
Чуть более двух десятилетий назад, на заре своего развития Интернет столкнулся с серьезной проблемой: очень сложно было найти «правильную», необходимую информацию. Другими словами, поисковые системы в то время были весьма несовершенными.
А потом появился Google с единственной целью — указать людям на источники, которые они ищут. И это была непростая задача, состоящая из двух частей.
В первую очередь следует понять, чего хотят люди, используя поисковую систему (не то, что они вводят в поле поиска, а то, что они «желают» видеть в результате). Во-вторых, какие результаты должны выдаваться первыми, вернее: какой среди множества относительно похожих источников имеет правильный ответ.
И впоследствии долгое время казалось, что проблема решена (почти). Люди были все более довольны результатами, которые они получали от Google, а веб-сайты снова и снова учились играть по правилам и алгоритмам Google. Но затем появились социальные сети и изменили правила игры.
В действительности социальные сети никогда по-настоящему не считали, что показывать людям следует именно то, что им нужно и когда им это необходимо. Они нацелены на вовлечение своих пользователей — на создание эффекта зависимости. Если поисковые системы стараются как можно скорее переадресовать людей от своей платформы, то социальные сети не хотят отпускать как можно дольше. Поэтому для них сетевой эффект и взаимодействие пользователей гораздо важнее контента.
Следовательно они никогда по-настоящему не являлись поисковыми системами по своей сути. Любая обзорная или поисковая функция в каждой социальной сети напоминает пользователям о неудачных поисковых системах 90-х годов. Никто не может найти то, что ищет, и никто не знает, какой результат выбрать.
Социальные сети игнорируют два основных достижения Google для Интернета: понимание «желания» пользователей в процессе поиска и ранжирование результатов. Вдобавок, с ними случилось нечто гораздо худшее: поскольку все в социальной сети так легко автоматизировать, то фальшивые и автоматические учетные записи и «боты» охватили большую часть почти всех социальных сетей в мире, несмотря на все усилия по противодействию.
Учетные записи в социальных сетях создавать намного проще, чем веб-сайты, их легче дублировать, задействовать и автоматизировать. У них гораздо меньше ответственности и подотчетности, поэтому фейки и дезинформация передаются в них гораздо быстрее.
Какое нам до этого дело?
Особенно страдает от этой болезни Twitter. Во всем мире люди используют его чаще, чем любую другую социальную сеть, чтобы следить за новостями, получать обновления и находиться в курсе событий. В последние годы Twitter показал, что не может решить эту проблему самостоятельно. Чтобы увидеть всю глубину проблемы, посмотрите исследование Университета Айовы (англ).
Основной проблемой Twitter сегодня является фальшивая информация и фейковые аккаунты, которые пишут и распространяют фейковые новости и нерелевантные данные. Такая ситуация приводит к тому, что реальные новости и реальная информация оказываются погребенными под лавиной фальшивок.
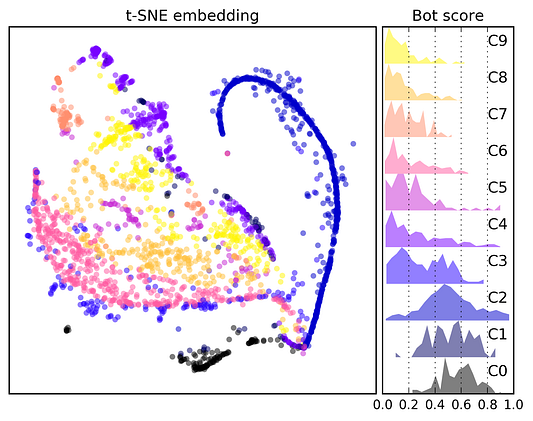
Например, это исследование, проведенное в 2017 году, показывает, что значительная часть учетных записей в Twitter (от 9% до 15%), скорее всего, являются ботами, а это почти 50 миллионов аккаунтов, согласно оценке 2017 года, когда пользователей Twitter было около 320 миллионов. Сегодня их больше 500 миллионов. Не все боты опасны, но многие используются с вредоносными целями.
Чтобы решить эту проблему, в Twitter необходимо внедрить наработки Google. Соцсеть должна иметь систему ранжирования для всех аккаунтов и контента, а для этого мы должны мыслить как поисковая машина, чтобы увязать «желание» с «верным ответом».
Анализ миллиардов наборов данных Twitter займет вечность и не даст желаемых результатов. И вновь, мы заимствуем поисковый вызов Google, как они оценивают каждый веб-сайт и его контент в сети, не анализируя содержание.
Методы действия и взаимодействия
Сначала мы использовали для анализа данных метод действий и взаимодействий. Он фокусируется на том, «что происходит», а не на анализе всего набора данных. Этот метод особенно полезен в социальных сетях или в сценариях, когда весь массив данных недоступен или слишком велик для анализа.
Действия каждой учетной записи в Twitter создадут шаблон их деятельности. Эти шаблоны, если сравнивать их в большом количестве, создают различные сегментации. Проще говоря, мы можем понять, что представляет собой каждая учетная запись, является ли она бизнес-аккаунтом? Обычный пользователь? Новый адресат? Любит собак? Демократ? Гурман?… Вы поняли.
Этого недостаточно. Различная сегментация означает непохожие группы, перекрывающиеся группы и аномалии. Но взаимодействия важнее действий.
Анализ взаимодействия учетных записей Twitter показывает «качество» и «влияние» каждой учетной записи. Это автоматизированная учетная запись? Влияет ли этот аккаунт на другие? Это фальшивая учетная запись? Эта учетная запись работает в организованной группе (организованны для предоставления прав одного другому, например, для манипуляции при голосовании)?
Главный вопрос, на который дает ответ сочетание этих двух методов: следует ли мне подписаться на этот аккаунт? Можно ли ему доверять или нет?
Как работает ранжирование Twitter?
Мы использовали Twitter Public API в качестве источника данных и вышеупомянутый метод «действия и взаимодействия» для анализа данных, а также Formaloo в качестве платформы данных для выполнения алгоритма.
Для тестирования алгоритма мы опубликовали очень простое приложение для Android, чтобы каждый мог проверить его. Вы можете скачать его из Google Play.
Это приложение предназначено для анализа каждой учетной записи Twitter и ранжирования их на основе действий, взаимодействия между пользователями и контента, которым они делятся. Диапазон рейтинга от 0 до 10, где 0 — это наименьший возможный балл (связываемый в основном с поддельными учетными записями, ботами или неактивными учетными записями), а 10 — наивысший возможный балл. Все рейтинги будут обновляться ежемесячно.
Рейтинг Twitter работает путем подсчета «количества» и «качества» взаимодействий с учетной записью, чтобы определить приблизительную оценку для важности этой учетной записи. Основное предположение состоит в том, что более важные учетные записи, вероятно, будут иметь больше «реальных» взаимодействий с другими учетными записями Twitter.
Этот алгоритм помогает Twitter и его пользователям определить, какие учетные записи являются реальными и эффективными, а какие — неактивными, поддельными, автоматизированными или действуют подозрительно. С помощью этих приложения и алгоритма мы стараемся предоставить реальную ценность каждой учетной записи, на которую вы подписались и решили получать интересующую информацию.
Предложенный алгоритм разработан совсем недавно и полон неточностей, но при достаточном тестировании и возможностях краудсорсинга он может обеспечить самую надежную систему ранжирования, в которой так нуждается Twitter.
Социальные сети, которые мы заслуживаем
Сегодняшние социальные сети — это не те социальные сети, которые мы заслуживаем. Как и в поисковых системах, качество в них намного важнее количества. Недостаточно создавать все более совершенные системы рекомендаций в поисковых функциях социальных сетей. Нам необходимо реализовать идеальную систему ранжирования, охватывающую функции поиска.
Недостаточно просто сосредоточиться на процессе вовлеченности, которое приводит к зависимости от сети, а затем и отвращению от нее. У людей одно за другим возникают разные желания, на которые каждый раз должен быть получен удовлетворяющий ответ.
Читайте также:
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Farokh Shahabi: The big flaw of social networks, and how to solve it





