
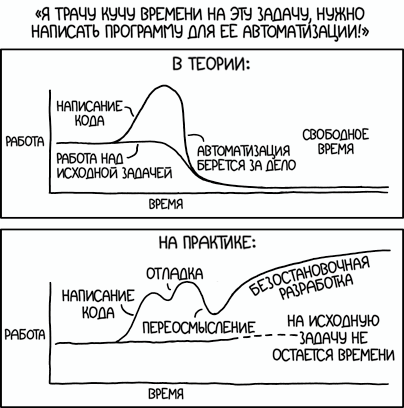
Я склонен попадать в ловушку, пытаясь автоматизировать все подряд.
Изучение и внедрение чего-то нового — это очень весело. Особенно если вы новичок в программировании: всё выглядит так, словно вы заставляете ваш компьютер творить магию. Но иногда автоматизация не нужна и контрпродуктивна.
Филиппинская еда: проект, который нуждался в автоматизации
В качестве личного проекта я решил извлечь все рецепты с филиппинского сайта с рецептами “Panlasang Pinoy”. Конечный продукт представлялся мне в виде электронной таблицы Excel, которая объединяла бы все данные по рецептам с этого сайта. Таким образом, каждый раз, когда мне захочется приготовить что-нибудь новое, я обращался бы к файлу у себя на компьютере.
Вручную извлечь пару тысяч рецептов было бы невыполнимой задачей. Вместо этого я хотел попробовать использовать Scrapy, библиотеку Python для веб-скрейпинга. Я просмотрел документацию и подумал, что смогу что-нибудь придумать за пару часов.
После прочесывания HTML, изучения селекторов Xpath и того, что делает “yield”, я запустил своего первого “паука”. Меня встретили ошибкой. После небольшой отладки я понял, что пропустил пару обязательных назначений переменных. Через 15 минут мой “паук” запустился без ошибок и извлек каждый рецепт в файл Excel.
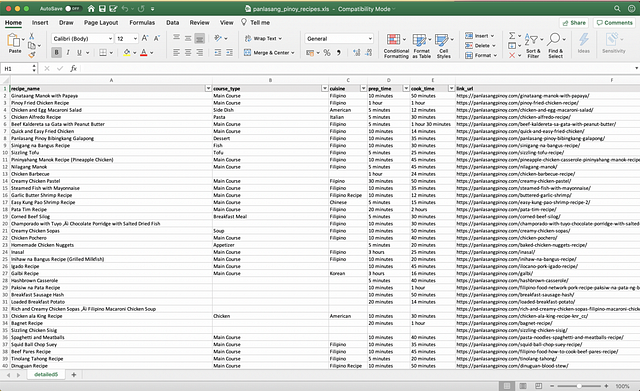
Моя конечная цель была проста, вот почему потребовалось всего несколько часов, чтобы перейти от ничего к “конечному продукту”. Несмотря на свою простоту, файл был легким в использовании и служил в качестве основной компиляции продуктов питания. После небольшого форматирования в Excel я разместил данные в группе “Subtle Filipino Traits” на Facebook.
Этот быстрый проект дал мне возможность решить задачу, которая требовала автоматизации. Многие советы, которые я читал в процессе обучения программированию, заключаются в том, чтобы создавать свои собственные проекты. Одно из предложений состояло в том, чтобы посмотреть на все, что вы делаете, и попытаться автоматизировать каждую задачу, даже если вам это не нужно. Таким образом, вы улучшите свои знания с помощью подхода “учись на практике”. В этом случае я даже не смог бы завершить свой проект, не написав код. Это оправдывало часы, потраченные на обучение настройке и развертыванию “паука”.
Автоматизация всего может быть отличным вариантом для обучения, но это, возможно, не самый эффективный способ получения результатов.
Индекс AEX и COVID-19: проект, который не нуждался в автоматизации
Недавно мне захотелось проследить, как работает индекс Амстердамской биржи (AEX) во время вызванного COVID-19 карантина.
Моей конечной целью для этого проекта было создать дашборд Tableu с ключевыми показателями эффективности и визуализациями по трем категориям данных:
- цена индекса AEX в динамике;
- новостные статьи, которые могут объяснить колебания рынка;
- число случаев коронавируса в Нидерландах.
Данные всех трех категорий представлены в различных источниках в интернете. Моей целью было создать дашборд, чтобы как можно быстрее составить представление о ситуации. Поэтому моим приоритетом было анализировать данные и не тратить слишком много времени на их сбор. Проект не нуждался в специально написанном “пауке”, но я подумал, что мой опыт поможет при сборе данных.
Вот как проходил у меня сбор данных:
1. Данные по индексу AEX
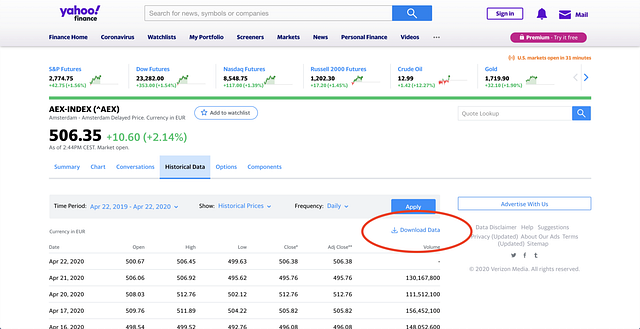
На вкладке “Исторические данные” (“Historical Data”) для AEX вся ценовая информация доступна через кнопку “Загрузить данные”. Я тогда даже не пытался проверять HTML, потому что мне это было не нужно. Я просто установил фильтры по дате и инициировал загрузку. Затем я напрямую подключил этот Excel-файл к Tableau.
Время выполнения: <5 минут
2. Случаи COVID-19
К настоящему времени все, вероятно, видели информационную панель по COVID-19 от Центра системных наук и инженерии университета Джона Хопкинса.
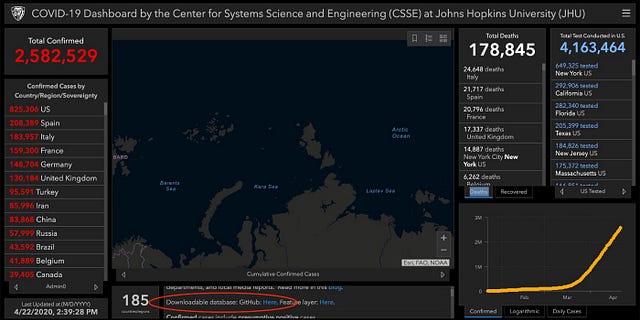
По наитию я поискал на этой странице слово “Github” и нашел их репозиторий. Я перешел к нему, пытаясь найти еще один файл Excel, теперь со всеми случаями коронавируса. Я оказался в другом репозитории, где кто-то преобразовал необработанные данные от Джона Хопкинса в формат csv.
Я скачал этот csv, выполнил проверку, чтобы убедиться, что все данные на месте, а затем загрузил в Tableau.
Время выполнения: 20 минут
3. Пресс-релизы компаний по индексу AEX
Я оставил это напоследок, потому что знал: здесь мне понадобится больше времени, чтобы разобраться. Я начал с проверки обычных новостных сайтов и ввода “AEX” и “Corona” в качестве ключевых слов. Большая часть результатов по этим запросам не могла объяснить тенденцию колебаний индекса AEX. Тогда я решил использовать пресс-релизы компаний и квартальные отчеты.
В индекс AEX включены 25 компаний. Я не хотел заходить на каждый сайт, кликать по нему, пока не отыщется страница “Медиа”, а затем копировать и вставлять все, что я там нашел, в лист Excel. В качестве теста я попробовал обработать так один сайт, и это заняло около пяти минут. Немного быстрых вычислений в уме — и я пришел к выводу, что определенно не хочу тратить 2,08 часа на копирование и вставку материала.
После этого я зашел на сайт Euronext (фондовая биржа) и кликнул на одну из компаний в индексе. Я обнаружил, что на главной странице компании есть вкладка “Регулируемые новости”, где отображаются последние пресс-релизы.
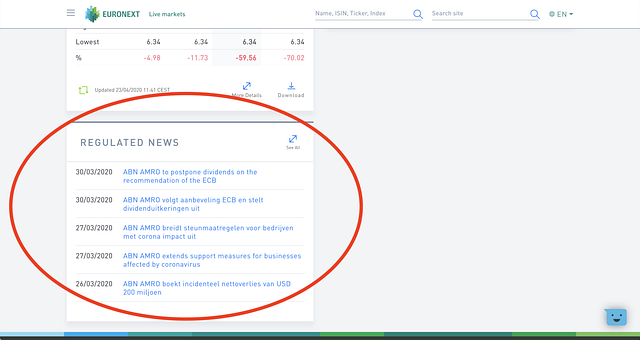
Основной сайт полагался на JavaSсript для загрузки его частей. Поскольку Scrapy не может парсить сайты с JavaSсript, я не мог написать “паука”, чтобы проползти им весь сайт(1). Однако когда я нажимал на вкладку “Пресс-релизы” для каждой компании, сайт, куда меня перенаправляло, не содержал никакого JavaSсript! Кроме того, для доступа к любой компании на сайте Euronext необходимо было изменить только одну подстроку в URL-адресе.
После этого я решил, что смогу быстро написать “паука” и получить все необходимые пресс-релизы для каждой компании.
Итак, я приступил к делу. Я настроил виртуальную среду, установил Scrapy и проверил, будут ли серверы блокировать меня в защите от скрейпинга. Я инициализировал базовый шаблон “паука”, а затем открыл свой браузер, чтобы проверить сайт.
Форматирование HTML сначала выглядело нормально, но потом я понял, что есть пара проблем:
- Некоторые названия пресс-релизов были не на английском языке, а это значило, что мне нужно будет выяснить, как их перевести.
- Не все заголовки принадлежали к одному и тому же классу HTML, поэтому мне нужно было найти способ включить каждый из них.
- Количество страниц новостей относительно временных рамок, которые я хотел изучить, различалось у разных компаний. У некоторых компаний было только несколько пресс-релизов на одной странице, а у других было по три страницы обновлений. Мне нужно было бы выяснить, как пройти только по страницам в целевом временном интервале.
Эти проблемы могут показаться не очень сложными, но я полный новичок в веб-скрейпинге (и программировании в целом).
Я оказался в тупике.
Я знал, что могу потратить время на то, чтобы узнать больше о скрейпинге и в конечном итоге решить проблемы. Однако из-за ограниченности своих знаний я не мог оценить, сколько времени потребуется, чтобы одновременно ускорить процесс скрейпинга и фактически написать “паука”. Я уже потратил два часа на тестирование и обнаружение этих проблем. Я отвлекся на некоторое время, чтобы в голове у меня прояснилось.
Вернувшись, я открыл вкладку пресс-релизов случайной компании, скопировал таблицу новостей и вставил ее в пустой файл Excel. Это заняло у меня секунд десять. Я сделал несколько быстрых вычислений в уме (карты на стол — имеется в виду, открыл калькулятор) и понял, что мне потребуется 4,16 минуты, чтобы обработать все двадцать пять компаний.
Я так увлекся попытками понять, как автоматизировать процесс, что забыл о цели проекта. Это не должно было быть упражнением по изучению веб-скрейпинга. Моя цель состояла в том, чтобы как можно быстрее преобразовать необработанные данные в ключевые выводы.
Меня так и подмывало отказаться от этой затеи и продолжить скрейпинг, поскольку я уже потратил на это немало времени. К счастью, подключился мой мозг:
“БАЙРОН, МЫ УЖЕ УЗНАЛИ О НЕВОЗВРАТНЫХ РАСХОДАХ. ХВАТИТ”.
Спустя 10 минут я скопировал все пресс-релизы с сайта Euronext для каждой компании в индексе AEX. Это заняло не вполне четыре минуты, так как мне понадобилось еще шесть, чтобы немного обработать те данные, которые я копировал и вставлял. Как только это было сделано, я загрузил получившийся файл Excel в Tableau и, наконец, был готов начать строить графики.
Время выполнения: 130 минут.
Время, которое это могло бы занять: 10 минут.
Масштабировать или не масштабировать?
Мой мозг прямо сейчас уже надрывается:
“НО БАЙРОН, А КАК ЖЕ МАСШТАБИРОВАНИЕ? РАЗВЕ ТЫ НЕ ХОЧЕШЬ В КОНЕЧНОМ ИТОГЕ МАСШТАБИРОВАТЬ ЭТОТ ПРОЕКТ? ПОЧЕМУ ТЫ НЕ ДЕЛАЕШЬ ЕГО МАСШТАБИРУЕМЫМ?”
Мой ответ: да. В какой-то момент мне захочется сделать так, чтобы дашборд Tableau отображал данные в реальном времени, но брался за это я не потому. Цель проекта состояла по существу в том, чтобы построить несколько графиков. Данное упражнение было для меня быстрым и неряшливым способом освежить картину и узнать о том, что происходит с индексом AEX.
Составление графиков шло намного быстрее, чем сбор данных, так как я уже научился использовать Tableau. Мне не нужно было искать такие нишевые вещи, как синхронизация осей, написание выражений LOD и смешивание источников данных.
Когда я закончил, у меня был один дашборд, который объединял все три набора данных. С одной страницы я мог быстро получить базовое представление о том, как события влияют на цены акций. Я также мог видеть, существует ли какая-либо корреляция между случаями COVID-19 и изменениями индекса AEX с течением времени.
Вот что я вынес из этого: иногда действительно не нужно автоматизировать то, что вы пытаетесь сделать. Было бы здорово, если бы у меня были обновления в реальном времени для каждой категории данных. Собственно, именно этим я и собираюсь заняться дальше. Но это не было необходимо для проекта по доказательству концепции, которым данное упражнение и являлось.
Поначалу у меня была куча успехов с автоматизацией. Я планировал электронную почту, обрабатывал RSS-каналы и использовал Pandas для анализа данных, и все это — в течение пары месяцев изучения Python. Из-за этого я стал немного одержим попыткой применить автоматизацию везде. Я на собственном горьком опыте убедился, что процесс разработки автоматизированного решения может помешать выполнению работы.
Скопировать-и-вставить с веб-сайта оказалось чем-то вроде самого простого выхода, пусть даже простой выход был умопомрачительно скучным.
Это:
“Я настроил продвинутый веб-скрейпер, который заполнил реляционную базу данных в облаке, которая затем подключается к дашборду Tableau”.
звучит гораздо круче, чем это:
“Я скопировал кое-что с сайта и вставил в Excel. Потом я поместил это в Tableau”.
Вот в чем дело: у меня не было цели выглядеть круто.
Я мог бы сэкономить час, если бы не пытался быть крутым. Мне не нужно было это, чтобы закончить дашборд в доказательство концепции.
Так что после почти двух тысяч с лишним слов (спасибо, что зашли так далеко) я по большому счету пытаюсь донести две вещи:
- Когда речь об обучении, не стесняйтесь экспериментировать столько, сколько вам хочется.
- Когда речь о реализации проекта, сосредоточьтесь на получении результатов, а не на экспериментах.
Вкратце: всегда быть крутым не обязательно.
Примечание(1): Scrapy может анализировать JS, если вы интегрируете Splash или Selenium, но я еще не научился этого делать. Я еще даже не прикасался ни к чему подобному, вот почему и не думал пытаться. Задача скрейпинга обычных сайтов (без JS) была уже довольно знакомой. Вот почему для меня стало настоящей головоломкой, стоит ли автоматизировать сбор данных.
Читайте также:
- 6 веских причин поговорить об f-строках в Python
- Как создавать и публиковать консольные приложения на Python
- Сможете ли вы решить эти 3 «простые» задачи на Python?
Перевод статьи Byron Dolon: “Don’t automate all the boring stuff”





