
Введение
Самые простые решения обычно оказываются самыми действенными, и в этом смысле показателен пример наивного байесовского алгоритма. Несмотря на большие успехи машинного обучения в последние годы, наивный байесовский алгоритм остаётся не только одним из простейших, но и одним из самых быстрых, точных и надежных. Он успешно используется для многих целей, но особенно хорошо работает с задачами обработки естественного языка.
Наивный байесовский алгоритм — это вероятностный алгоритм машинного обучения, основанный на применении теоремы Байеса и используемый в самых разных задачах классификации. В статье разберём все основные принципы и понятия, связанные с наивным байесовским алгоритмом, чтобы у вас не осталось проблем с его пониманием.
Теорема Байеса
Теорема Байеса — это простая математическая формула, используемая для вычисления условных вероятностей.
Условная вероятность — это вероятность наступления одного события при условии, что другое событие (по предположению, допущению, подтверждённому или неподтверждённому доказательством утверждению) уже произошло.
Формула для определения условной вероятности:
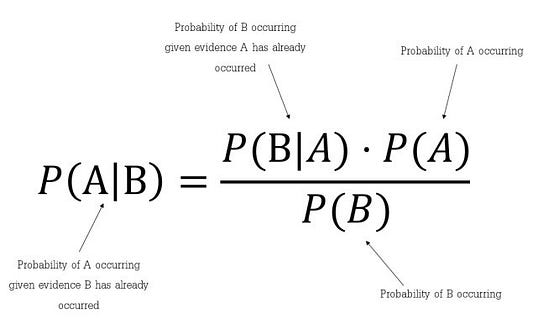
Она показывает, как часто происходит событие A при наступлении события B, обозначается как P(A|B) и имеет второе название «апостериорная вероятность». При этом мы должны знать:
- как часто происходит событие B при наступлении события A, что обозначается в формуле как P(B|A);
- какова вероятность того, что A не зависит от других событий, обозначаемая в формуле как P(A);
- какова вероятность того, что B не зависит от других событий. В формуле она обозначается как P(B).
Вкратце можно сказать, что теорема Байеса — это способ определения вероятности исходя из знания других вероятностей.
Допущения наивного байесовского алгоритма
Основным допущением наивного байесовского алгоритма является то, что каждая характеристика вносит:
- независимый и
- равный
вклад в конечный результат.
Для лучшего понимания давайте рассмотрим пример. Это будет задача для автоугонщика.
Дано: параметры автомобиля (цвет, тип, страна производства).
Найти: угнана или нет (да или нет).
Пример
Все данные представлены в этой таблице:
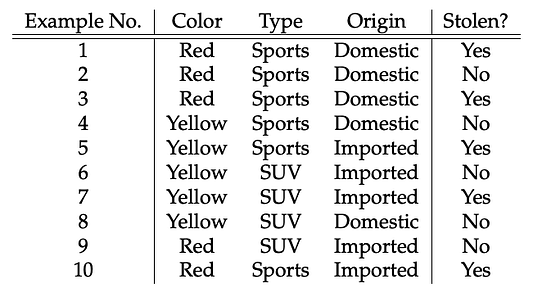
Теперь мы можем оценить характер делаемых в рамках наивного байесовского алгоритма допущений с использованием данных нашего примера:
- предположим, что среди этих параметров нет зависимых друг от друга. Например, красный цвет не имеет никакого отношения к типу или стране производства автомобиля. Отсюда первое допущение, что эти параметры являются независимыми;
- второе допущение: у каждого параметра одинаковое влияние (или важность). Например, зная только цвет и тип, нельзя предсказать результат. Ведь ни один из параметров не имеет большего или меньшего значения по сравнению с другими и все вносят равный вклад в результат.
Примечание: допущения наивного байесовского алгоритма, как правило, некорректны в реальных ситуациях. Допущение о независимости всегда некорректно, но часто хорошо работает на практике. Поэтому алгоритм и называется наивным.
Вернёмся к таблице: здесь нам надо определиться с тем, какие машины угоняются, а какие — нет, исходя из параметров автомобилей. В столбцах у нас параметры машин, а в строках — варианты с разными сочетаниями этих параметров. Если мы возьмём первую строку, то увидим: цвет — красный, тип — спортивный, страна производства — местное производство. То есть угоняется спортивная машина красного цвета, произведённая в РФ. Хм… смотри-ка, научились делать!) Ах да, это же наивный алгоритм! Теперь попробуем решить, угоняется ли красный отечественный внедорожник. Вы когда-нибудь видели этого зверя? Вот и в нашей таблице такого варианта нет.
Для целей взятого нами примера давайте перепишем теорему Байеса. Ничего криминального: просто A и B заменим на y и X.
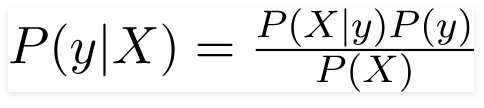
Переменная y — это переменная класса (последний столбик с ответом на вопрос, угоняется машина или нет при данных условиях). Переменной X обозначаются параметры/характеристики:
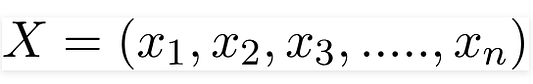
Здесь эти параметры x1,x2….xn могут представлять цвет, тип и страну производства. Подставляя X и используя цепное правило, получаем теорему Байеса вот в таком расширенном виде:
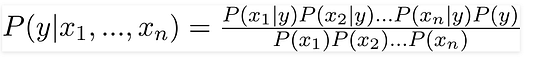
Теперь вы можете получить значения для каждого из параметров: просто берём данные и подставляем их в уравнение. Для всех вариантов сочетаний этих параметров знаменатель не меняется, он остаётся статичным. Так что его можно отбросить, введя в уравнение пропорциональность:
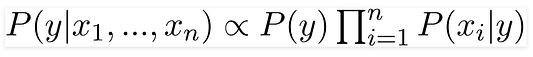
В нашем случае переменная класса (y) имеет только два результата: да или нет. А бывают случаи, когда классификация может быть многомерной. Поэтому надо найти переменную класса (y) с максимальной вероятностью.
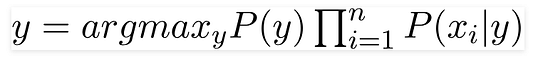
Используя эту функцию, можно получить класс, исходя из имеющихся предикторов/параметров.
Апостериорная вероятность P(y|X) высчитывается так: сначала создаётся частотная таблица для каждого параметра относительно искомого результата. Затем из частотных таблиц формируются таблицы правдоподобия, после чего с помощью уравнения Байеса высчитывается апостериорная вероятность для каждого класса. Класс с наибольшей апостериорной вероятностью и будет прогнозируемым результатом. Ниже приведены частотные таблицы и таблицы правдоподобия для всех трёх предикторов.
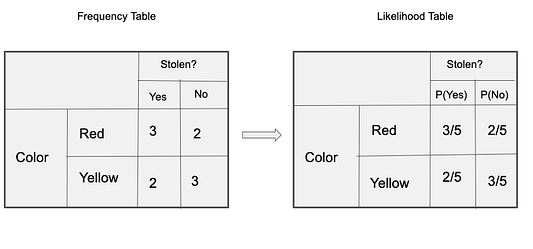
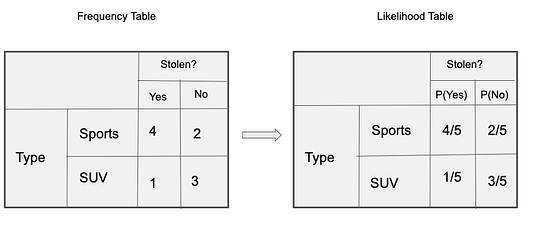
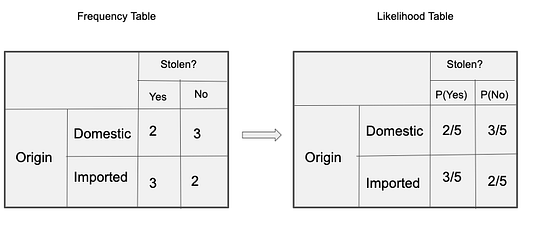
В нашем примере три предиктора X:

Подставляя значения из приведённых выше таблиц в уравнение, вычисляем апостериорную вероятность P(Yes | X):
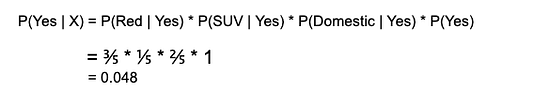
и P(No | X):

Так как 0,144 > 0,048, то для сочетания параметров RED SUV Domestic взятого нами примера (красного отечественного внедорожника) ответом на вопрос, угоняется ли машина, будет “нет”.
Проблема нулевой частоты
Одним из недостатков наивного байесовского алгоритма является то, что если класс и значение параметра не встречаются вместе, то оценка вероятности, высчитываемой с использованием частот, будет равна нулю. В итоге после перемножения всех вероятностей мы получим ноль.
В байесовской среде было найдено решение этой проблемы нулевой частоты: к каждой комбинации класса и значения параметра добавлять единичку, когда значение параметра нулевое.
Предположим, у нас есть такой набор данных:

𝑃(TimeZone=𝑈𝑆|Spam=𝑦𝑒𝑠)=10/10=1
𝑃(TimeZone=𝐸𝑈|Spam=𝑦𝑒𝑠)=0/10=0Появляется нулевое значение, поэтому при вычислении вероятностей добавляем единичку к каждому значению этой таблицы:

𝑃(TimeZone=𝑈𝑆|Spam=𝑦𝑒𝑠)=11/12
𝑃(TimeZone=𝐸𝑈|Spam=𝑦𝑒𝑠)=1/12Вот так мы избавляемся от нулевой вероятности.

Типы наивного байесовского классификатора:
- мультиномиальный: здесь векторы признаков представляют собой значения частотности, то есть частоту, с которой генерируются те или иные события посредством мультиномиального распределения. Это модель событий, обычно используемая для классификации документов;
- Бернулли: в многомерной модели событий Бернулли характеристики являются независимыми логическими значениями (двоичными переменными), которыми описываются входные данные. Подобно мультиномиальной модели, эта модель широко применяется в задачах классификации документов, где используется не частотность термина (т. е. частота встречаемости слова в документе), а бинарные характеристики встречаемости терминов (т. е. встречается слово в документе или нет);
- Гаусса: предполагается, что непрерывные значения всех характеристик имеют распределение Гаусса (нормальное распределение). При нанесении на график получается колоколообразная кривая, симметричная относительно средней значений характеристик, как это показано на рисунке ниже:
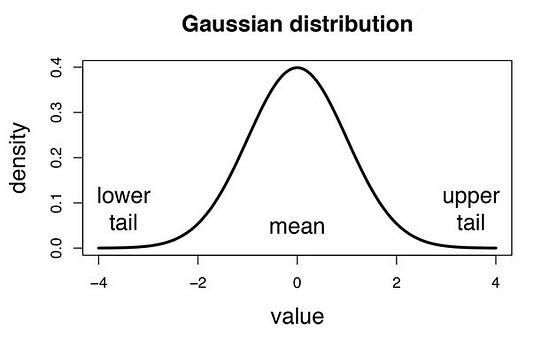
Предполагается, что это гауссова правдоподобность характеристик, поэтому условная вероятность будет определяться следующим образом:
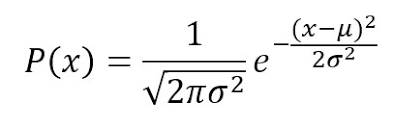
А что если в качестве характеристик будут числовые значения?
Одно из решений: перед тем как создавать частотные таблицы, нужно преобразовывать числовые значения в их категориальные аналоги. Другим решением, как было показано выше, может быть использование распределения числовой переменной с приблизительной оценкой частотности, близкой к истинной. Например, один из распространённых методов заключается в применении нормальных распределений или распределений Гаусса для числовых переменных.
Плотность распределения вероятностей для нормального распределения определяется двумя параметрами (среднее значение и среднеквадратическое отклонение) по формуле:
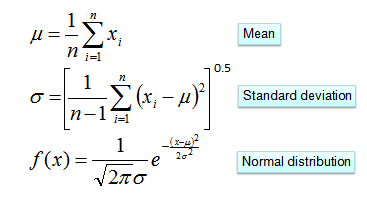
Вот вам ещё задачка, где надо решить, играть в гольф или нет. Здесь единственным предиктором является влажность, а играть в гольф? — это искомый результат в виде принятого решения. Используя эту формулу и зная среднее значение и среднеквадратическое отклонение, можно вычислить апостериорную вероятность:

Практический пример: наивный байесовский классификатор с нуля на Python
Насущной проблемой для любого крупного веб-сайта сегодня становится всё возрастающий объём проникающей на эти сайты токсичной информации. Поэтому вполне естественно желание решить эту проблему, сделав популярные платформы типа Quora местом, где пользователи могут безопасно обмениваться друг с другом своими знаниями.
Quora — это платформа, которая дает людям возможность учиться друг у друга. Здесь можно задавать вопросы, общаться, обмениваться уникальными наработками и получать квалифицированные ответы. Главная задача — отсеять фейковые вопросы, то есть те, которые не имеют отношения к существу той или иной проблемы и делаются под какими-то ложными предлогами с намерением заявить о себе или просто попиариться, а не найти полезный ответ.
Цель — разработать модель классификации на основе наивного байесовского алгоритма, которая бы выявляла и помечала такие фейковые вопросы.
Набор данных можно взять отсюда. Загрузив набор данных для обучения и тестовые данные, можно приступать к выполнению задачи.
import numpy as np
import pandas as pd
import os
train = pd.read_csv('./drive/My Drive/train.csv')
print(train.head())
test = pd.read_csv('./drive/My Drive/test.csv')
Посмотрим сначала, как выглядят реальные вопросы:

И мы можем увидеть, как выглядят фейковые вопросы:

Предварительная обработка текста
Следующий этап — это предварительная обработка текста перед разделением набора данных на данные для обучения и тестовые данные. Предварительная обработка включает в себя: удаление чисел, удаление знаков препинания в строке, удаление стоп-слов, стемминг (выделение основы слова) и лемматизацию (приведение словоформы к её базовой, словарной форме — лемме).
Построение наивного байесовского классификатора
Объединяем все методы предварительной обработки и создаём словарь слов и счётчик каждого слова в наборе данных для обучения:
- Вычисляем вероятность для каждого слова в тексте и отфильтровываем слова со значением вероятности меньше порогового. Такие слова будут нерелевантными.
- Дальше для каждого слова в словаре создаём вероятность того, что это слово окажется в фейковых вопросах. Затем определяем условную вероятность для использования её в наивном байесовском классификаторе.
- И наконец вычисляем прогнозируемый результат с помощью условных вероятностей.
Заключение
Наивные байесовские алгоритмы часто используются при анализе эмоциональной окраски текстов, фильтрации спама, в рекомендательных системах и т.д. Они легко и быстро внедряются, но их самый большой недостаток заключается в сложности соблюдения требования о независимости предикторов.
Спасибо за внимание!
Читайте также:
- Основные концепции и структуры Python, которые должен знать каждый серьёзный программист
- Галерея лучших модулей Python
- Менеджеры контекста в Python - выходим за пределы «with open() file»
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьиNagesh Singh Chauhan: Naïve Bayes Algorithm — Everything you need to know





