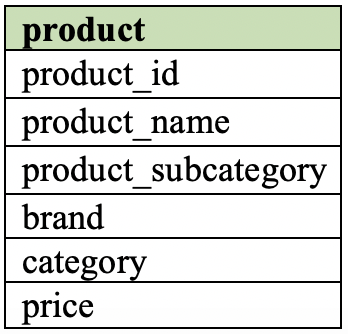

Начнем с простого запроса:
SELECT COUNT(*)
FROM product
WHERE category = ‘electronics’;Для его выполнения база данных (БД) должна просканировать все 12 миллионов строк, чтобы проверить каждую запись на соответствие. Предположим, что время этой операции составляет 4 секунды.
Можно ли быстрее? Конечно. А Как? С помощью индексации.
Индексация
Понятие индексации
Свое название индексация получила по образу и подобию книжного индекса. Если, читая книгу по статистике, вы ищите информацию о “линейной регрессии”, то, вряд ли, станете поочередно перелистывать сотни страниц, чтобы добраться до главы с интересующим вас материалом.
Вы просто откроете страницу индексов, найдете “линейную регрессию” и сразу перейдете на нужную страницу.
Индексация позволяет задействовать данный метод и в работе БД, которая с помощью созданного индекса быстро находит данные по запросу. А как именно это происходит, разберемся далее.
Создание индексов
Давайте создадим индекс для таблицы product и включим в него ‘category’:
Syntax:
CREATE INDEX [index_name]
ON [table_name] ([column_name]);
Query:
CREATE INDEX product_category_index
ON product (category);В отличии от обычного запроса выполнение вышеуказанного займет гораздо больше времени. БД просканирует 12 миллионов строк и с нуля создаст индекс category. Допустим, на это уйдет 4 минуты.
Теперь же задействуем индекс и протестируем выполнение самого первого нашего запроса:
SELECT COUNT(*)
FROM product
WHERE category = ‘electronics’;Как видно, в этот раз он будет выполняться намного быстрее и, вероятно, займет 400 миллисекунд.
Даже расширенные запросы, содержащие в качестве условия не только category, станут более эффективными благодаря созданному индексу. Рассмотрим пример:
SELECT COUNT(*)
FROM product
WHERE category = ‘electronics’
AND product_subcategory = ‘headphone’;Выполнение этого запроса займет меньше времени, чем обычно — около 600 миллисекунд. С помощью индекса БД быстро найдет все товары ‘electronics’ и из небольшого списка записей выберет ‘headphones’.
А сейчас изменим порядок условий в пункте WHERE.
SELECT COUNT(*)
FROM product
WHERE product_subcategory = ‘headphone’
AND category = ‘electronics’;Несмотря на упоминание product_subcategory до category, БД тем не менее сначала выберет столбец с индексом, а именно category, после чего просканирует строки в поиске указанной product_subcategory из числа имеющихся записей.
Какова же внутренняя суть процесса?
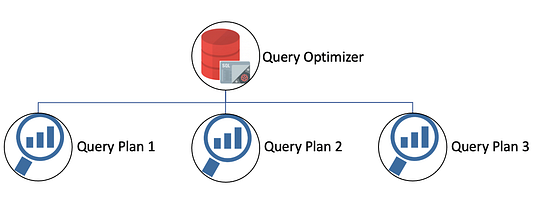
БД анализирует все возможные пути выполнения запроса, выбирая самый оптимальный из них.
Теперь пора познакомиться с некоторыми терминами БД. Каждый возможный путь называется планом выполнения запроса. По сути, это последовательность операций для получения результата SQL-запроса в реляционной системе управления базами данных (СУРБД).
А компонент СУРБД, определяющий наиболее эффективный способ выполнения запроса с учетом анализа всех возможных планов, называется оптимизатором запросов.
Индексация по нескольким столбцам
Теперь рассмотрим индексацию по нескольким столбцам.
Индекс можно создать более чем для одного столбца.
CREATE INDEX product_category_product_subcategory_index
ON product (category, product_subcategory);Итак, теперь у нас есть индекс для обоих столбцов: category и product_subcategory. Обратите внимание, что здесь важна очередность — сначала сортируются данные в category, после чего в product_subcategory.
Данный тип индекса еще больше ускорит выполнение запроса, предположительно до 60 миллисекунд.
Более того, БД может включать более одного индекса.
В каких случаях следует применять индексацию?
Индексы ускоряют работу БД, а по мере ее разрастания их эффективность становится очевиднее.
При этом важно помнить о том, что:
- Индексам необходимо место для хранения.
- При добавлении данных в БД сначала обновляется исходная таблица, а затем все ее индексы.
В связи с этим, лучше использовать индексы для БД в хранилищах данных, получающих плановые обновления, т. е. в часы наименьшей нагрузки, а не для производственных, которые обновляются постоянно. Это объясняется тем, что при постоянных обновлениях БД индексы обновляться не будут, а следовательно станут бесполезны.
Типы индексов
Здесь мы кратко рассмотрим 2 типа индексов БД для лучшего понимания темы:
1. Кластеризованные индексы
2. Декластеризованные индексы
Кластеризованные индексы
Кластеризованные называется особый индекс, который использует первичный ключ для структуризации данных в таблице. Он не требует явного объявления и создается по умолчанию при определении ключа. Отсортированный же в порядке возрастания первичный ключ по умолчанию применяется в качестве кластеризованного индекса.
Продемонстрируем вышесказанное на простом примере:
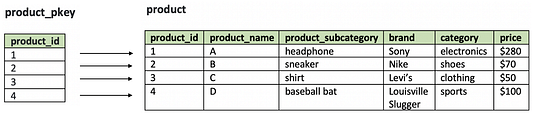
Для таблицы product будет автоматически создан кластеризованный индекс product_pkey, сформированный вокруг первичного ключа product_id.
В этом случае при выполнении в таблице поискового запроса по product_id, как показано ниже, кластеризованный индекс поможет БД оптимально справиться с задачей и быстрее вернуть результат.
SELECT product_name, category, price
FROM product
WHERE product_id = 3;Интересно, как же именно это происходит?
Индексы используют оптимальный метод поиска, известный как двоичный поиск.
Двоичный поиск — это эффективный алгоритм поиска записи в сортированном списке. Принцип его работы основан на повторяющемся делении данных пополам и определении того, находится ли искомая запись до или после записи в середине структуры данных. Если значение искомой записи меньше срединного, то поиск продолжается в первой половине, иначе — во второй. Эта процедура повторяется вплоть до нахождения значения. Благодаря данному методу уменьшается число требуемых поисков и, следовательно, ускоряется выполнение запросов.
Следующая таблица отражает соотношение записей данных и максимальное число поисков:
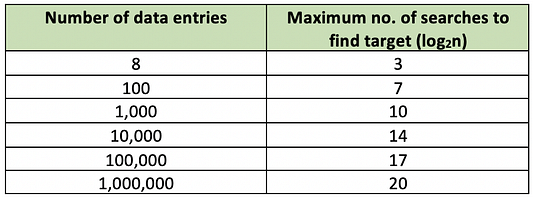
Аналогичным образом для нашего датасета с 12 миллионами строк понадобится не 12 миллионов, а всего лишь 24 поиска — и всё благодаря двоичному поиску. Думаю, теперь вы осознаете супер силу индексов.
Некластеризованный индекс
Теперь узнаем, как применить преимущества индексации к столбцами, отличающимися от первичного ключа. Для этого существуют некластеризованные индексы.
Их примеры уже встречались в начальных разделах статьи во время написания оптимизированных запросов — это индексы, которые требуют явного определения.
Некластеризованный индекс хранится в одном месте, а физические данные таблицы — в другом. Опять нам на ум приходит сравнение со страницей индексов, которая размещается отдельно от содержимого книги. Благодаря этой особенности для каждой таблицы можно создавать более одного некластеризованного индекса, как было показано ранее.
Как именно это происходит?
Предположим, вы уже создали некластеризованный индекс для столбца и теперь пишите запрос для поиска в нем записи. Этот индекс содержит следующее:
- записи столбца, для которых был создан индекс;
- адреса соответствующей строки (в основной таблице), в которой находится запись столбца.
Это наглядно отображено в таблице слева на рис.6:

Давайте рассмотрим этот запрос более подробно:
CREATE INDEX product_category_index
ON product (category);
SELECT product_name, category, price
FROM product
WHERE category = ‘electronics’;БД совершает 3 шага:
- Во-первых, она переходит по некластеризованному индексу (
product_category_index) и методом двоичного поиска находит искомую запись столбца (category = ‘electronics’). - Во-вторых, в основной таблице она ищет адреса соответствующей строки, в которой находится запись столбца.
- В-третьих, она переходит к этой строке в основной таблице и выбирает другие значения столбца в соответствии с требованиями запроса (
product_name, price).
Как видим, работа с некластеризованным индексом предполагает дополнительный шаг, включающий поиск адреса строки и переход к ней в основной таблице. Следовательно запрос с таким индексом выполняется медленнее в отличие от кластеризованного аналога.
Заключение
Итак, мы выяснили, что такое индексы и какую роль они играют в оптимизации выполнения SQL-запросов, особенно при работе с огромными датасетами.
В завершении приведу вам высказывание Тайгера Вудса, лучшего гольфиста всех времен:
“Независимо от того, насколько хорошо вы играете, вы всегда можете стать лучше, и это вдохновляет”.
Читайте также:
- Основы SQLite на примере практической задачи
- Что такое SQL-атаки и как с ними бороться?
- Развертывание Flask приложения на Heroku и подключение к БД MySQL - JawsDB
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Ashish Tomar: How to use Indexing for SQL Query Optimization





