
Установка Bamboolib
Установка достаточно проста:
pip install bamboolib
Чтобы Bamboolib работал с Jupyter и Jupyterlab, нужно установить дополнительные расширения. С помощью следующей команды устанавливаются расширения для Jupyter Notebook:
jupyter nbextension enable --py qgrid --sys-prefix
jupyter nbextension enable --py widgetsnbextension --sys-prefix
jupyter nbextension install --py bamboolib --sys-prefix
jupyter nbextension enable --py bamboolib --sys-prefixЗдесь можно найти процесс установки для Jupyterlab.
Проверка установки Bamboolib
Чтобы проверить, правильно ли работает Bamboolib, откройте Jupyter notebook и выполните следующие команды:
import bamboolib as bam
import pandas as pd
data = pd.read_csv(bam.titanic_csv)
bam.show(data)При запуске команда запрашивает лицензионный ключ, который нужен для использования bamboolib. Приобрести ключ можно здесь. Перед покупкой вы можете попробовать демо-версию, чтобы увидеть библиотеку в действии.

После активации bamboolib начинается самое интересное. Вывод Bamboolib выглядит следующим образом:

Для работы с Bamboolib мы будем использовать данные по классификации цен на мобильные устройства от Kaggle. Сначала создадим классификатор, который предсказывает ценовой диапазон мобильных телефонов на основе характеристик:
train = pd.read_csv("../Downloads/mobile-price-classification/train.csv")
bam.show(train)
Для запуска Bamboolib нужно выполнить простой вызов bam.show(train).
Простое исследование данных
Bamboolib отлично подходит для первичного анализа данных. Исследование — неотъемлемая часть любого конвейера данных, однако написание кода для него и создание всех диаграмм — это сложный процесс, требующий терпения и усилий.
Bamboolib значительно упрощает его.
Например, при нажатии на Visualize Dataframe отображается представление данных.

В нем отражены пропущенные значения в каждом столбце, а также количество уникальных значений и несколько экземпляров.
Помимо этого, можно получить одномерную статистику на уровне столбцов. Попробуем получить информацию о целевой переменной — Price Range:

Получаем одномерные статистические данные и наиболее важные показатели для целевого столбца. Исходя из данных, наиболее важными показателями для ценового диапазона являются оперативная память и заряд батареи.
Давайте посмотрим, как ОП влияет на ценовой диапазон. Для этого мы будем использовать двумерные графики:

Получение подобных графиков со стандартными библиотеками Python, такими как seaborn или plotly, обычно требует некоторое количество кода. Несмотря на то, что plotly_express предоставляет простые функции для большинства графиков, Bamboolib создает множество важных графиков автоматически.
Мы видим, что с увеличением ОП увеличивается и диапазон цен. Помимо этого, здесь отображена оценка F1 0,676 для переменной RAM. Такой график можно создать для каждой переменной в наборе данных.
Код этих диаграмм можно экспортировать для использования в презентациях либо в формате PNG.
Для этого просто скопируйте фрагмент кода, который показан над каждым графиком. Например, при отображении price_range в сравнении с ram предоставляется опция загрузки этих графиков в формате PNG. В бэкенде все они являются графиками plotly.
bam.plot(train, 'price_range', 'ram')

Преобразование данных на основе графического интерфейса
Bamboolib упрощает выполнение любых действий и помогает не потеряться в коде. Вы можете удалять столбцы, фильтровать, сортировать, объединять, группировать, сводить и т. д. с помощью простого графического интерфейса.
Например, здесь мы удаляем пропущенные значения из целевого столбца. Также можно добавить несколько условий:

Одной из приятных особенностей является предоставление кода. Ниже представлен код для отбрасывания пропущенных значений, который заполняется автоматически.
train = train.loc[train['price_range'].notna()]
train.index = pd.RangeIndex(len(train))
Он работает, как Microsoft Excel для бизнес-пользователей, при этом предоставляет весь код для продвинутых.
Ниже представлен ещё один пример использования объединения:
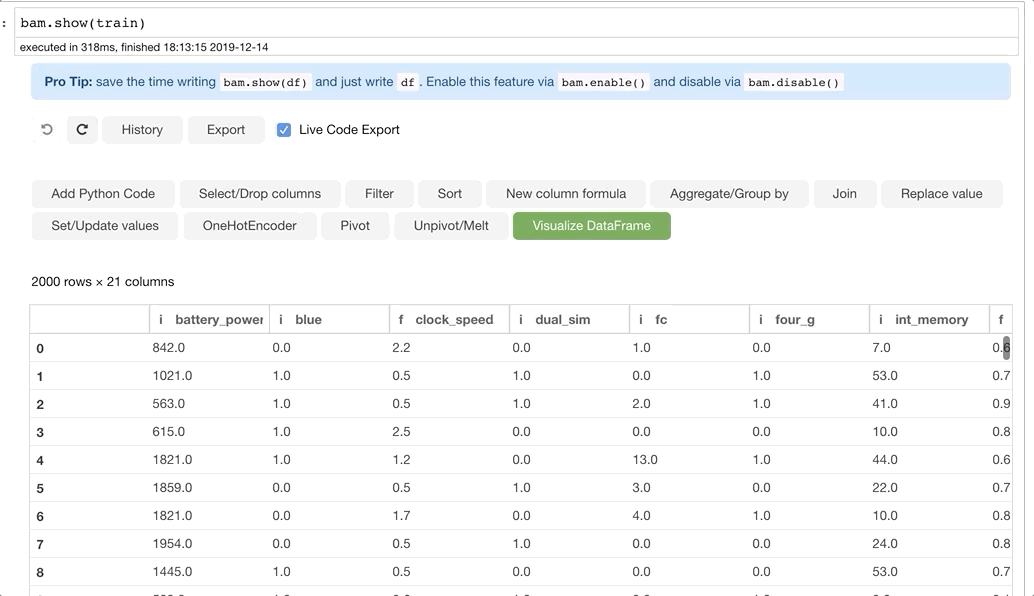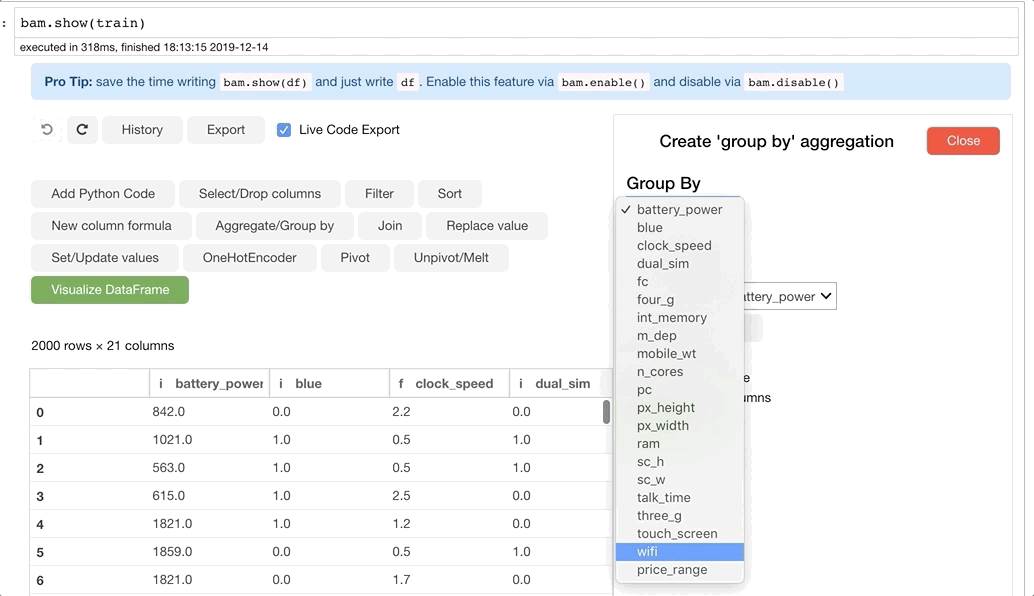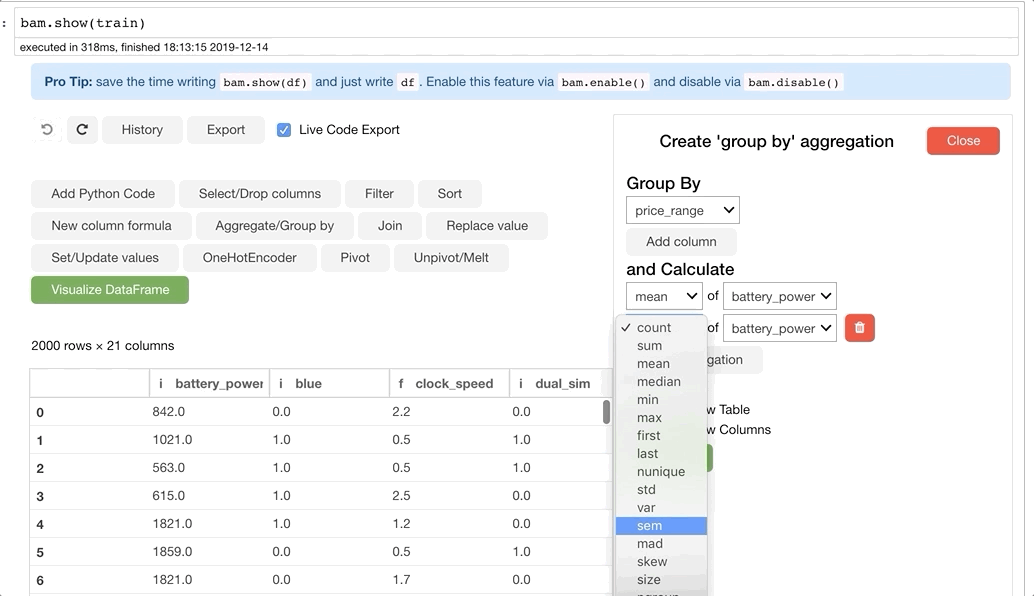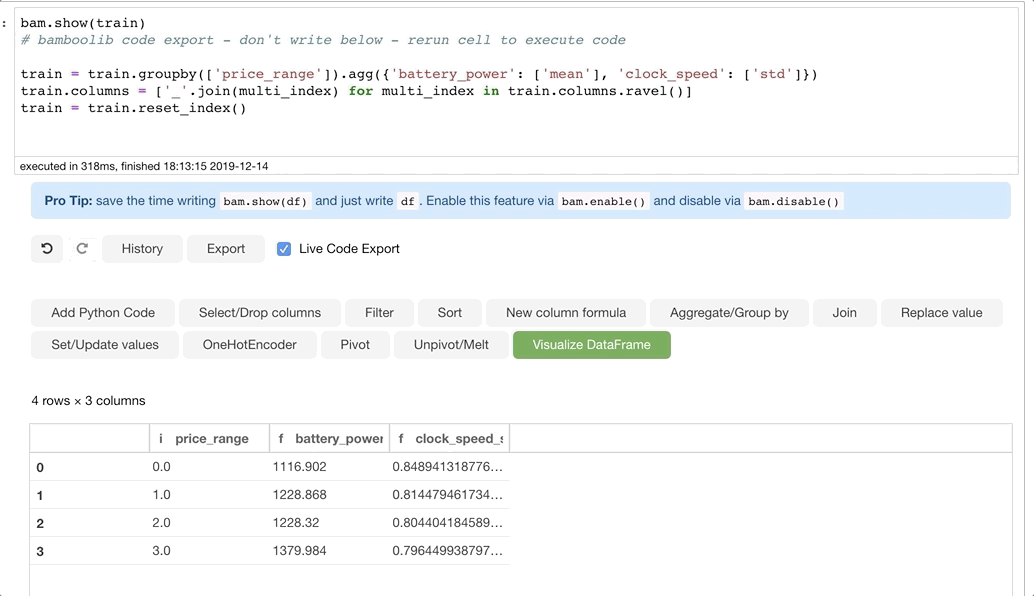
Код выглядит следующим образом:
train = train.groupby(['price_range']).agg({'battery_power': ['mean'], 'clock_speed': ['std']})
train.columns = ['_'.join(multi_index) for multi_index in train.columns.ravel()]
train = train.reset_index()Заключение
Графический интерфейс Bamboolib довольно интуитивен и с ним приятно работать. Проект все еще находится в начале разработки, однако уже подаёт множество надежд.
Можно с уверенностью сказать, что эта библиотека пригодится для новичков, которые хотят научиться работать с Pandas, поскольку она предоставляет доступ ко всем необходимым функциям, избавляя от лишних хлопот.
- Значение Data Science в современном мире
- Как составить Data Science портфолио? Часть 1
- Настройка Data Science окружения на вашем компьютере
Перевод статьи Rahul Agarwal: Bamboolib — Learn and use Pandas without Coding





