
Анализ больших данных в Python переживает свой ренессанс. Всё началось с NumPy, которая тоже в каком-то смысле причастна к инструменту, с которыми я вас познакомлю в этой статье. В 2006 году тема больших данных начала постепенно привлекать внимание, особенно после выпуска Hadoop. Немногим позже последовала библиотека Pandas, включающая DataFrame’ы. В 2014 же году тема больших данных уже стала мейнстримом, к тому же в этот год был выпущен Apache Spark. В 2018 появилась Dask и другие библиотеки для аналитики данных в Python.
Каждый месяц я нахожу новый инструмент, который мне хочется освоить. И сначала полезно вкладывать пару часов в ознакомление с обучающим материалом, поскольку такая подготовка экономит уйму времени в долгосрочной перспективе. Также важно поддерживать связь с последними технологическими разработками. Однако, если вы ожидаете, что это будет статья о Dask, то ошибаетесь. Я нашёл ещё одну библиотеку Python для анализа данных, о которой вам следует знать.
Встречайте — Vaex
Vaex — это высокопроизводительная библиотека Python для ленивых DataFrame’ов, работающих по алгоритму out-of-core (обработка данных во внешней памяти). Предназначена она для визуализации и изучения больших наборов данных. Vaex может вычислять базовую статистику для более чем миллиарда строк за одну секунду. Она поддерживает несколько визуализаций, тем самым позволяя интерактивное изучение больших данных.
Vaex против Dask

Vaex не похож на сам Dask, но имеет сходства с его DataFrame’ами, которые создаются на основе DataFrame’ов Pandas. Это означает, что Dask наследует проблемы Pandas, например необходимость полной загрузки данных в RAM для их обработки. В Vaex же этой проблемы нет.
Vaex не создаёт копий DataFrame’ов, а значит может обрабатывать более крупные DataFrame’ы на машинах с меньшим количеством основной памяти.
И Vaex, и Dask используют ленивую обработку. Единственное отличие в том, что первый вычисляет поле при необходимости, а для второго нам нужно явно использовать функцию вычисления.
Для того, чтобы полноценно воспользоваться преимуществами Vaex, данные должны быть в формате HDF5 или Apache Arrow.
Установка Vaex
Установка Vaex так же проста, как и установка любого пакета Python:
pip install vaex
Перейдём к тест-драйву

Создадим DataFrame Pandas с 1 миллиардом строк и 1000 колонок, получив таким образом файл больших данных.
import vaex
import pandas as pd
import numpy as npn_rows = 1000000
n_cols = 1000
df = pd.DataFrame(np.random.randint(0, 100, size=(n_rows, n_cols)), columns=['col%d' % i for i in range(n_cols)])df.head()
Сколько основной памяти этот DataFrame использует?
df.info(memory_usage='deep')

Давайте сохраним файл на диск, чтобы иметь возможность считать его позже, используя Vaex.
file_path = 'big_file.csv'
df.to_csv(file_path, index=False)Считав весь CSV напрямую с помощью Vaex, мы бы получили не очень много, поскольку скорость была бы аналогична Pandas. И той, и другой библиотеке на моём ноутбуке потребовалось бы 85 секунд.
Чтобы увидеть преимущества Vaex, нам нужно конвертировать CSV в HDF5 (иерархический формат данных версии 5). В Vaex есть функция для конвертации, которая поддерживает даже файлы, превышающие размером объём основной памяти, производя конвертацию небольшими частями.
Если мы не можем открыть файл при помощи Pandas из-за ограничений памяти, то можем преобразовать его в HDF5 и обработать с помощью Vaex.
dv = vaex.from_csv(file_path, convert=True, chunk_size=5_000_000)
Эта функция автоматически создала файл HDF5 и сохранила его на диск.
Давайте проверим тип dv:
type(dv)# вывод
vaex.hdf5.dataset.Hdf5MemoryMappedТеперь давайте используем Vaex для считывания набора данных размером 7,5 Гб — на деле нам не требуется считывать его, поскольку он уже есть у нас в переменной dv сверху. Делаем же мы это только, чтобы замерить скорость:
dv = vaex.open('big_file.csv.hdf5')
На выполнение этой команды Vaex потребовалось менее 1 секунды, но при этом из-за особенности ленивой загрузки Vaex на самом деле не считывала файл, ведь так?
Давайте же принудим её считать его, вычислив сумму col1.
suma = dv.col1.sum()
suma# массив(49486599)
Результат меня очень удивил. Vaex для вычисления суммы потребовалось менее 1 секунды. Как такое возможно? Всё благодаря использованию отображения памяти.
Построение графиков
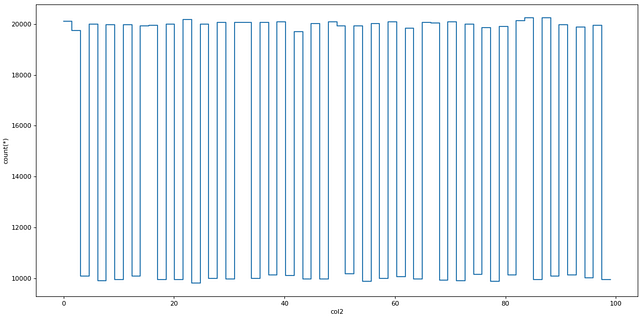
Vaex также очень быстра в построении графиков данных. У неё для этого есть специальные функции plot1d, plot2d и plot2d_contour.
dv.plot1d(dv.col2, figsize=(14, 7))
Виртуальные колонки
Vaex при добавлении новой колонки создаёт виртуальную — колонку, которая не потребляет основную память, поскольку вычисляется на ходу.
dv['col1_plus_col2'] = dv.col1 + dv.col2
dv['col1_plus_col2']
Эффективная фильтрация
Vaex не будет создавать копии DataFrame’а при фильтрации данных, что окажется более экономично с точки зрения памяти.
dvv = dv[dv.col1 > 90]
Агрегирование
Агрегирование здесь работает не совсем так, как в Pandas, но важнее то, что оно выполняется чрезвычайно быстро.
Давайте вычислим бинарную колонку, где col1 ≥ 50:
dv['col1_50'] = dv.col1 >= 50
Vaex сочетает группировку и агрегирование в одной команде. Команда ниже группирует данные по колонке “col1_50” и вычисляет сумму колонки col3:
dv_group = dv.groupby(dv['col1_50'], agg=vaex.agg.sum(dv['col3']))
dv_group
Объединение
Vaex объединяет данные, не создавая копий в памяти, что может сэкономить её основной объём. Пользователи Pandas узнают знакомую им функцию join:
dv_join = dv.join(dv_group, on=’col1_50')
Читайте также:
- Vaex: Python библиотека для работы с DataFrame вне памяти и быстрой визуализации
- Пять отличных Python-библиотек для data science
- Обзор библиотеки Datatable в Python
Перевод статьи Roman Orac: How to process a DataFrame with billions of rows in seconds.

")



