
Эта статья направлена на объяснение различных состояний потока в мире Java. Если вы новичок в области многопоточного программирования, попробуйте сначала почитать про потоки что-нибудь базовое.
Согласно Sun Microsystems, существует четыре состояния жизненного цикла потока Java. Вот они:
- New — поток находится в состоянии
New, когда создается экземпляр объекта классаThread, но методstartне вызывается. - Runnable — когда для объекта
Threadбыл вызван методstart. В этом состоянии поток либо ожидает, что планировщик заберет его для выполнения, либо уже запущен. Назовем состояние, когда поток уже выбран для выполнения, “работающим” (running). - Non-Runnable(Blocked , Timed-Waiting) — когда поток жив, то есть объект класса
Threadсуществует, но не может быть выбран планировщиком для выполнения. Он временно неактивен. - Terminated — когда поток завершает выполнение своего метода
run, он переходит в состояниеterminated(завершен). На этом этапе задача потока завершается.
Ниже дано схематическое представление жизненного цикла потока в Java:
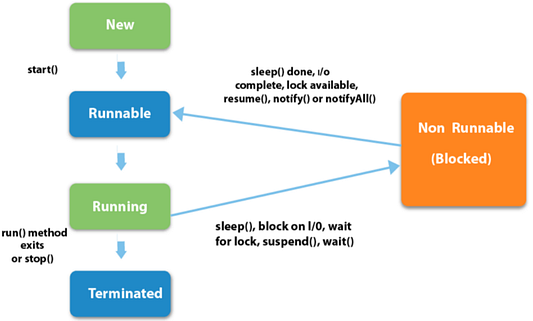
Минуточку! Звучит замечательно, но что это за “планировщик” такой? Я вызвал метод start, так почему бы системе просто не запустить мой поток, а не ждать в рабочем состоянии, пока планировщик его подберет?
Хороший вопрос! Планировщик — это программное обеспечение, которое используется для отслеживания задач компьютера. Он отвечает за назначение задач ресурсам, которые могут совершать работу. Мы не будем углубляться в логику, которую реализует планировщик. На данный момент достаточно знать, что планировщик имеет контроль над тем, какая задача должна быть назначена какому аппаратному ресурсу и когда, исходя из доступности ресурса и состояния задачи.
Выходит, планировщик решает, когда назначить задачу требуемому ресурсу. Но как задача переходит в нерабочее состояние? Как и почему поток должен отказаться от процессорного времени и приостановить выполнение? Это происходит по выбору или вынужденно?
Что же. Поток может находиться в нерабочем состоянии по разным причинам — иногда принудительно, иногда по собственному выбору. Вынужденные причины могут заключаться в том, что он ожидает операции ввода-вывода, например получения сообщения по порту, или он может ждать объект, который удерживается другим потоком. Последний сценарий приводит к появлению синхронизированного объекта. Когда поток обращается к синхронизированному объекту, он создает блокировку на этом объекте. Блокировка — это что-то вроде временного контракта между потоком и объектом, который дает потоку эксклюзивный доступ к объекту, запрещая доступ любому другому потоку. Для обеспечения этого контракта Java связывает с каждым объектом монитор. Поток также может быть перемещен планировщиком в нерабочее состояние (спящий режим) на основе логики совместного использования ресурсов планировщика.
Потоки могут перейти в нерабочее состояние по выбору. То есть по выбору программиста. Программист может написать метод потока (run или любой другой метод, который вызывается внутри run) таким образом, чтобы тот намеренно уступал процессорное время. Так делается, чтобы получить максимальную отдачу от доступных вычислительных мощностей или вызвать задержки после выполнения определенной части потока. Давайте посмотрим, какие методы добровольного отказа от процессорного времени нам доступны:
sleep(long millis)— этот метод инициирует у вызывающего потока спящий режим на время, указанное в качестве параметра. Важно отметить, что при вызовеsleepпоток отдает процессорное время, но блокировка объектов не отменяются. После выхода из спящего режима поток возвращается в рабочее состояние, ожидая, пока планировщик заберет его для выполнения. Это обычно применяется для вызова задержки в части выполнения потока.wait()илиwait(long timeout)— этот метод заставляет поток отказаться от процессорного времени, а также снять любые блокировки объектов. Он может быть вызван с параметромtimeout. При вызове без тайм-аута поток остается в неработающем состоянии бесконечно, пока другой поток не вызовет методnotify()илиnotifyAll(). При вызове с параметромtimeoutпоток ожидает не более продолжительности тайм-аута, а затем автоматически переходит в состояниеrunnable. Этот метод необходим в ситуациях, когда несколько потоков должны работать синхронно.yield()— этот метод представляет собой своего рода уведомление планировщика о том, что поток готов отказаться от выполнения. Затем планировщик, основываясь на других имеющихся потоках и их приоритетах, решает: хочет ли он переместить вызывающий поток в состояниеrunnableи предоставить процессорное время другим потокам или продолжать выполнять существующий поток. Лично мне этот метод кажется весьма полезным. Если мы знаем, что выполнение метода/функции займет много времени и что задача не является срочной, мы можем написать ее со стратегически расположенными вызовами методаyield, чтобы планировщик мог использовать процессор для выполнения потоков с более высоким приоритетом и более коротким временем выполнения.join()— вызывается для приостановки выполнения программы до тех пор, пока поток, вызывающий методjoin, не будет завершен.
Время запачкать руки! Напишем-ка небольшой код, чтобы создать пару потоков и проверить их состояние на протяжении всего выполнения.
Простое выполнение единственного потока
package multithreadingPackage;
class Thread1 implements Runnable{
@Override
public void run() {
System.out.println("We are inside the run function."
+ "The thread is in the \"" + Thread.currentThread().getState() + "\" state.");
}
}
public class BasicThreadLifeCycleDemo{
public static void printThreadState(Thread threadToCheck) {
System.out.println("The thread is in the \"" + threadToCheck.getState() + "\" state.");
}
public static void main(String[] args) {
Thread t1 = new Thread(new Thread1());
printThreadState(t1);
t1.start();
printThreadState(t1);
for(int i=0; i<=10000; i++) {
for(int j=0; j<=10000; j++) {
}
}
printThreadState(t1);
}
}Этот код выведет следующее:

Давайте попробуем понять, что здесь происходит.
Функция printThreadState выводит текущее состояние потока. Впервые она вызывается после создания экземпляра объекта Thread, и ее вывод соответствует тому, что мы узнали недавно. Поток оказался в состоянии new. Теперь внимательно наблюдайте за выводом.
После метода start мы выполнили метод printThreadState, и поток перешел в состояние runnable. Это происходит до того, как планировщик передал поток для выполнения, потому что если бы поток уже был запущен, мы получили бы в выводе инструкцию print, написанную внутри метода run класса Thread1. Отсюда можно видеть, что поток выполняется.
Обратите внимание, что поток так и находится в состоянии runnable, поскольку, как упоминалось в начале этой статьи, Java определяет только четыре состояния в жизненном цикле потока. Состояние running фигурирует в этой статье только для упрощения понимания.
Наконец, после завершения выполнения метода run, поток тоже завершается, а затем уничтожается. Циклы for в программе существуют только затем, чтобы дать потоку достаточно времени для завершения выполнения.
2. Выполнение нескольких потоков
1. Влияние синхронизации
Теперь давайте рассмотрим сценарии с синхронизированными блоками кода. Мы напишем программу для запуска двух потоков, которые пытаются получить доступ к одному и тому же экземпляру класса. Мы запустим программу дважды: один раз без ключевого слова synchronized в объявлении метода и один раз с ключевым словом synchronized.
package multithreadingPackage.objectsForDemo;
public class Person implements Runnable {
private String name;
private String job;
private String address;
public Person(String name, String job, String addr){
this.name = name;
this.job = job;
this.address = addr;
}
/*Non-synchronized version.
To convert this to synchronized block, replace method declaration with
public synchronized void printPersonDetails(){ */
public void printPersonDetails() {
String threadName = Thread.currentThread().getName();
System.out.println("-------------------------------");
System.out.println(threadName + " holds lock?- " + Thread.currentThread().holdsLock(this));
System.out.println(threadName + " Name - " + this.name);
System.out.println(threadName + " Job - " + this.job);
System.out.println(threadName + " Address - " + this.address);
System.out.println("-------------------------------");
}
@Override
public void run() {
printPersonDetails();
}
}
package multithreadingPackage;
import multithreadingPackage.objectsForDemo.Person;
public class SynchronizationDemo{
public static void printThreadState(Thread threadToCheck) {
System.out.println("Thread \"" + threadToCheck.getName() + "\" is in the \"" + threadToCheck.getState() + "\" state.");
}
public static void main(String[] args) {
Person person = new Person("Rajat", "Blogger", "Ireland");
Thread t1 = new Thread(person);
t1.setName("FirstThread");
Thread t2 = new Thread(person);
t2.setName("SecondThread");
t1.start();
t2.start();
}
}На рис. 3 показан вывод без ключевого слова synchronized, а на рис. 4 — с ключевым словом synchronized.


Почему вывод такой рандомный? 🤔
Потому что два потока выполняются параллельно. Обратите внимание: статус блокировки потоков четко false, поэтому любой поток может получить доступ к объекту в одно время.
А поскольку мы использовали ключевое слово synchronized для получения вывода на рис.4, то первый поток, получивший доступ к объекту, удерживал его блокировку. Это преграждало другому потоку доступ к объекту до завершения выполнения первого потока.
Вот так-то!
2. Методы “sleep” и “yield”
public void printPersonDetails() {
String threadName = Thread.currentThread().getName();
System.out.println("-------------------------------");
System.out.println(threadName + " holds lock?- " + Thread.currentThread().holdsLock(this));
if(threadName.equals("FirstThread")) {
try {
Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(threadName + " Name - " + this.name);
System.out.println(threadName + " Job - " + this.job);
System.out.println(threadName + " Address - " + this.address);
System.out.println("-------------------------------");
}
public static void main(String[] args) {
Person person = new Person("Rajat", "Blogger", "Ireland");
Thread t1 = new Thread(person);
t1.setName("FirstThread");
Thread t2 = new Thread(person);
t2.setName("SecondThread");
t1.start();
t2.start();
for(int i=0; i<=10000; i++) {
for(int j=0; j<=10000; j++) {
}
}
printThreadState(t1);
}Измените код в файлах SynchronizationDemo.java и Persons.java, как показано в вышеприведенном фрагменте кода. Запустите код как в синхронизированном, так и в несинхронизированном режимах. Мы переводим первый поток в спящий режим на две секунды, как только начинается его выполнение.

Как и ожидалось, в несинхронизированном режиме оба потока не удерживают никакой блокировки на объекте. FirstThread переходит в Timed_Waiting при вызове метода sleep. Второй поток продолжает выполнение, так как нет блокировки его доступа к объекту.
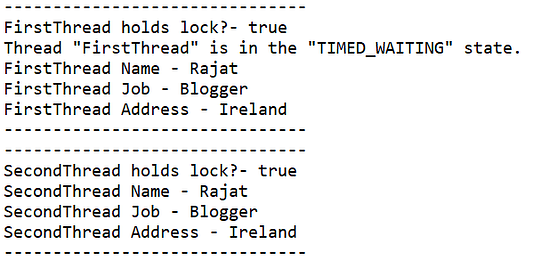
В синхронизированном режиме потоки удерживают блокировки, и поэтому, даже когда первый поток находится в состоянии Timed_Waiting, второй поток все равно не может получить доступ к объекту.
Теперь замените метод sleep на yield и удалите блок try-catch в файле Persons.java. Результат будет таким же, как и в разделе 2.1. Этот метод будет полезен для задач, требующих больших вычислительных мощностей, но меньшей срочности.
3. Методы “wait” и “notify”
Что делать, если мы не хотим, чтобы поток заканчивал выполнение, пока какой-то другой поток не скажет ему продолжить?
Зачем это нам?
Допустим, у нас есть учетная запись у поставщика широкополосных сетевых услуг и мы хотим добавить на баланс еще данных. Если у нашей учетной записи недостаточно средств, мы не сможем пополнить счет для передачи данных. Таким образом, поставщик услуг будет ждать, пока мы добавим на аккаунт средства, чтобы завершить дозакупку. Давайте взглянем на код.
package multithreadingPackage;
class BroadbandAccount{
private double dataInGb;
private double moneyInEuros;
public BroadbandAccount(double data, double money){
this.dataInGb = data;
this.moneyInEuros = money;
}
public synchronized void addData() {
System.out.println("Current balance = " + this.moneyInEuros);
if(moneyInEuros<20) {
System.out.println("You don't have enough balance. Waiting for you to add money");
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("Adding data and deducting money");
this.moneyInEuros -= 20;
this.dataInGb += 20;
System.out.println("Remaining Balance = " + this.moneyInEuros + ". Remaining data = " + this.dataInGb);
}
public synchronized void addMoney() {
System.out.println("Adding 20 Euros");
this.moneyInEuros += 20;
System.out.println("Added. New balance = " + this.moneyInEuros);
notify();
}
}
public class WaitNotifyImplementationDemo{
public static void main(String[] args) {
BroadbandAccount account = new BroadbandAccount(1, 10);
new Thread() {
public void run() {
account.addData();
}
}.start();
new Thread() {
public void run() {
account.addMoney();
}
}.start();
}
}Обратите внимание, что методы потока синхронизированы, поэтому только один поток единовременно может получить доступ к объекту BroadBandAccount. Вывод этого кода будет зависеть от того, какой поток был выбран планировщиком первым. Если второй поток, то есть поток добавления денег, будет выполнен первым, то денег будет достаточно для пополнения счета и следующему потоку в мониторе объекта, то есть потоку пополнения, не придется ждать (переходить в нерабочее состояние). Однако, если поток add data выполняется первым, он будет переведен в нерабочее состояние из-за недостаточного баланса и будет ждать завершения выполнения потока add money и вызова метода notify. Как думаете, что произойдет, если вы не вызовете метод notify в последнем сценарии? Попробуйте разобраться сами 😉.

Кроме того, вы заметили другой стиль создания экземпляра объекта Thread? Это происходит потому, что в классе может быть только один метод run. Я хотел выполнить два разных метода того же класса, что и потоки, поэтому динамически определил разные методы запуска для обоих потоков.
4.Метод “join”
Метод join используется, когда мы хотим остановить выполнение программы до тех пор, пока вызывающий поток не завершит выполнение. Можете ли вы представить себе такой сценарий?
Рассмотрим объект Person, который мы приводили как пример выше. Допустим, Job и Address — это не просто строковые значения, а объекты. Что если у них есть свои собственные таблицы базы данных и их значения оттуда нужно извлечь, чтобы отобразить фрагменты информации о человеке Person? У нас может быть два потока, которые создают связи с каждой таблицей — работы и адресы, — извлекают записи в соответствии с конкретным Person, а затем отображают полные сведения о человеке. Но здесь нужна осторожность. Если мы извлекаем данные с помощью потоков, а затем создаем экземпляр объекта Person с этими значениями, нет гарантии, что потоки извлекут данные к моменту, когда выполнится команда создания экземпляра объекта. Вот тут-то на сцене и появляется join. Взгляните на приведенный ниже код:
package multithreadingPackage;
class Address implements Runnable {
private String address;
public String getAddress() {
return address;
}
public Address(){
}
@Override
public void run() {
this.address = "Dublin";
}
}
class Job implements Runnable {
private String job;
public String getJob() {
return job;
}
public Job() {
}
@Override
public void run() {
try {
Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
this.job = "Software Developer";
}
}
class Person{
private String name;
@Override
public String toString() {
return "Person [name=" + name + ", job=" + job.getJob() + ", address=" + address.getAddress() + "]";
}
private Job job;
private Address address;
public Person(String name, Address address, Job job) {
this.name = name;
this.address = address;
this.job = job;
}
}
public class JoinImplementationDemo{
public static void main(String[] args) {
Address address = new Address();
Thread tAddress = new Thread(address);
Job job = new Job();
Thread tJob = new Thread(job);
tJob.start();
tAddress.start();
try {
tAddress.join();
tJob.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
Person person = new Person("Rajat", address, job);
System.out.println(person.toString());
}
}Вывод без join:Person [name=Rajat, job=null, address=Dublin]
Вывод с join:Person [name=Rajat, job=Software Developer, address=Dublin]
Обратите внимание на результаты и сравните их. Я добавил метод sleep в поток Job, чтобы увеличить время выполнения и более наглядно продемонстрировать результаты. Без вмешательства join, выполнение не ждет, когда потоки завершат выполнение, и создает объект Person. В результате объект содержит значение null в атрибуте job. Тогда как, когда мы использовали метод join, все отработало гладко. Проще говоря, распараллеливание задач, требующих большой вычислительной мощности, сокращает общее время выполнения, но надо быть осторожным, чтобы в процессе не потерять какую-то информацию. Метод join — один из лучших инструментов для этого.
Занимаясь многопоточным программированием, я провел много лет в поисках идеального способа реализации, и это было трудно. Итак, я попытался объяснить вам многопоточное программирование. Рекомендую поиграть с кодом из этой статьи, чтобы исследовать его глубже и укрепить свое понимание предмета.
Все, что вам нужно, — практика👍.
Читайте также:
- Функции Java 15: скрытые и запечатанные классы, сопоставление шаблонов и текстовые блоки
- Учимся избегать null-значений в современном Java. Часть 1
- Фреймворк Executor в Java
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи: Rajat Gogna, “Thread Life Cycle — Java”





