
Часто, когда заказчики обращаются ко мне с просьбой провести анализ их продукта на основе НЛП, они задают один и тот же вопрос:
«Какая тема чаще всего встречается в этих документах?»
Мне пришлось отказаться от каких-либо категорий или ярлыков и обратиться к методам спонтанного обучения для извлечения этих тем, а именно к тематическому моделированию.
Хотя тематические модели, такие как LDA и NMF, оказались хорошей отправной точкой, я всегда чувствовал, что для создания значимых тем с помощью настройки гиперпараметров требовалось немало усилий.
Более того, я хотел использовать модели на основе трансформаторов, такие как BERT, поскольку результаты их применения в различных задачах НЛП за последние несколько лет оказались потрясающими. Предварительно обученные модели особенно полезны, поскольку предполагается, что они содержат более точные представления слов и предложений.
Несколько недель назад я наткнулся на замечательный проект под названием Top2Vec*, в котором использовались векторные представления документов и слов для создания тем, которые можно было легко интерпретировать. Я начал подбирать код для генерализации Top2Vec, чтобы его можно было использовать с предварительно обученными моделями трансформаторов.
Большим преимуществом Doc2Vec является то, что полученные векторные представления документов и слов совместно встраиваются в одно и то же пространство, что позволяет векторным представлениям документа быть представленными векторными представлениями соседних слов. К сожалению, это приводит к некоторым трудностям, поскольку векторные представления BERT основаны на токенах и не обязательно занимают одно и то же пространство. Хотя они могут занимать одно и то же пространство, полученный размер векторных представлений слов будет довольно большим из-за контекстной природы BERT. Более того, существует вероятность, что ухудшится качество полученных векторных представлений предложений или документов.
Тогда я решил создать другой алгоритм, который мог бы использовать векторные представления BERT и трансформаторов. Так появился BERTopic, алгоритм для создания тем с применением самых современных векторных представлений.
Однако эта статья не об использовании BERTopic, а о том, как использовать BERT для создания вашей собственной тематической модели.
1. Данные и пакеты
В этом примере я использую известный набор данных 20 Newsgroups, который содержит около 18 тысяч сообщений групп новостей на 20 тем. Используя Scikit-Learn, можно быстро загрузить и подготовить эти данные:
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups(subset='all')['data']Если необходимо ускорить обучение, используйте подмножество train, так как оно уменьшит количество извлекаемых сообщений.
ПРИМЕЧАНИЕ: Если вы хотите применить тематическое моделирование не ко всему документу, а на уровне абзаца, я бы предложил разделить данные перед созданием векторных представлений.
2. Векторные представления
В первую очередь необходимо преобразовать документы в числовые данные. Для этой цели я буду использовать BERT, поскольку он извлекает различные векторные представления в зависимости от контекста слова. Помимо BERT существует множество других предварительно обученных моделей.
Как создавать векторные представления BERT для документа, решать вам. Лично я предпочитаю использовать пакет sentence-transformers, поскольку полученные векторные представления демонстрируют высокое качество и обычно достаточно хорошо работают для векторных представлений на уровне документа.
Перед созданием векторных представлений для документов установите пакет с помощью команды pip install sentence-transformers. Если у вас возникнут проблемы с установкой этого пакета, стоит предварительно установить фреймворк Pytorch.
Затем запустите следующий код, чтобы преобразовать ваши документы в 512-мерные векторы:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('distilbert-base-nli-mean-tokens')
embeddings = model.encode(data, show_progress_bar=True)Я использую модель Distilbert, поскольку она хорошо соблюдает баланс между скоростью и производительностью. В пакете есть несколько многоязычных моделей.
ПРИМЕЧАНИЕ: Поскольку модели трансформаторов имеют ограничение по токенам, при загрузке больших документов могут возникать ошибки. В этом случае можно разделить документы на абзацы.
3. Кластеризация
Я хочу проверить, сгруппированы ли документы с похожими темами между собой, чтобы найти темы в этих группах. Прежде чем сделать это, нужно снизить размерность векторных представлений, поскольку многие алгоритмы кластеризации плохо справляются с высокой размерностью.
UMAP можно считать наиболее эффективным из немногих алгоритмов уменьшения размерности, поскольку он сохраняет значительную часть многомерной локальной структуры в более низкой размерности.
Установите пакет с помощью команды pip install umap-learn, прежде чем снизить размерность векторных представлений документов. Уменьшите размерность до пяти, сохраняя при этом размер локальной окрестности равным 15. Вы можете поэкспериментировать с этими значениями, чтобы оптимизировать создание своей темы. Обратите внимание, что слишком низкая размерность приводит к потере информации, в то время как слишком высокая размерность приводит к худшим результатам кластеризации.
import umap
umap_embeddings = umap.UMAP(n_neighbors=15,
n_components=5,
metric='cosine').fit_transform(embeddings)После уменьшения размерности встраиваемых документов до пяти можно кластеризовать документы с помощью HDBSCAN. HDBSCAN — это алгоритм, основанный на плотности, который довольно хорошо работает с UMAP, поскольку UMAP поддерживает большую локальную структуру даже в пространстве меньшей размерности. Более того, HDBSCAN не переносит точки ввода данных в кластеры, поскольку считает их выбросами.
Установите пакет с помощью pip install hdbscan, затем создайте кластеры:
import hdbscan
cluster = hdbscan.HDBSCAN(min_cluster_size=15,
metric='euclidean',
cluster_selection_method='eom').fit(umap_embeddings)Отлично! Мы объединили похожие документы в кластеры, представляющие темы, из которых они состоят. Чтобы визуализировать полученные кластеры, можно дополнительно уменьшить размерность до двух и визуализировать выбросы в виде серых точек:
import matplotlib.pyplot as plt
# Подготовка данных
umap_data = umap.UMAP(n_neighbors=15, n_components=2, min_dist=0.0, metric='cosine').fit_transform(embeddings)
result = pd.DataFrame(umap_data, columns=['x', 'y'])
result['labels'] = cluster.labels_
# Визуализация кластеров
fig, ax = plt.subplots(figsize=(20, 10))
outliers = result.loc[result.labels == -1, :]
clustered = result.loc[result.labels != -1, :]
plt.scatter(outliers.x, outliers.y, color='#BDBDBD', s=0.05)
plt.scatter(clustered.x, clustered.y, c=clustered.labels, s=0.05, cmap='hsv_r')
plt.colorbar()
Визуализировать отдельные кластеры сложно из-за количества созданных тем (~ 55). Однако мы видим, что даже в двумерном пространстве сохраняется некоторая локальная структура.
ПРИМЕЧАНИЕ: Вы можете пропустить этап уменьшения размерности, если используете алгоритм кластеризации, который может обрабатывать высокую размерность, например k-среднее по косинусу.
4. Создание темы
Теперь, когда мы создали кластеры, необходимо понять, чем один кластер по своему содержанию отличается от другого?
Как получить темы из сгруппированных документов?
Чтобы решить эту проблему, я придумал основанный на классах вариант формулы TF-IDF (c-TF-IDF), позволяющий извлекать информацию, которая делает каждый набор документов уникальным по сравнению с другими.
Суть метода заключается в следующем: обычно, когда TF-IDF применяют к набору документов, в основном сравнивают важность слов между этими документами.
Что, если вместо этого мы будем рассматривать все документы в одной категории (например, кластере) как один документ, а затем применять TF-IDF? В результате в каждой категории получится один очень длинный документ, а оценка TF-IDF определит значимые слова в теме.
Чтобы создать эту основанную на классах оценку TF-IDF, сначала необходимо создать один документ для каждого кластера документов:
docs_df = pd.DataFrame(data, columns=["Doc"])
docs_df['Topic'] = cluster.labels_
docs_df['Doc_ID'] = range(len(docs_df))
docs_per_topic = docs_df.groupby(['Topic'], as_index = False).agg({'Doc': ' '.join})Затем мы применяем основанную на классах формулу TF-IDF:
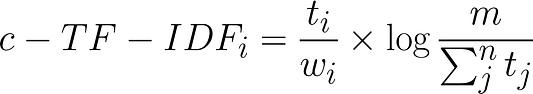
Здесь частотность каждого слова tизвлекается для каждого класса iи делится на общее количество слов w. Это можно считать одним из способов регуляризации частотных слов в классе. Затем общее необъединенное количество документов m делится на общую частотность слова t среди всех классов n.
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
def c_tf_idf(documents, m, ngram_range=(1, 1)):
count = CountVectorizer(ngram_range=ngram_range,
stop_words="english").fit(documents)
t = count.transform(documents).toarray()
w = t.sum(axis=1)
tf = np.divide(t.T, w)
sum_t = t.sum(axis=0)
idf = np.log(np.divide(m, sum_t)).reshape(-1, 1)
tf_idf = np.multiply(tf, idf)
return tf_idf, count
tf_idf, count = c_tf_idf(docs_per_topic.Doc.values, m=len(data))Теперь для каждого слова в кластере у нас есть одно значение важности, которое можно использовать для создания темы. Если мы возьмем 10 самых важных слов в каждом кластере, то получим хорошее представление о кластере и, следовательно, о теме.
Представление темы
Для создания представления темы необходимо выбрать 20 лучших слов по каждой теме на основе их оценок c-TF-IDF. Чем выше оценка, тем более весомым оно должно быть в рамках своей темы, поскольку эта оценка является показателем плотности потока информации.
def extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20):
words = count.get_feature_names()
labels = list(docs_per_topic.Topic)
tf_idf_transposed = tf_idf.T
indices = tf_idf_transposed.argsort()[:, -n:]
top_n_words = {label: [(words[j], tf_idf_transposed[i][j]) for j in indices[i]][::-1] for i, label in enumerate(labels)}
return top_n_words
def extract_topic_sizes(df):
topic_sizes = (df.groupby(['Topic'])
.Doc
.count()
.reset_index()
.rename({"Topic": "Topic", "Doc": "Size"},axis='columns')
.sort_values("Size", ascending=False))
return topic_sizes
top_n_words = extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20)
topic_sizes = extract_topic_sizes(docs_df); topic_sizes.head(10)Мы можем использовать topic_sizes, чтобы узнать, насколько часто встречаются определенные темы:
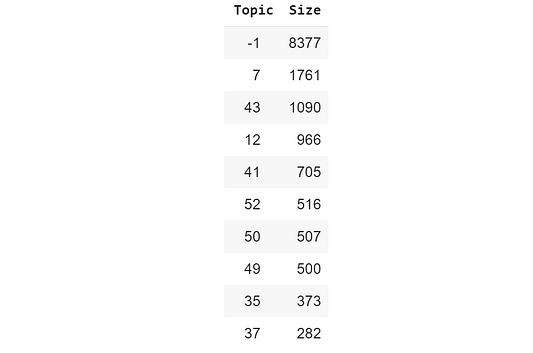
Название темы -1 относится ко всем документам, которым тема не назначена. Самое замечательное в HDBSCAN то, что не все документы направляются в конкретный кластер. Если подходящий кластер не находится, документ идентифицируется как выброс.
Темы 7, 43, 12 и 41 — это самые большие кластеры, которые у нас получилось создать. Чтобы просмотреть слова, принадлежащие к этим темам, просто используйте словарь top_n_words:

Взгляните на эти четыре группы. Я бы сказал, что нам вполне удалось получить легко интерпретируемые темы!
Среди имеющихся данных я отчетливо вижу, что мне удалось извлечь такие темы, как спорт, компьютеры, космос и религия.
5. Уменьшение количества тем
Есть вероятность, что в зависимости от набора данных вы получите сотни созданных тем! Можно настроить HDBSCAN таким образом, чтобы получать меньше тем с помощью параметра min_cluster_size, но он не позволяет указывать желаемое количество кластеров.
В Top2Vec использовали изящный трюк — возможность уменьшить количество тем путем слияния наиболее похожих друг на друга векторов тем.
Мы можем сделать нечто подобное, сравнивая векторы c-TF-IDF из числа тем, объединяя наиболее похожие из них и, наконец, повторно вычисляя векторы c-TF-IDF, чтобы обновить представления тем:
for i in range(20):
# Calculate cosine similarity
similarities = cosine_similarity(tf_idf.T)
np.fill_diagonal(similarities, 0)
# Extract label to merge into and from where
topic_sizes = docs_df.groupby(['Topic']).count().sort_values("Doc", ascending=False).reset_index()
topic_to_merge = topic_sizes.iloc[-1].Topic
topic_to_merge_into = np.argmax(similarities[topic_to_merge + 1]) - 1
# Adjust topics
docs_df.loc[docs_df.Topic == topic_to_merge, "Topic"] = topic_to_merge_into
old_topics = docs_df.sort_values("Topic").Topic.unique()
map_topics = {old_topic: index - 1 for index, old_topic in enumerate(old_topics)}
docs_df.Topic = docs_df.Topic.map(map_topics)
docs_per_topic = docs_df.groupby(['Topic'], as_index = False).agg({'Doc': ' '.join})
# Calculate new topic words
m = len(data)
tf_idf, count = c_tf_idf(docs_per_topic.Doc.values, m)
top_n_words = extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20)
topic_sizes = extract_topic_sizes(docs_df); topic_sizes.head(10)В данном примере мы взяли наименее распространенную тему и объединили ее с наиболее похожей темой. Повторив это еще 19 раз, мы сократили количество тем с 56 до 36!
ПРИМЕЧАНИЕ: Можно пропустить этап повторного расчета в этом конвейере, чтобы ускорить процесс подбора оптимального количества тем. Однако повторное вычисление векторов c-TF-IDF приводит к более точным результатам, так как оно позволяет получить лучшее представление вновь созданного набора тем. Вы можете экспериментировать, например, обновляя каждые n этапов, чтобы ускорить процесс, при этом создавая хорошие представления темы.
СОВЕТ: Используйте метод, описанный в этой статье (или просто BERTopic), чтобы создавать векторные представления на уровне предложений. Основное преимущество этого метода — возможность просматривать распределение тем в пределах одного документа.
Читайте также:
- Байесовская статистика для специалистов по данным
- Распознавание звуков с помощью глубокого обучения
- В США ограничивают использование технологий распознавания лиц
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Maarten Grootendorst: Topic Modeling with BERT.





