
Привет, меня зовут Джейсон
Я специалист по обработке данных (чуть позже в статье это понятие будет определено конкретнее) в Кремниевой долине, и мне очень нравится расширять горизонты своих знаний!
Вступление
Эта тема уже долгое время не выходит у меня из головы, но т.к. охватить в ней нужно очень многое, то я никак не мог заставить себя завершить эту нелёгкую задачу. Однако, оказавшись в вынужденной самоизоляции и исчерпав занятия, на которые можно было тратить время, я наконец-то до неё добрался.
С момента скачка своей популярности, индустрия обработки данных широко развивалась и при этом неспеша выливалась в более конкретные направления. Это неизбежно приводило к замешательствам и непоследовательным проявлениям на рынке труда. Например, существует много, казалось бы, разных должностей с одинаковыми обязанностями и, наоборот, одинаковых должностей с разными обязанностями:
Специалист по обработке данных, специалист по машинному обучению, инженер по обработке данных, аналитик/специалист по обработке данных, инженер машинного обучения, аналитик машинного обучения и т.д.
Список можно продолжать. Даже я сталкивался с тем, что рекрутеры обращались ко мне в поиске аналитика данных, специалиста по машинному обучению, инженера данных и пр. Очевидно, что индустрия находится в спутанном состоянии. Одна из многих причин такой её вариативности в том, что разные компании преследуют разные цели, связанные с наукой о данных. В итоге выясняется, что, независимо от причины, эта область разветвляется и выливается в ряд основных категорий: аналитика, проектирование ПО, обработка данных и исследования. Как бы ни звучали названия схожих должностей в этой сфере, чаще всего они подпадают именно под эти категории. Такая специализация по направлениям наиболее характерна для крупных технологических компаний, которые могут себе её позволить.
В этой статье мы сначала рассмотрим тренд индустрии обработки данных в целом, а затем более углублённо сравним инженера ML (машинного обучения) и специалиста по обработке данных. Я собираюсь не излагать подробную историю, а просто поведать о том, что видел и что пережил сам, работая специалистом по обработке данных в Кремниевой долине. К тому же, когда я в 2017 году писал статью “How to Data Science Without a Degree” (“Как заняться обработкой данных, не имея ученой степени”), мой взгляд на эту область был совершенно другим.
В прошлом году я рассматривал эту тему, когда меня пригласили провести короткую беседу со студентами в Metis Bootcamp. Хочу использовать эту возможность, чтобы объяснить разницу и помочь вам найти для себя максимально подходящую роль в этой области. Давайте выясним, до сих пор ли она процветает или же наоборот начинает угасать, ведь именно этим и занимаются аналитики данных? (А может и нет). Как бы то ни было, надеюсь, она по меньшей мере окажется для вас полезной и информативной.
Тренд индустрии обработки данных
Для начала давайте взглянем на два следующих описания вакансий, найденных мной на LinkedIn. Попытайтесь угадать, какие должности они описывают. В качестве подсказки я выделил ключевые аспекты красным:
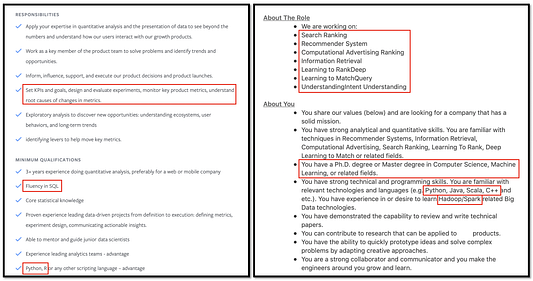
Существенно отличаются, не так ли? На удивление, обе они описывают вакансии специалиста по обработке данных. Слева вакансия для Facebook, справа — для Etsy. Я не имею в виду, что одна лучше другой. Суть в том, чтобы заметить, насколько они различны.

Даже в процессе работы люди активно обсуждают, пытаясь выяснить конкретно, что определяет специалиста по обработке данных. Я встречал его описание как имеющего докторскую степень в компьютерной науке или являющегося аналитиком новых типов данных. Всё это потому, что разные компании используют выражение специалист по обработке данных для совершенно разных должностей. Тем не менее я верю, что индустрия постепенно учится и в плане специализированных должностей становится более конкретной, переставая всё подряд определять в один обширный диапазон науки по обработке данных.
Итак, какие же, например, роли может воплощать специалист по обработке данных? Я думаю, что в основном к ним относятся разработчики ПО, аналитики данных, инженеры по работе с данными и прикладные специалисты/специалисты по исследованиям. У меня есть знакомые, работавшие на одинаковых должностях специалистов по обработке данных, но при этом они выполняли одну из четырёх перечисленных ролей. Ознакомьтесь с диаграммой, приведённой ниже. На заре становления науки о данных, её специалист мог включать в себя все эти четыре роли. Как бы то ни было, диаграмма показывает, что на сегодня вакансии становятся более конкретными и специализированными:
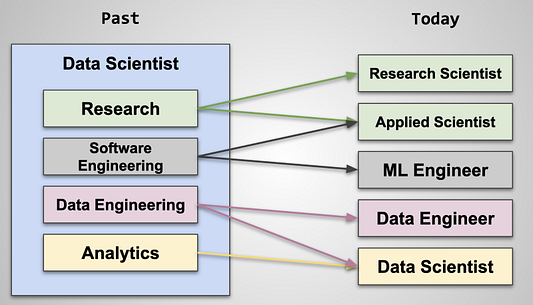
Предвидел ли это журнал Harvard Business Review
Стала ли такая тенденция сюрпризом? Согласно известной статье “Data Scientist: The sexiest Job of the 21st Century” (“Специалист по обработке данных: самая сексуальная работа 21 века”), не особо:
Самый основной навык специалиста по обработке данных заключается в способности писать код, что может измениться уже лет через пять, когда это звание будет красоваться на визитках очень многих людей.
В упомянутой статье предполагается, что сегодня, как у специалиста по обработке данных, у вас уже меньше причин иметь хорошие навыки именно в написании кода. Ранее инструменты и методы для анализа больших и сложных данных не были настолько доступны, как сегодня. В связи с этим подобным специалистам, помимо прочих, требовался относительно развитый навык проектирования. Но инструменты для машинного обучения и обработки данных быстро развивались и теперь стали существенно доступнее. К примеру, вы можете обратиться к современным моделям (SOTA) при помощи всего нескольких строк кода. Это облегчает разделение ролей на аналитиков и инженеров. Теперь для того, чтобы стать специалистом по обработке данных, вам нет необходимости погружаться в изучение всей аналитики, проектирования и статистики, что требовалось ранее.
К примеру, Facebook возглавили тренд, вследствие которого должность аналитика данных преобразовалась в специалиста по обработке данных. Это был естественный процесс, потому что с повышением размера данных и возникновением более серьёзных задач в их обработке, для выполнения качественного анализа стало требоваться больше навыков. Не только Facebook, но и многие другие компании, наподобие Apple и Airbnb, стали более чётко разграничивать специалистов по данным о продукте/аналитиков и специалистов по машинному обучению.
Влияние размера компании на роли
Стоит упомянуть, что распределение специализаций больше проявляется в крупных технологических компаниях. В отличие от инженеров ПО, которые требуются в компаниях любой величины, не все они нуждаются в специалистах по исследованию и инженерах машинного обучения. Зачастую нескольких специалистов по работе с данными может быть достаточно. Поэтому в мелких организациях по-прежнему существуют такие специалисты, работающие во всех четырёх ролях.
Согласно общей тенденции, специалисты по обработке данных в крупных компаниях (FANG) часто аналогичны продвинутым аналитикам, в то время как эти же должности в более мелких организациях ближе по своей сути к инженерам машинного обучения. При этом обе функции важны и востребованы. Далее я буду придерживаться своих новых определений, согласно которым специалист по обработке данных подразумевает аналитическую функцию.
Разные специалисты по обработке данных и выбор между ними
В приведённой ниже диаграмме я попытался показать картину, аналогичную приведённой выше, но представляющую все четыре роли более детально. Описания не идеальны, но на них можно опереться.
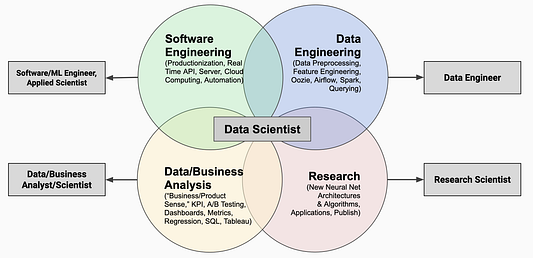
Поиск работы— какую специальность выбрать и как подготовиться?
Если вы стараетесь попасть в эту область, будь то инженером по машинному обучению или аналитиком данных, вы можете призадуматься, а какое направление лучше выбрать? Позвольте мне перечислить упрощённые (и стереотипные) описания четырёх основных ролей, относящихся к машинному обучению. Хоть я лично и не работал во всех этих направлениях, но получил достаточно внутренней информации от своих друзей. Кроме того, в скобках я привёл потенциальное содержание собеседования (рассматривайте его, как четыре этапа).
- Аналитик данных: хотите анализировать большие данные, проектировать экспериментальные работы и тесты A/B, создавать простые модели машинного обучения и статистики (например, используя sklearn) для ведения бизнес-стратегии? Эта роль менее структурирована, имеет много неопределённостей и предполагает полное сопровождение целей проекта. (Собеседование: 1 Вероятность/Статистика, 1 Leetcode, 1 SQL, 1 ML).
- Инженер машинного обучения: хотите создавать и развёртывать современные модели машинного обучения в продакшене (например, с помощью TensorFlow или PyTorch)? Ваша задача не только в создании моделей, но также и ПО, необходимого для их выполнения и поддержки. В этой роли вы ближе к разработчику ПО (SWE). (Собеседование: 3 Leetcode, 1ML).
- Специалист по исследованиям: у вас есть степень в компьютерных науках и несколько публикаций по машинному обучению в ICLR (Международная конференция по обучению представительств)? Хотите расширить границы разработки в сфере ML и испытываете восторг, когда кто-либо цитирует ваши статьи? Тогда вы относитесь к редкому виду и уже наверняка знаете себе цену. Большинство таких людей в итоге оказываются в Google и Facebook. Хотя попасть в эти корпорации можно и без докторской степени, но это уже исключение. (Собеседование: 1 Leetcode, 3 ML/Исследования).
- Прикладной специалист: вы воплощаете в себе смесь инженера машинного обучения и специалиста по исследованиям. Вы интересуетесь кодом, но также используете и продвигаете новейшие модели (SOTA) машинного обучения. (Собеседование: 2 Leetcode, 2 ML).
Очевидно, что приведённые описания не исчерпывающие. Но, когда я беседую с друзьями и читаю описания схожих вакансий, то понимаю, что эти принципы являются для них общими. Если вы ещё не уверены, на какую именно роль претендуете, то вот несколько дополнительных подсказок:
- Прочтите описание вакансии: само название должности не столь важно. Звучать оно может одинаково “специалист по обработке данных”, но описание при этом будет сильно отличаться.
- Изучите LinkedIn: если вы не уверены, чем занимаются специалисты по обработке данных в Apple, то просто почитайте бэкграунд этих специалистов на LinkedIn. Являются ли они в своём большинстве кандидатами компьютерных наук? А может студентами выпускного курса? Какие навыки они имеют? Это поможет вам сформировать лучшее представление.
- Собеседование: если вы думаете, что ваша роль предполагала технический характер, но на собеседовании вам не задавали вопросов по написанию кода, то, вероятно, вы получите роль другого плана. Собеседование наиболее конкретно отражает суть должности.
Инженер машинного обучения или аналитик данных?

Всё это ознакомление заняло прилично времени. Давайте же теперь вернёмся к самой теме. В последние годы я слышу, как люди начали негативно отзываться о работе в области науки о данных. Несколько причин упираются в то, что всё большее число должностей аналитиков данных не подразумевают наличия интересного фактора машинного обучения и кажутся лёгкими для освоения. Около пяти лет назад большинство описаний вакансий специалистов по обработке данных требовали от соискателей по меньшей мере степень магистра. Сейчас же всё иначе. Но, какой бы ни была причина, по которой люди считают, что наука о данных (по крайней мере былая) дожила свой век, давайте просто рассмотрим некоторую статистику.
Нижеприведённая информация и диаграмма взяты из всемирно известного движка базы данных о зарплатах — Salary Ninja. Он выполняет поиск в базе данных H1-B, взяв за критерий иностранных сотрудников, работающих в США. Здесь вы видите среднюю зарплату и число должностей “специалист по обработке данных” или “инженер машинного обучения” в период с 2014 по 2019.

Удивлены? Несмотря на то, что средняя зарплата в обоих случаях примерно одинакова, можно заметить, что, по сравнению с 2015–2016 годами, для аналитиков данных она снизилась. Возможно, это люди и имеют в виду, говоря про хорошие времена этой должности. С точки же зрения чистого количества наука о данных существенно крупнее проектирования машинного обучения, но вы можете видеть, что число инженеров ML быстро увеличивается и они имеют несколько большую зарплату.
Я также включил в статью сводную статистику, собранную мной там же на Salary Ninja. В ней я привожу несколько направлений, о которых мы говорили выше. В первой таблице представлен обобщённый отчёт за последние шесть лет, а во второй — его продолжение за последний 2019 год. В конце я добавил таблицу для всего одной компании, Microsoft.
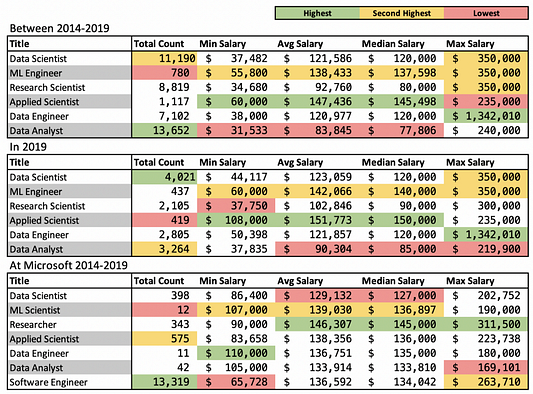
Я открыл для себя несколько интересных фактов:
- В целом аналитиков данных было больше, чем специалистов по работе с ними, но в 2019 году всё стало наоборот. Можно ли это считать признаком того, что аналитики данных теперь стали специалистами по обработке данных?
- Инженеры машинного обучения получают денег несколько больше специалистов по обработке данных, но таких инженеров в этой области существенно меньше. Причина в том, что официально должность инженера машинного обучения чаще звучит как разработчик ПО.
- Средняя зарплата для специалистов по исследованиям оказалась удивительно низкой. Причина в том, что база данных может включать много других специалистов по исследованиям, кроме интересующих нас в сфере машинного обучения. Именно поэтому для снижения “шумности” данных я добавил таблицу для одной компании. Как и ожидалось, в Microsoft исследователи заняли лидирующую позицию по зарплатам.
- Меня сильно удивила базовая зарплата инженера по работе с данными в районе $1,3 млн. Это же с ума сойти! Может вам стоит рассмотреть именно такую карьеру?
- Учитывайте, что эта выборка данных содержит только базовую зарплату, а акции обычно играют существенную роль в мире технологий. Кроме того, здесь отражена далеко не полная картина рынка труда. Однако, учитывая, сколько иностранных сотрудников работает в сфере технологий, это всё равно является неплохим показателем.
Согласно приведённым данным, я не могу сказать, что индустрия науки о данных терпит крах. Она по-прежнему растёт, но, возможно, с большим уклоном в аналитику. Исходя из наблюдений, могу отметить, что, похоже, в области данных на самом деле есть ряд должностей, требующих меньшее число навыков, но это и не плохо.
Заключение
Я проговорил о многом и, надеюсь, вы с интересом следовали моей мысли. Эту статью я решил написать, потому что и сам начал путаться во всех изменениях, происходящих в индустрии. Кроме того, стало очевидно, что у людей складываются разные мнения относительно сути науки о данных. Не проводя разделения на правых и неправых, мне хочется, чтобы вы сами проанализировали тенденцию и сделали свой сознательный выбор.
В итоге я не рекомендую вам выбирать работу или сферу деятельности, опираясь лишь на высокую зарплату или красивые названия. Не важно будет ли ваша должность звучать как специалист по обработке данных, инженер машинного обучения или аналитик данных. Также не имеет значения, если кто-либо скажет, что специалист по обработке данных — это инженер или аналитик, потому что и то, и другое верно.
Несмотря на то, что легко сравнивать должности на основе оплаты, гораздо важнее выбирать то направление, которым в итоге вы будете наслаждаться и в котором станете профессионалом. Сосредоточьтесь на выполняемой вами работе и убедитесь, что она вам подходит. Если даже средняя зарплата и окажется ниже, это ещё не значит, что фактически вы будете получать меньше. Как вы видели, все рассмотренные роли предполагают весьма внушительные максимальные зарплаты.
Благодарю вас за чтение. Надеюсь, что эта статься даст вам необходимые ориентиры, которые не позволят заплутать в дебрях мира науки о данных и машинного обучения.
Читайте также:
- Когда ИИ или машинное обучение неуместны
- Лучшие фреймворки для ИИ и машинного обучения в веб-разработке
- Пять отличных Python-библиотек для data science
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Jason Jung: Machine Learning Engineer vs Data Scientist (Is Data Science Over?)





