

Как построить систему с низкой задержкой на Java, способную обрабатывать высокую пропускную способность с миллионами запросов? Одних лишь общих методов программирования и знаний в области проектирования ПО недостаточно для создания такой критически важной системы.
Ключевая идея тонкой настройки производительности системы заключается в управлении памятью и использовании нативных операций CPU. Однако, в отличие от низкоуровневого программирования, такого как C, Java автоматически управляет выделением и освобождением памяти. Это палка о двух концах. С одной стороны, разработчикам не нужно беспокоиться о памяти и они могут больше сосредоточиться на бизнес-логике. С другой стороны, они не имеют прямого контроля над этим процессом.
Разработка стакана заявок (ордербука) в трейдинговой системе — это классический пример, демонстрирующий способности программирования на Java с низкой задержкой. В этой статье рассмотрим несколько приемов с доказательствами, подтвержденными результатами тестов производительности.
Что такое стакан заявок в трейдинговых системах?
Если вы не знакомы с трейдинговыми системами, начнем с краткого введения в понятие стакана заявок. Основное назначение стакана заявок — сопоставление (матчинг) ордеров от покупателей и продавцов. Запросы обрабатываются в соответствующей временной последовательности.
Для ордеров покупателя торговый движок ищет наименьшую цену продажи, равную или меньшую, чем цена покупки. И наоборот, для ордеров продавца ищется наибольшая цена покупки, равная или превышающая цену продажи, для совершения сделки.
Рассмотрим пример: торговый движок получает ордера из очереди сообщений и поддерживает отдельно списки ожидающих ордеров на покупку и на продажу. Эти ожидающие ордера не могут быть сопоставлены для совершения сделки (например, цена покупки ниже наивысшей цены продажи или наоборот).
Чтобы сделать сопоставление ордеров простым и эффективным, надо сгруппировать ордера по ценам.
- Для ордеров покупателя цены ордеров сортируются по убыванию, чтобы стакан заявок мог просто взять первую (наивысшую) цену покупки для сопоставления.
- Цены ордеров продавцов сортируются по возрастанию, чтобы стакан заявок мог получить наименьшую цену продажи из первого элемента.
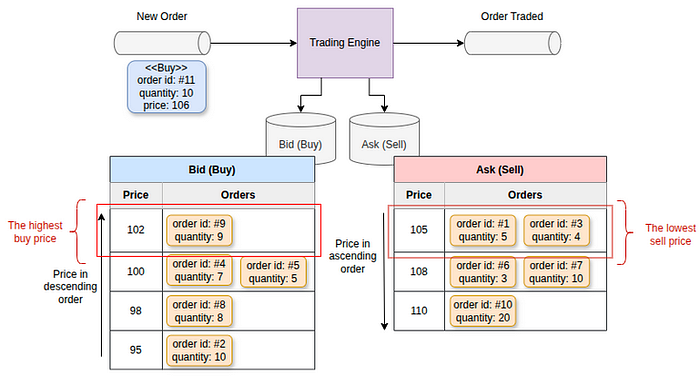
Когда поступает новый ордер на покупку #11 (цена: $106; количество: 10), торговый движок получает список ордеров с наивысшей ценой продажи.
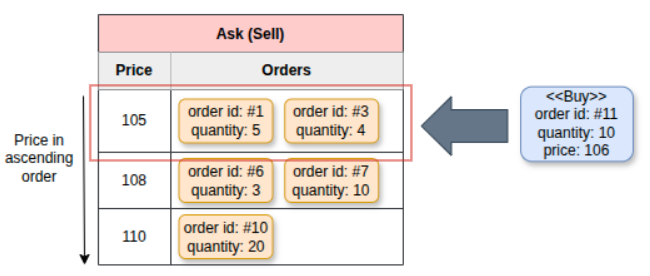
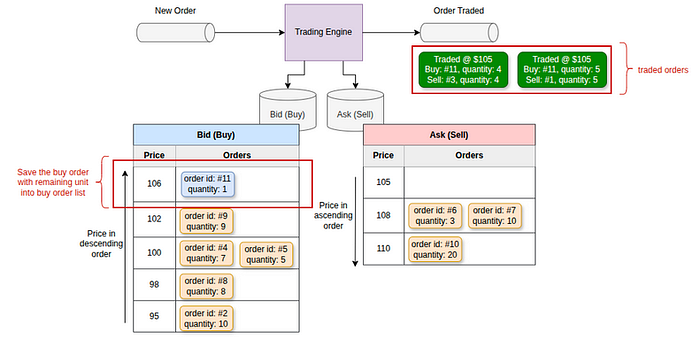
В случае, если несколько ордеров имеют одинаковую цену, они обрабатываются в порядке очереди «первым пришёл — первым ушёл». В этом примере торговый движок сначала сопоставляет ордер на покупку #11 с ордером на продажу #1, а затем с ордером на продажу #3. У ордера на покупку #11 остаётся 1 единица, однако следующая наименьшая цена продажи ($108) выше цены покупки. Следовательно, ордер на покупку с оставшимися единицами помещается в список ордеров на покупку.
Аналогичный процесс применяется для сопоставления входящих ордеров на продажу с ордерами на покупку. См. полный исходный код примерной реализации.
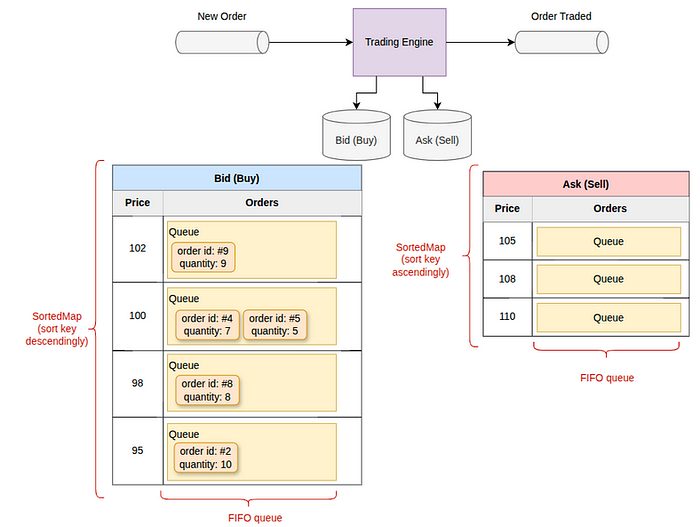
Структура данных
Обладая парами «ключ (цена) — значение (список ордеров)», SortedMap (также известный как TreeMap) в Java предоставляет идеальную структуру данных для такой задачи. Для обработки ордеров по принципу «первым пришел — первым обслужен», ордера для каждой цены хранятся в очереди FIFO («первый пришел — первый ушел»). Классом реализации Queue может быть LinkedList в Java.
В этом примере мы не будем рассматривать многопоточную среду в торговом движке, потому что накладные расходы на переключение контекста и синхронизацию часто замедляют процесс и влияют на пропускную способность. Фактически, распространенная архитектура трейдинговой системы предполагает выполнение одного потока на инструмент (тикер) с очередью сообщений на входе для приема входящих ордеров.
Вот атрибуты ордера:
class Order {
enum Side { BUY, SELL }
final long id;
final Side side;
final BigDecimal price;
long quantity;
}Помимо списка ордеров на покупку и списка ордеров на продажу, мы поддерживаем отдельный Map для поиска ордера по идентификатору. Это необходимо для выполнения других операций, таких как отмена ордера.
SortedMap<BigDecimal, Queue<Order>> buyBook =
new TreeMap<>(Comparator.reverseOrder()); // сначала самая высокая цена
SortedMap<BigDecimal, Queue<Order>> sellBook =
new TreeMap<>(); // сначала самая низкая цена
Map<Long, Order> orderById = new HashMap<>();Совет №1: Используйте примитивные типы данных
Просто взглянув на структуру данных, замечаете ли вы области, требующие улучшения? Первое простое изменение — избавиться от BigDecimal.
Хотя я полностью согласен с тем, что BigDecimal следует использовать в финансовых системах, чтобы избежать проблем, касающихся точности чисел с плавающей запятой у типов double/float, операции с BigDecimal, такие как масштабирование, сравнение и арифметические операции, гораздо медленнее, чем с примитивными типами данных. CPU нативно поддерживает вычисления с примитивными типами, что дает значительный прирост производительности.
Чтобы избежать проблем с точностью из-за десятичных знаков, используется техника фиксированной запятой (fixed-point representation): хранение полного числового значения в целочисленных типах данных (int или long). Например, 1234,56 можно хранить как 123456. Числовое значение форматируется с разделителями тысяч и десятичными точками только при представлении данных конечным пользователям.
Настройка простая и понятная. Просто замените BigDecimal на long в структуре данных.
// Определение ордера
class Order {
enum Side { BUY, SELL }
final long id;
final Side side;
final long price; // BigDecimal -> primitive type long
long quantity;
}
// Структура данных стакана заявок
SortedMap<Long, Queue<Order>> buyBook =
new TreeMap<>(Comparator.reverseOrder()); // highest price first
SortedMap<Long, Queue<Order>> sellBook =
new TreeMap<>(); // lowest price first
Map<Long, Order> orderById = new HashMap<>();Создадим тест производительности, чтобы подтвердить эту идею. Поскольку торговый движок только сравнивает цены без других арифметических операций, тест сосредоточен именно на сравнении значений.
Наш тест производительности (полный исходный код здесь) будет основан на библиотеке Java Microbenchmark Harness (JMH).
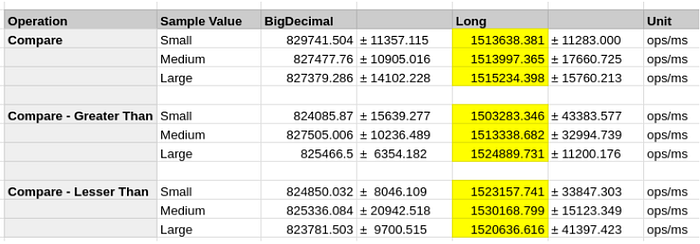
Пропускная способность (количество операций в миллисекунду) для типа long почти вдвое выше, чем для BigDecimal. Результат доказывает, что использование примитивных типов данных обеспечивает более высокую производительность.
Совет №2: Преобразовывайте TreeMap в массив
Текущее решение задействует TreeMap, который использует сортировку для поиска по ключу. Временная сложность операций доступа, вставки и удаления данных составляет примерно O(logN), где N — количество ключей в TreeMap. Это означает, что получение списка ордеров с минимальной ценой продажи или максимальной ценой покупки занимает O(logN) времени. Замена TreeMap на массив потенциально может повысить эффективность до O(1), то есть постоянного времени, независимо от размера данных.
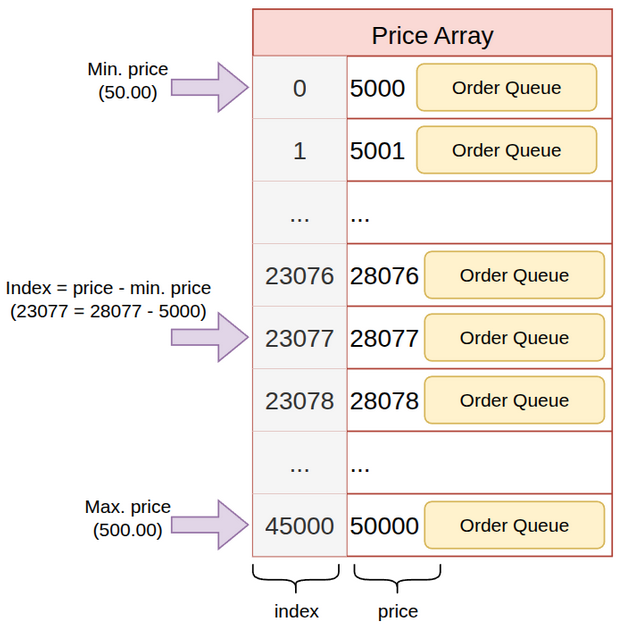
В массиве цены хранятся в порядке возрастания в соответствии с индексом. Минимальная цена по индексу 0 не обязательно равна нулю. Например, в массиве ниже применяется диапазон цен от 5000 (т.е. $50.00) до 50000 (т.е. $500.00). Тогда индекс массива можно вычислить по формуле «целевая цена минус минимальная цена».
При отслеживании текущей минимальной цены продажи и максимальной цены покупки, поиск ордера для сопоставления происходит за константное время и, как правило, не зависит от количества записей в массиве. Иногда может потребоваться дополнительное время для поиска следующей минимальной цены продажи или максимальной цены покупки, если текущая очередь ордеров исчерпана.
Проведем тест производительности для исходного стакана ордеров и реализации на основе массива соответственно. Использование массива дает прирост производительности в пропускной способности для сопоставления ордеров примерно на 18%.

Совет №3: Используйте кольцевой буфер фиксированного размера вместо LinkedList
Пришло время оптимизировать очередь ордеров. Существующая реализация использует LinkedList. Проблема в том, что LinkedList создает узел для хранения указателей на следующий узел для каждой новой записи в своей внутренней структуре. Это требует времени не только на выделение памяти, но и на обход по цепочке указателей.
Ситуацию можно улучшить, если мы сможем:
- минимизировать накладные расходы на выделение памяти;
- максимизировать вероятность использования кэша процессора.
Предлагается использовать кольцевой буфер (циклический буфер) фиксированного размера, потому что:
- предварительно выделенные элементы массива устраняют необходимость создания нового узла для вставки;
- элементы в массиве располагаются в смежных блоках памяти, что увеличивает вероятность попадания в кэш процессора, который намного быстрее оперативной памяти.
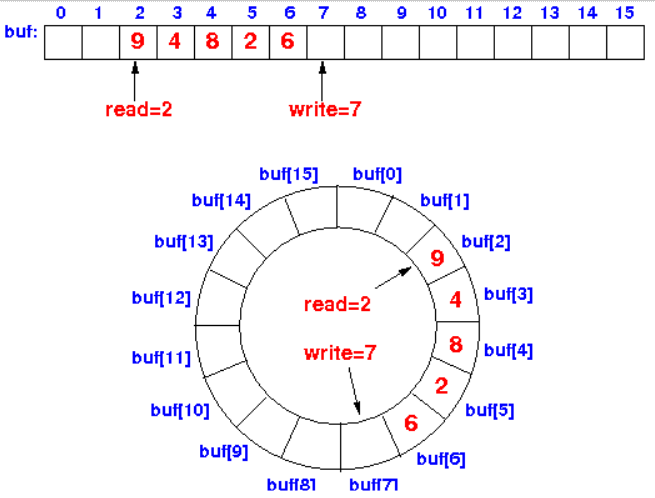
Физически кольцевой буфер реализуется как массив элементов с двумя указателями, которые отслеживают позиции чтения и записи. Когда указатель достигает конца массива, следующим элементом становится индекс 0. Как показано в примере ниже, следующей позицией будет индекс 0, если текущая позиция — индекс 15.
Поскольку размер фиксирован, буфер считается заполненным, если следующая позиция указателя записи накладывается на позицию указателя чтения. И наоборот, буфер считается пустым, если текущие позиции указателей записи и чтения совпадают.
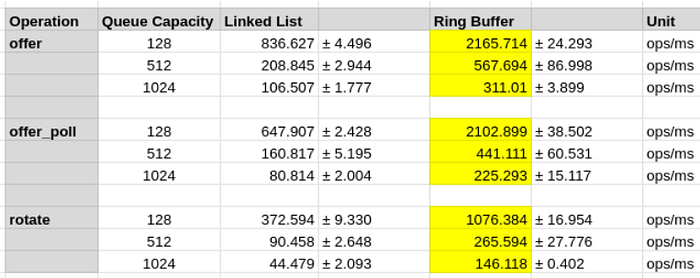
Результат тестирования производительности (см. полный исходный код здесь) подтверждают изложенную теорию: кольцевой буфер работает как минимум в 3 раза быстрее, чем LinkedList.
Пример реализации OrderQueue с использованием кольцевого буфера:
public static final class OrderQueue {
private final Order[] items;
private int head = 0; // указывает на следующий элемент для извлечения
private int tail = 0; // указывает на следующий элемент для вставки
public OrderQueue(int capacity) {
// вместимость должна быть >= 1
items = new Order[capacity];
}
public boolean add(Order o) {
int nextTail = (tail + 1) % items.length;
if (nextTail == head) return false; // полный
items[tail] = o;
tail = nextTail;
return true;
}
public Order peek() {
if (head == tail) return null;
return items[head];
}
public Order poll() {
if (head == tail) return null;
Order r = items[head];
items[head] = null;
head = (head + 1) & (items.length - 1);
return r;
}
public boolean isEmpty() { return head == tail; }
}Совет №4: Используйте битовую операцию AND вместо взятия остатка (оператора modulus)
При работе с кольцевым буфером часто используют оператор взятия остатка для перемещения указателя с конца буфера обратно на позицию 0. Например, вот логика для получения следующей позиции указателя в массиве:
int nextPosition = (currentPosition + 1) % array.length;Вместо того, чтобы выполнять арифметические вычисления, используйте битовую операцию AND, так как она гораздо быстрее. Арифметические вычисления выполняются медленнее, поскольку внутри процессора они реализуются последовательностью битовых операций AND/OR/XOR. Следовательно, всего одна битовая операция AND может сократить количество необходимых битовых операций.
Улучшенная версия выглядит так:
int nextPosition = (currentPosition + 1) & (array.length - 1);Как это работает?
Например, размер массива равен 8, что в двоичном формате равно 1000.
- Когда текущая позиция равна 7 (111) (последняя позиция), тогда следующая позиция = (111 + 1) & (1000–1) = 1000 & 111 = 0 (первая позиция).
- Когда текущая позиция равна 8 (1000), тогда следующая позиция = (1000 + 1) & (1000–1) = 1001 & 111 = 1 (вторая позиция).
И так далее…
Размер буфера должен быть степенью двойки из-за особенностей битовой операции AND.
Посмотрим на результат теста производительности (см. полный исходный код здесь): битовая операция AND более чем в 10 раз быстрее операции взятия остатка (mod).

Совет №5: Используйте пул объектов, чтобы избежать затрат на выделение памяти
Выделение памяти — один из ключевых факторов, приводящих к замедлению работы Java-приложений. Это связано не только с тем, что выделение памяти требует времени, но и с затратами времени на очистку неиспользуемой памяти сборщиком мусора (GC). Очистка большого объема памяти может приостановить работу всей системы, серьезно влияя на доступность сервиса и производительность.
Внедрение пула объектов эффективно снижает нагрузку на GC, поскольку одни и те же объекты используются повторно.
Тест производительности (см. полный исходный код здесь) показывает, что пул объектов повышает пропускную способность примерно на 10%, в зависимости от выделения памяти в куче и конфигурации GC.

Это пример реализации пула объектов для ордеров. Вызовите метод acquire(), чтобы получить объект ордера с заданными атрибутами:
public static final class OrderPool {
private final Order[] pool;
private int idx = 0;
public OrderPool(int size) {
pool = new Order[size];
for (int i = 0; i < size; i++) pool[i] = new Order();
}
public Order acquire(long id, Order.Side side, long priceTicks, long quantity) {
int i = idx++;
if (i >= pool.length) idx = 0; // циклический переход
Order o = pool[i % pool.length];
o.reset(id, side, priceTicks, quantity);
return o;
}
public void release(Order o) {
// здесь ничего не требуется, объект используется повторно
}
}Заключение
Выбор правильной структуры данных крайне важен для создания эффективного Java-сервиса. Кроме того, не стоит забывать, что выделение памяти и работа сборщика мусора (GC) могут неожиданно повлиять на производительность системы, даже если используется оптимальная структура данных. Поэтому грамотное управление выделением объектов даст дополнительный прирост скорости.
Более того, использование нативных операций процессора, таких как работа с примитивными типами данных и битовые операции, может стать решающим фактором.
Помимо этих базовых техник, существует множество открытых эффективных библиотек, которые помогут создать невероятно быстрый Java-сервис. Настоятельно рекомендую обратить внимание на высокопроизводительную библиотеку для обмена сообщениями между потоками — LMAX Disruptor и библиотеку высокопроизводительных структур данных — Agrona.
Читайте также:
- Роль метода Stream.map() в Java
- Как правильно учиться Java-программированию: история одного тьютора
- is-A против has-A
Читайте нас в Telegram, VK и Дзен
Перевод статьи Gavin F.: 5 Proven Techniques for Ultra-Fast, Low-Latency Trading Systems in Java





