

Вступление
Изучим внутренние механизмы Apache Iceberg, поэкспериментируем с этим файловым форматом и PySpark, PyIceberg, каталогом Nessie.
Слой данных
В этом слое содержатся данные самой таблицы и удаленные файлы — они имеются, если выбран режим объединения при считывании, подробнее об этом позже. В файлах данных хранятся записи таблицы, а файлами delete отслеживаются удаленные строки.
В Apache Iceberg поддерживаются файловые форматы Apache Parquet, Apache ORC и Apache Avro. На практике Apache Parquet — самый применяемый формат, им и воспользуемся при подробном разборе Iceberg.
Слой метаданных
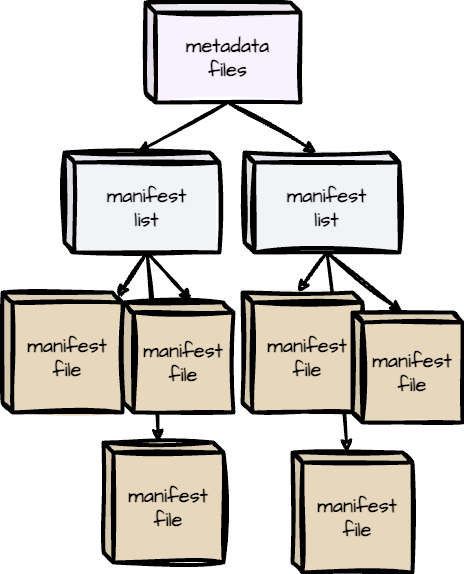
В Iceberg метаданные организованы в древовидную структуру: наверху — файлы метаданных, ниже — списки манифестов, еще ниже — файлы манифестов. Слоем метаданных управляются большие наборы данных, включается основной функционал вроде перехода во времени и эволюции схем.
Файлы манифеста

Файлами манифеста отслеживаются данные, файлы delete, дополнительные сведения и статистика по каждому файлу: формат, схема разделов, количество, значения null, максимальные/минимальные для столбцов файла данных.
В файле Parquet часть этой статистики — минимум/максимум каждого блока столбца — хранится в самих файлах данных и находится читателем при открытии подвала каждого файла Parquet.
В Iceberg же в одном файле манифеста хранится статистика сразу нескольких файлов данных Parquet, для ее считывания читателем открывается тот файл манифеста, которым эти файлы отслеживаются. Таким образом повышается эффективность считывания.
Эта статистика записывается движком во время операции записи.
Списки манифестов
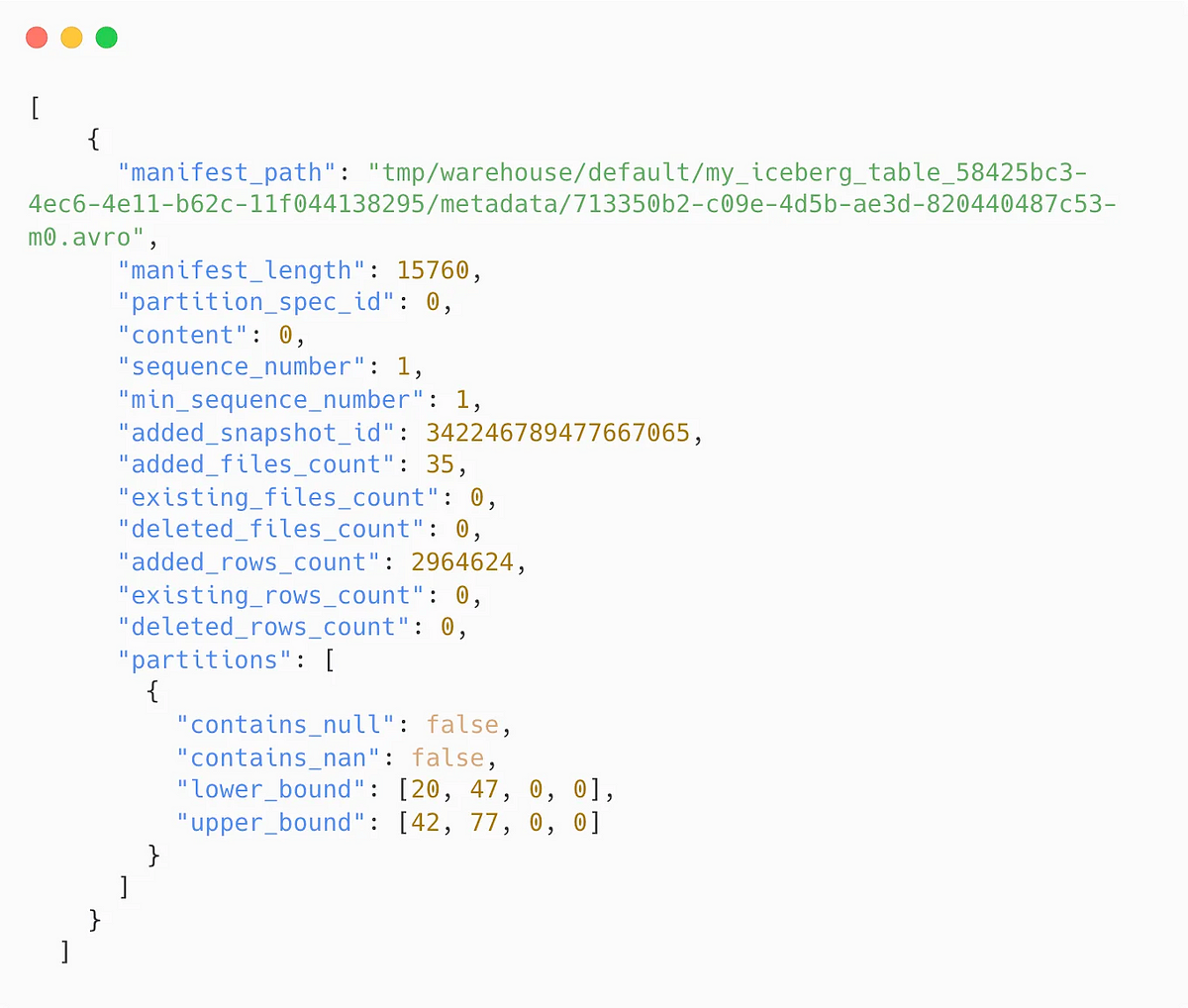
Каждый снимок таблицы Iceberg связан со списком манифестов и содержит массив структур, каждым элементом которого отслеживается один файл манифеста со включением такой информации:
- Расположение файла манифеста.
- Раздел, к которому относится этот файл манифеста.
- Верхняя и нижняя границы ненулевых значений поля раздела вычисляются для файлов данных, отслеживаемых этим файлом манифеста.
Файлы метаданных

В этих файлах хранятся метаданные таблицы Iceberg на конкретный момент времени с такой информацией:
- Последним порядковым номером определяется порядок следования снимков в таблице. При каждом изменении таблицы это число увеличивается.
- Временнáя метка обновлений таблицы.
- Базовым расположением таблицы определяется, где хранятся данные, манифесты и метаданные таблицы.
- Схема таблицы.
- Спецификация раздела.
- Какой снимок текущий.
- Вся информация о снимке и соответствующие списки манифестов.
Каталог
Все запросы направляются через каталог, в котором содержится указатель текущих метаданных для каждой таблицы и хранится местоположение файлов текущих и предыдущих метаданных. Так читателю всегда доступна самая актуальная информация.
Поддержка атомарных операций при обновлении указателя метаданных — важнейшее требование к каталогу Iceberg. Так обеспечивается, что все читатели и писатели взаимодействуют с согласованным состоянием таблицы в определенный момент времени.
Опишем подробнее операции считывания/записи Iceberg.
Операция записи
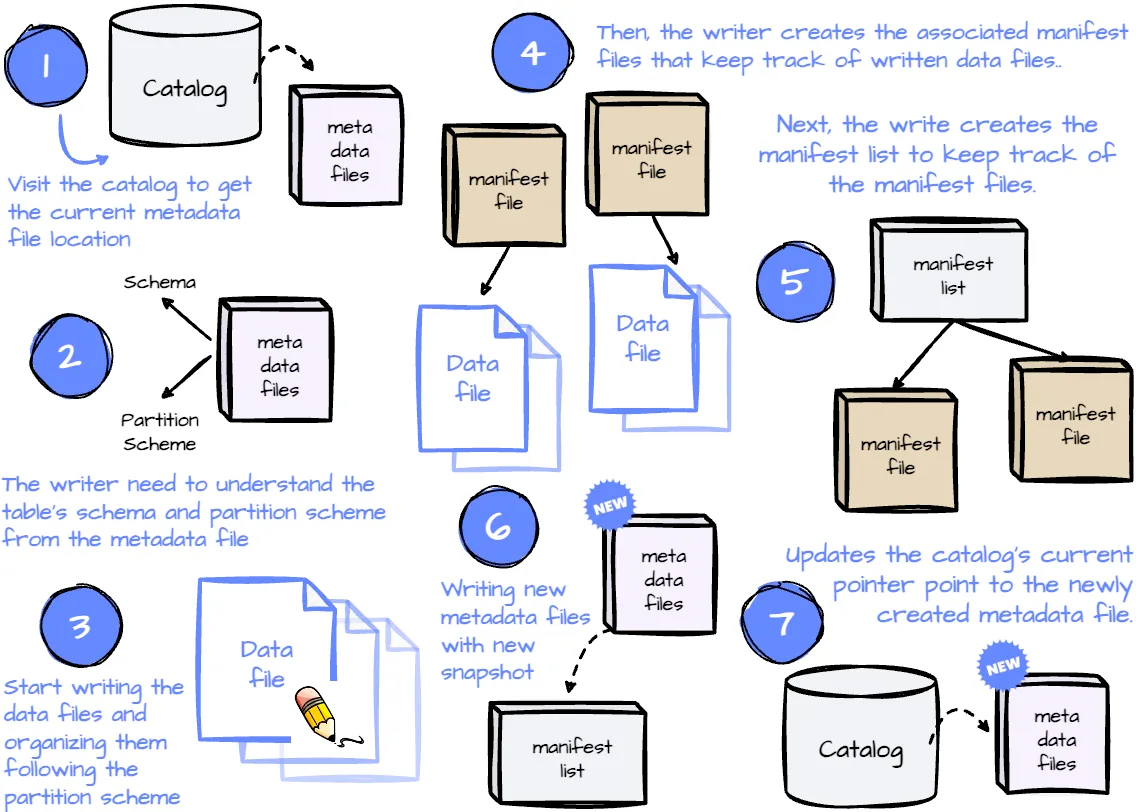
- При записи новых данных в имеющуюся таблицу Iceberg писатель, чтобы получить местоположение файла с текущими метаданными, обращается к каталогу. Чтобы понять текущую схему и схему разделов таблицы и подготовиться к последующей записи данных, писателем считывается этот файл.
- Когда эта информация получена, писателем записываются новые файлы данных согласно схеме разделов.
- Затем писателем соответственно создаются файлы манифеста в формате Avro. В файле манифеста содержится местоположение файла данных, а также статистика файла: верхняя и нижняя границы столбца и количество значений
null. Статистика вычисляется писателем в процессе записи. - Затем, чтобы отслеживать файлы манифеста, писателем создается список манифеста. В этом файле содержатся расположение файлов манифеста, количество добавленных или удаленных файлов/строк данных, нижняя и верхняя границы столбцов разделов и т. д.
- Далее им записывается новый файл метаданных с последними и всеми предыдущими снимками. В нем содержатся базовое местоположение таблицы, местоположение списка манифеста, идентификатор снимка, порядковый номер, обновленная временнáя метка и т. д. Кроме того, вновь созданный снимок помечается писателем как текущий.
- Наконец, писателем обновляется текущая точка указателя каталога на вновь созданный файл метаданных.
Операция считывания
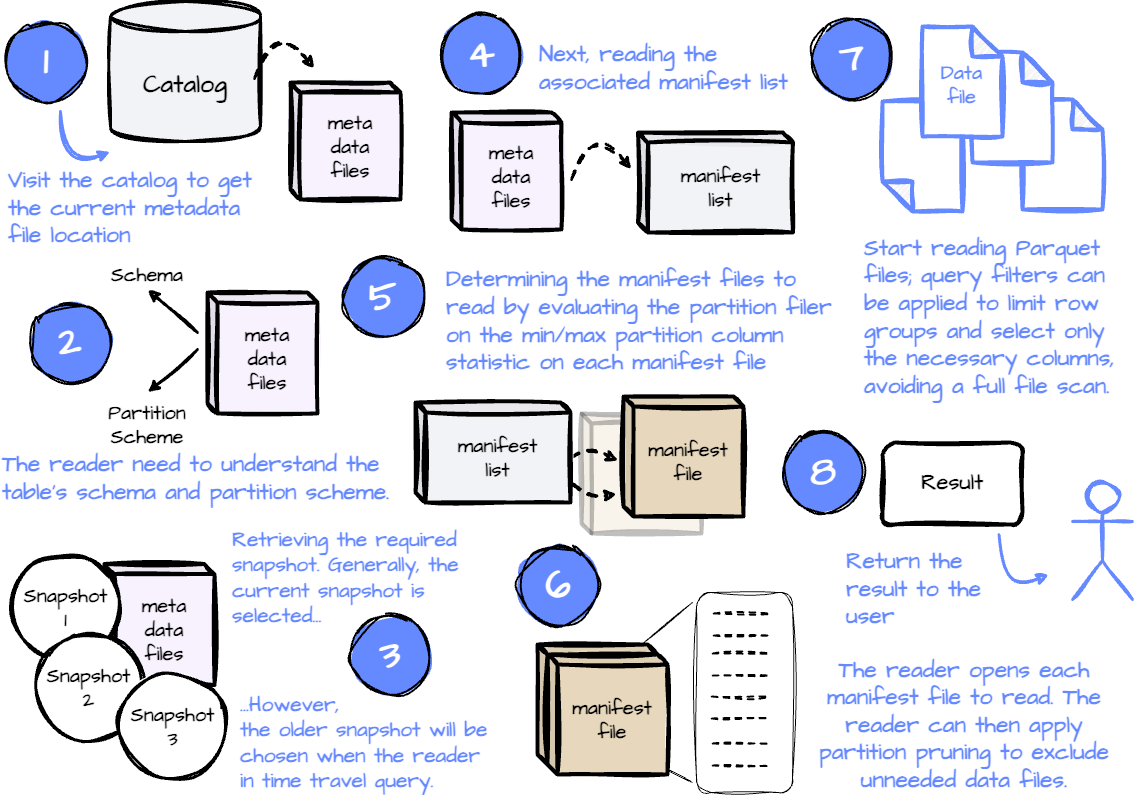
- Сначала читатель, чтобы найти местоположение файла с текущими метаданными, обращается к каталогу.
- После получения файла метаданных, чтобы подготовиться к процессу считывания, читателем собирается схема таблицы. Затем для понимания, как организованы данные, им проверяются схемы разделов таблицы.
- Следующий этап — получение снимка для считывания читателем. При обычном запросе выбирается текущий снимок. Но для запроса с переходом во времени, когда пользователь считывает данные в предыдущем состоянии, выбирается старый снимок. Запрос с переходом во времени выполняется указанием считываемой приложением временнóй метки, в этом случае в Iceberg выполняется поиск более старых снимков, чем эта метка. Это возможно благодаря тому, что в файле метаданных сохраняется и созданная временнáя метка каждого снимка. В запросе можно прямо указать идентификатор снимка.
- После выбора снимка читателем обнаруживается список манифестов, связанный с этим снимком.
- Затем, чтобы определить местоположение файлов манифеста, читателем считывается список манифеста. А также собираются значения нижней и верхней границ в столбце раздела каждого файла манифеста. Поскольку файлом манифеста отслеживается несколько файлов данных, эти нижние и верхние значения вычисляются для этих файлов. Чтобы удалить ненужные файлы манифеста, читателем применяется фильтр разделов.
- Когда необходимые файлы манифеста определены, читателем открывается каждый считываемый файл. В одном файле манифеста содержатся сведения по всем отслеживаемым им файлам данных. В Iceberg каждый такой файл — это запись, в которую записывается информация вроде местоположения файла данных, значений нижней/верхней границ раздела каждого файла, формата файла, количества записей и т. д.
- При считывании каждой записи, чтобы удалить ненужные файлы данных, читателем урезаются разделы. Это делается при помощи значений нижней/верхней границ разделов каждой записи.
- Когда все файлы манифеста найдены, все файлы данных для считывания окажутся у читателя. Теперь все эти файлы считываются им с помощью пути к файлам, получаемого также из файла манифеста.
- Процесс урезания разделов выполняется на двух уровнях: в Iceberg статистика о столбце раздела записывается и в списке, и в файлах манифеста. На первом ограничивается количество необходимых файлов манифеста, на втором — количество требуемых файлов данных.
- При считывании файла данных Parquet, чтобы избежать сканирования всего файла, читателем применяются другие фильтры запросов. Так выбираются нужные группы строк и только необходимые для считывания столбцы.
- Результат возвращается клиенту.
Опишем аспекты, связанные с эффективностью таблицы Iceberg.
Уплотнение
При каждом изменении в таблице Iceberg появляются новые файлы данных. При считывании таблицы, определив необходимые файлы данных, нужно открывать каждый файл, считывать его содержимое, а после закрывать. По мере увеличения количества считываемых файлов, эффективность процесса уменьшается.
Представьте себе таблицу Iceberg, разбитую на разделы обновленной временнóй меткой, с детализацией по дням. Данные в эту таблицу обычно записываются приложением ежедневно, поэтому в одном разделе оказывается много файлов данных. При считывании раздела нужно открывать и закрывать все эти файлы.
Что, если объединить их в один файл? Тогда открывать и сканировать придется только его.
В Icerberg периодическая перезапись данных всех этих файлов в меньшее количество файлов покрупнее называется уплотнением. Писателем записывается столько угодно файлов, в процессе уплотнения они перезаписываются в файлы большего размера для более эффективного использования читателем. Пользователи контролируют процесс, указывая стратегию уплотнения, фильтром ограничивая перечень перезаписываемых файлов, их целевой размер и т. д.
Скрытое разбиение на разделы
Обычно при разбиении таблицы на разделы с преобразованием в столбце — например, для разбиения по дням требуется преобразование выражения временнóй метки в день — создается дополнительный столбец. Он-то и задействуется пользователями при урезании разделов.
Например, таблица разбита на разделы по дням, и каждой записи необходим дополнительный столбец partition_day, полученный из столбца created_timestamp. При выполнении запроса в таблицу пользователям необходимо применить фильтр именно по этому столбцу partition_day, давая «знать» движку запросов, какие разделы ему пропустить. Если пользователь задействует столбец created_timestamp, таблица просканируется движком запросов целиком.
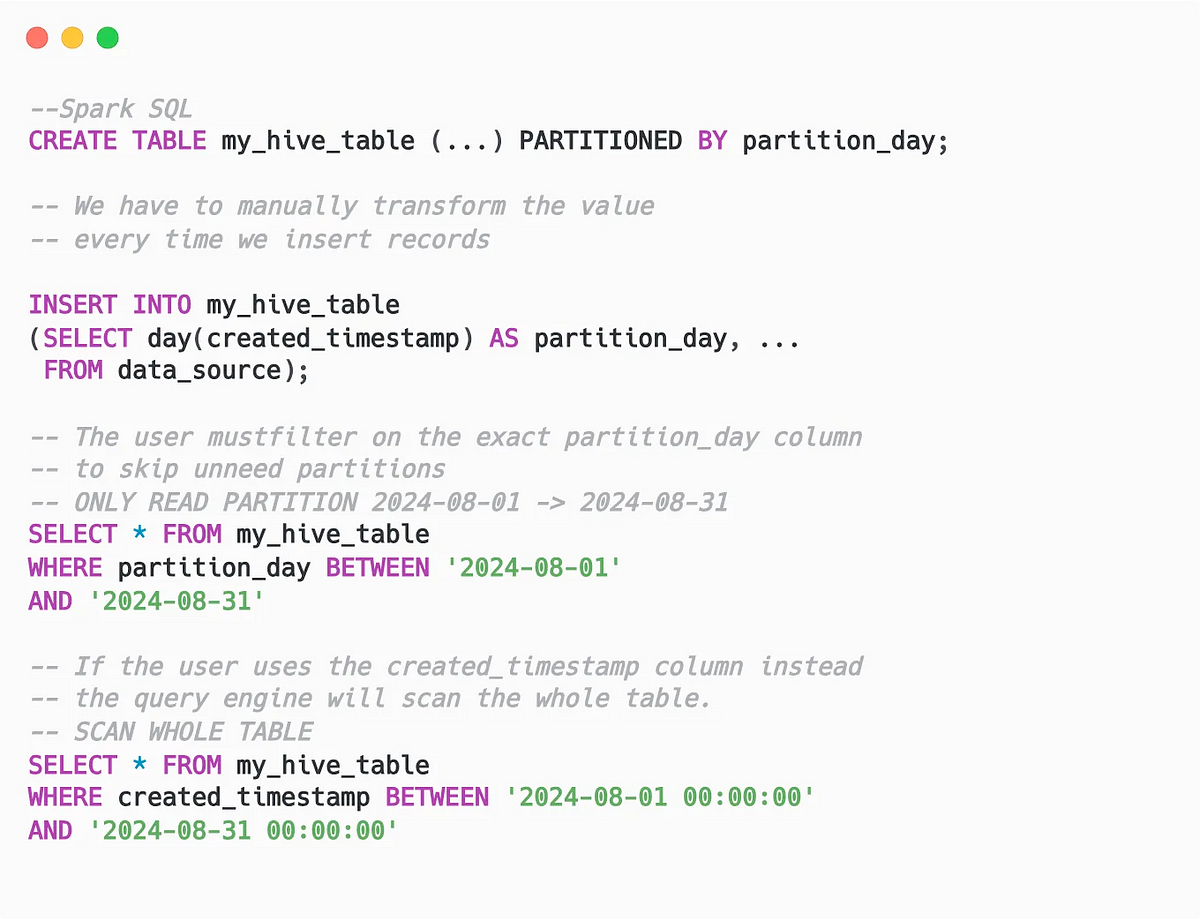
Но последний случай типичнее для аналитиков данных или бизнес-пользователей, которых интересуют конкретные аналитические вопросы: о дополнительном столбце для разбиения на разделы им знать не обязательно.
Здесь и приходится кстати скрытое разбиение на разделы Iceberg:
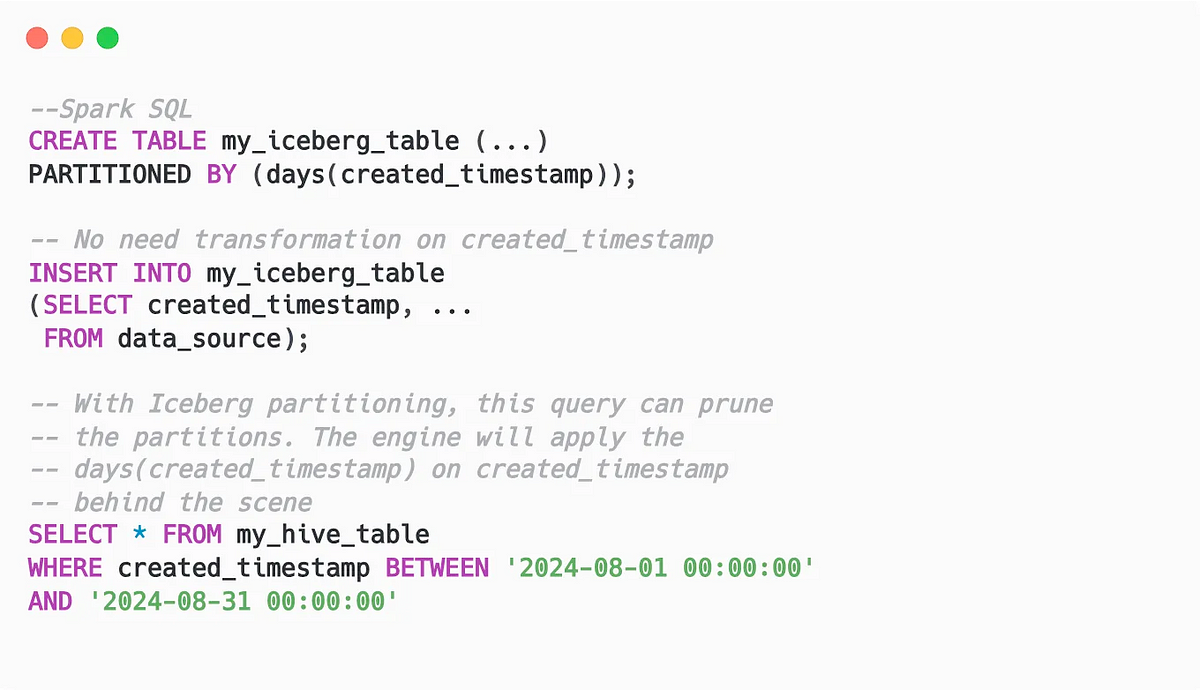
- Вместо того чтобы создавать дополнительные столбцы для разбиения на основе значений преобразования, в Iceberg записывается только используемое в столбце преобразование.
- Так в хранилище Iceberg сохраняется меньше данных, ведь дополнительных столбцов нет.
- Преобразование записывается метаданными в исходном столбце, пользователь этот столбец фильтрует, и движком запросов преобразование применяется для урезания данных.
Другая проблема традиционного разбиения на разделы — зависимость от физической структуры файлов, располагаемых в подкаталогах: чтобы поменять это разбиение, приходилось переписывать всю таблицу.
В Apache Iceberg проблема решается сохранением всех исторических схем разделов. Если таблица изначально разбивается по схеме A, а затем по схеме B, в Iceberg эта информация предоставляется движку запросов, где для повторной оценки фильтра по каждой схеме разделов создается два отдельных плана выполнения.
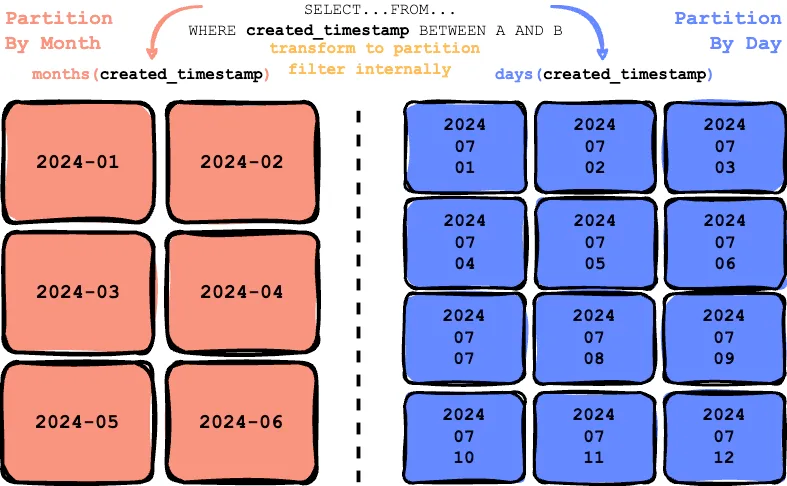
Если таблица изначально разбита на разделы по полю created_timestamp с помесячной детализацией, month(created_timestamp) записывается как первая схема разбиения. Затем пользователь обновляет таблицу разбиением по created_timestamp с детализацией по дням, записывая day(created_timestamp) как вторую схему разбиения.
Тем временем данные организуются по схеме разделов на момент записи: сохраняются в папках по месяцам с соответствующей разбивкой на разделы, а при разбивке по дням распределяются в папки по дням.

Когда эта таблица запрашивается приложением с помощью created_timestamp, для урезания разделов к created_timestamp движком запросов применяются первое и второе преобразования:
Сортировка
Разбиением на разделы файлы данных организуются по столбцам разделов, в Iceberg же благодаря сортировке предоставляется более детальный контроль над записыванием данных в эти файлы.
В таблице Iceberg, разбитой на разделы по дням, содержатся данные от четырех городов — Лондона, Милана, Парижа, Мадрида. Пользователь запрашивает данные из Милана за 08 августа 2024 года. Сначала движком запросов урезаются ненужные разделы, затем считываются соответствующие файлы данных. По этой дате имеется всего пять файлов. Данные из всех четырех городов разбросаны по этим файлам, поэтому для нахождения данных Милана движку необходимо открыть все пять файлов. Если же отсортировать данные по городам и объединить данные Милана в два конкретных файла, движку запросов нужно открыть только эти три файла, а не все десять.
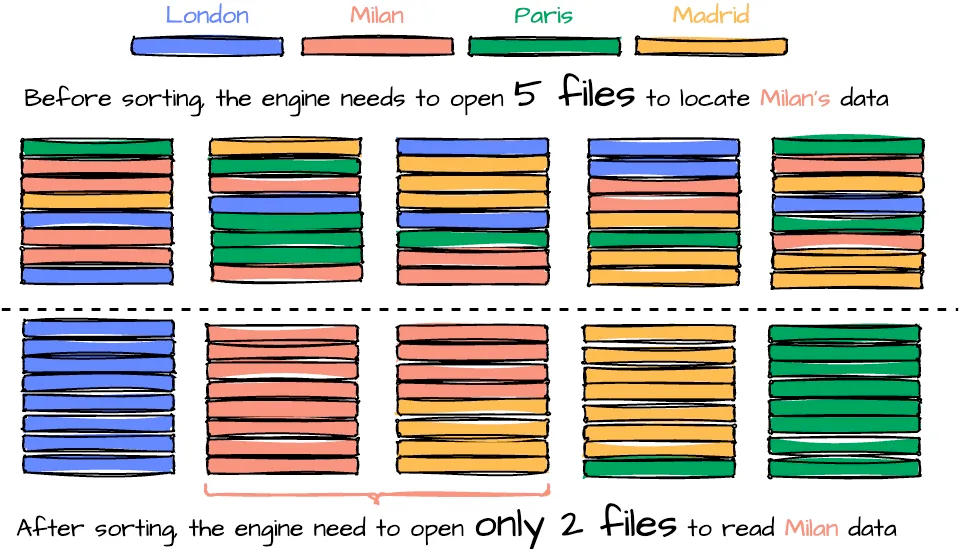
Считывание данных эффективнее благодаря сортировке, но процесс записи файлов данных сопряжен с дополнительными усилиями из-за необходимости сортировать данные при записи. Кроме того, для поддержания глобальной сортировки в файлах нужна задача уплотнения — перезаписи и сортировки данных во всех файлах. Поэтому, чтобы задействовать эту оптимизацию по максимуму, пользователям важно тщательно определить порядок сортировки таблицы.
Вот рекомендации по определению порядка на основе Tabular:
- Поместите столбцы для использования в фильтрах в начало последовательности на запись и задействуйте сперва столбцы с наименьшими числовыми значениями.
- Завершите последовательность столбцом с наивысшим числом, например идентификатором или временнóй меткой события.
Обновления на уровне строк
При записи в хранилище файлы данных не изменяются и не перезаписываются. При любых изменениях или обновлениях создаются новые файлы данных, чем обеспечиваются преимущества вроде изоляции снимков или перехода во времени. В Iceberg обновления на уровне строк обрабатываются в двух режимах: копирование при записи и объединение при считывании.
Копирование при записи
В Iceberg это режим по умолчанию. Если записи таблицы изменяются, обновляются или удаляются, связанные с ними файлы данных перезаписываются внесенными изменениями.
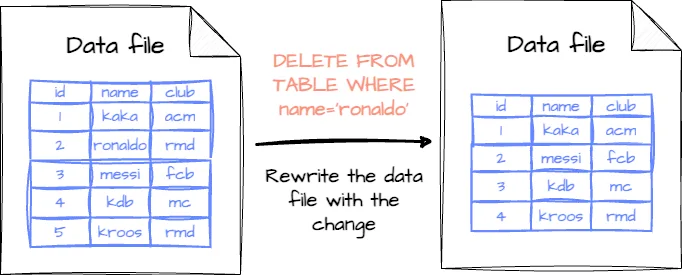
Плюсы: быстрое считывание; читателю нужно только считать данные, не объединяя их с удаленными или обновленными файлами.
Минусы: медленная запись; при перезаписи всех файлов данных замедляются обновления, особенно если они чрезмерно регулярны.
Объединение при считывании
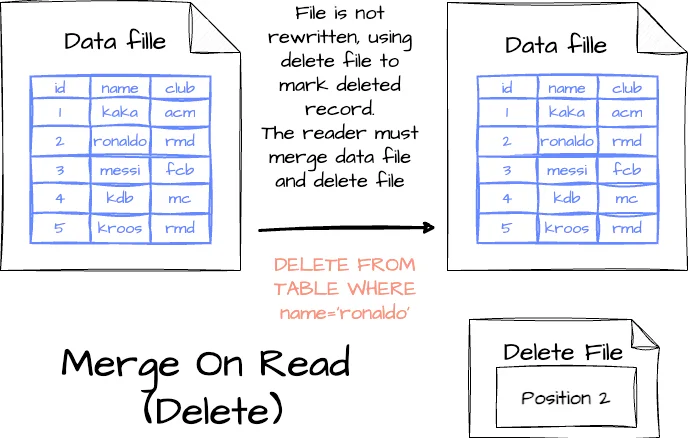
Вместо перезаписи всего файла данных выполняются обновления с использованием файлов удаления, при этом изменения отслеживаются в отдельных файлах:
- Удаление записи: запись приводится в файле удаления; при считывании таблицы данные объединяются читателем с файлом удаления и определяется, какую запись пропустить.
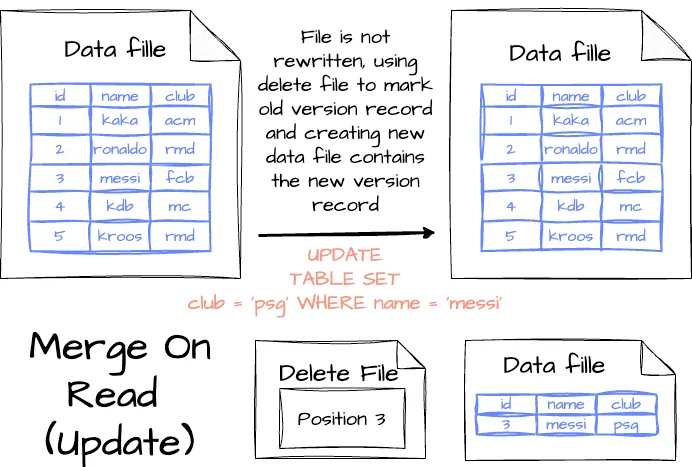
- Обновление записи: измененная запись также отслеживается в файле удаления, затем движком создается новый файл данных, в котором содержится запись с обновленным значением. Когда считывается таблица, старая версия записи движком игнорируется благодаря удаленному файлу, в новом файле данных используется новая версия.
В режиме объединения при считывании в хранилище больше файлов, чем в режиме копирования при записи. Чтобы минимизировать затраты на считывание данных, пользователь выполняет регулярные задачи уплотнения, уменьшая количество файлов.
Благодаря объединению при считывании, читателем отслеживается, какие записи игнорировать в будущем. Это поведение управляется двумя способами:
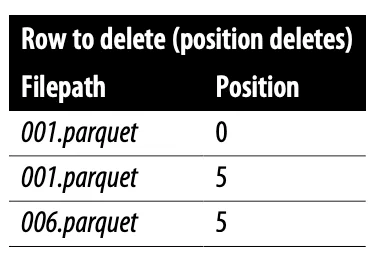
Файлы позиционного удаления: игнорируемые строки отслеживаются файлом удаления по их положению, так читателями пропускаются конкретные строки. Этим минимизируется время считывания, зато увеличивается время записи, ведь для выявления этих положений писателю необходимо считать файл.
Файлы равного удаления: файлами удаления указываются удаленные значения; если в строке имеется поле, соответствующее этому значению, строка пропускается. Этим вариантом от писателя не требуется считывать файл данных. Но это сказывается на эффективности считывания: чтобы сравнить каждую запись с удаленным значением, необходимо считать файл данных.

Читайте также:
- Создание локального озера данных с нуля
- 10 рекомендаций по Apache Airflow для дата-инженеров
- Apache Spark — типичные ошибки и их устранение
Читайте нас в Telegram, VK и Дзен
Перевод статьи Vu Trinh: I spent 7 hours diving deep into Apache Iceberg





