
ML на Go с Python в люльке
Модели машинного обучения быстро становятся все более функциональными. Как эти новые мощные инструменты можно использовать в приложениях на Go?
Для лучших коммерческих LLM, таких как ChatGPT, Gemini или Claude, модели предоставляются в виде независимых от языка REST API. Можно вручную создавать HTTP-запросы или использовать клиентские библиотеки (SDK), предоставленные вендорами LLM. Однако если нам нужны более индивидуальные решения, возникают кое-какие проблемы. Полностью индивидуальные модели обычно обучаются на Python при помощи таких инструментов, как TensorFlow, JAX или PyTorch, у которых нет реальных альтернатив, есть только Python.
Я представлю некоторые подходы, позволяющие Go-разработчикам использовать в своих приложениях модели ML, уровень настраиваемости будет расти. Резюмируя, можно сказать, что это довольно просто, иметь дело с Python придется по минимуму, если вообще придется.

Интернет-сервисы LLM
Это самая простая категория: мультимодальные сервисы от Google, OpenAI и других компаний доступны в виде REST API с удобными клиентскими библиотеками для большинства ведущих языков (включая Go), а также в виде сторонних пакетов, предоставляющих абстракции поверх (например, langchaingo).
Посетите официальный пост блога Go под названием «Создание приложений на базе LLM на Go». Он опубликован в этом году. Я писал об этом раньше в этих постах: #1, #2, #3 и т. д.
Go обычно поддерживается не хуже, чем другие языки программирования в этой области. На самом деле, Go из-за своей сетевой природы обладает уникальными для таких приложений возможностями. Вот цитата из поста в блоге Go:
Работа с сервисами LLM часто означает отправку запросов REST или RPC к сетевому сервису, ожидание ответа, отправку новых запросов другим сервисам на основе этого и так далее. Go превосходно справляется со всем этим, предоставляя отличные инструменты, чтобы управлять конкурентностью и сложностью манипулирования сетевыми сервисами.
Поскольку об этом уже говорилось в подробностях, давайте перейдем к ситуациям сложнее.
Локальные LLM
Есть много открытых моделей высокого качества1, которые можно выбрать для локального запуска — это Gemma, Llama, Mistral и многие другие. Хотя эти модели не так эффективны, как самые сильные коммерческие сервисы LLM, часто они хороши на удивление и по сравнению с другими имеют явные преимущества по стоимости и конфмденциальности.
В индустрии началась стандартизация некоторых общих форматов доставки и обмена этими моделями, например: GGUF из llama.cpp, safetensors из Hugging Face или более старый ONNX. Кроме того, есть ряд отличных инструментов OSS, позволяющих запускать такие модели локально и предоставлять для работы REST API, очень похожей на API OpenAI или Gemini, включая специальные клиентские библиотеки.
Наверное, самый известный такой инструмент — Ollama. Я много писал о нем: #1, #2, #3.
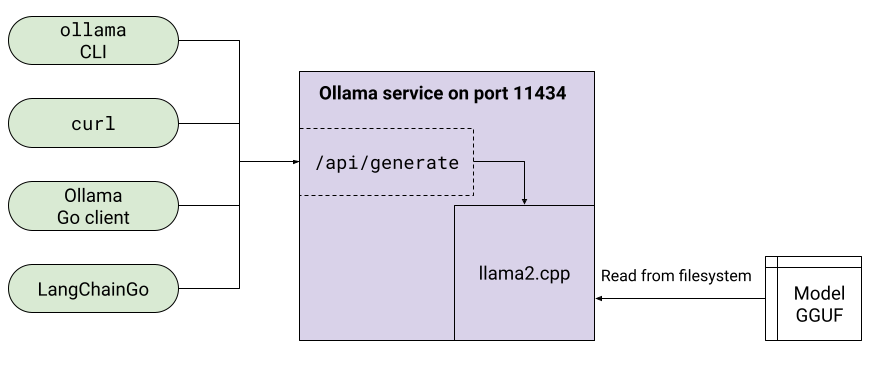
Ollama позволяет настраивать LLM через Modelfile, который включает в себя такие вещи, как настройка параметров модели, системные промпты и т. д. Если мы точно настроили модель2, ее можно загрузить в Ollama, определив собственный файл GGUF.
Если вы работаете в облачной среде, у некоторых вендоров уже есть готовые решения, которые могут оказаться полезными, например интеграция GCP Cloud Run.
Ollama — не единственный игрок. Недавно появился новый инструмент с несколько иным подходом. Llamafile распространяет всю модель как одного бинарный файл, который можно переносить на несколько ОС и архитектур ЦПУ. Как и Ollama, Llamafile предоставляет для модели REST API.
Если такая настраиваемая LLM подходит вашему проекту, рассмотрите запуск Ollama или Llamafile с применением REST API, чтобы связываться с моделью. А если вам нужно еще больше настраиваемости, читайте дальше.
Заметка о шаблоне Sidecar
Прежде чем мы продолжим, я хочу кратко рассказать о шаблоне развертывания приложений Sidecar. Ссылка на k8s посвящена контейнерам, но шаблон не ограничивается ими. Он применим к любой архитектуре ПО, где функциональность изолирована между процессами.
Предположим, у нас есть приложение, которому требуются какая-то библиотечная функциональность. На примере Go можно найти подходящий пакет, импортировать его и продолжить путь. Предположим, однако, что подходящего пакета для Go нет. Если есть библиотеки с интерфейсом на языке C, для их импорта в качестве альтернативы можно воспользоваться cgo.
Но снова предположим, что C API также нет, например, если функциональность предоставляется только языком без удобного интерфейса экспортирования. Может быть, это Lisp, Perl или… Python.
Очень общим решением может стать обертывание нужного нам кода в какой-то серверный интерфейс и его запуск в качестве отдельного процесса. Такой процесс называется сопровождающим — он запускается специально для предоставления дополнительных функций другому процессу. Какой бы механизм межпроцессного взаимодействия (IPC) мы ни использовали, у этого подхода много преимуществ — изоляция, безопасность, языковая независимость и т. д. В современном мире контейнеров и оркестрации этот подход становится все более распространенным. Вот почему многие ссылки о Sidecar ведут на k8s и другие контейнерные решения.

Подход Ollama — один из примеров применения Sidecar. Ollama предоставляет функциональность LLM, но работает как сервер, в собственном процессе.
Решения, представленные в оставшейся части статьи, — это более явные и полностью проработанные примеры использования Sidecar.
Локально выполняемая LLM с Python и JAX
Предположим, ни одна из существующих открытых LLM, даже доработанных, не подойдет для нашего проекта. На этом этапе можно рассмотреть возможность обучения собственной LLM — это очень дорого, но, возможно, выбора нет. Обучение обычно подразумевает одну из крупных платформ машинного обучения, например TensorFlow, JAX или PyTorch. В этом разделе я не буду говорить о том, как обучать модели. Вместо этого я покажу, как запустить локальный вывод уже обученной модели на Python с JAX и использовать ее как дополнительный сервер для приложения на Go.
Пример (весь код здесь) основан на коде из официальном репозитории Gemma, применяется его библиотека sampler3. Она поставляется с README, где объясняется, как все настроить.
Этот код создает экземпляр sampler для Gemma:
# После инициализации он будет содержать экземпляр sampler_lib.Sampler, который
# может использоваться для генерации текста.
gemma_sampler = None
def initialize_gemma():
"""Инициализируйте sampler Gemma, загрузив модель в GPU."""
model_checkpoint = os.getenv("MODEL_CHECKPOINT")
model_tokenizer = os.getenv("MODEL_TOKENIZER")
parameters = params_lib.load_and_format_params(model_checkpoint)
print("Parameters loaded")
vocab = spm.SentencePieceProcessor()
vocab.Load(model_tokenizer)
transformer_config = transformer_lib.TransformerConfig.from_params(
parameters,
cache_size=1024,
)
transformer = transformer_lib.Transformer(transformer_config)
global gemma_sampler
gemma_sampler = sampler_lib.Sampler(
transformer=transformer,
vocab=vocab,
params=parameters["transformer"],
)
print("Sampler ready")Веса модели и словарь токенизатора — это файлы, загруженные с Kaggle, в соответствии с инструкциями в README репозитория Gemma.
Итак, у нас есть вывод LLM, работающий на Python. Как использовать его из Go?
Конечно же, при помощи Sidecar. На основе этой модели мы создадим быстрый веб-сервер и на локальном порте предоставим тривиальный интерфейс REST, с которым сможет общаться Go или любой другой инструмент. Как пример по этому коду вывода я настроил веб-сервер на базе Flask. Он вызывается при помощи gunicorn. Подробности смотрите в скрипте оболочки.
Вот весь код приложения, кроме импорта:
def create_app():
# Создаем приложение и выполняем однократную инициализацию Gemma.
app = Flask(__name__)
with app.app_context():
initialize_gemma()
return app
app = create_app()
# Маршрут для echo / дымового теста.
@app.route("/echo", methods=["POST"])
def echo():
prompt = request.json["prompt"]
return {"echo_prompt": prompt}
# Реальный маршрут для генерации текста.
@app.route("/prompt", methods=["POST"])
def prompt():
prompt = request.json["prompt"]
# Для total_generation_steps 128 — это умолчание, взятое из репозитория Gemma
# Это компромисс между скоростью и качеством (значения больше —
# качество выше, но генерация медленнее).
# Пользователь может переопределить его, указав ключ "sampling_steps"
# в запросе JSON.
sampling_steps = request.json.get("sampling_steps", 128)
sampled_str = gemma_sampler(
input_strings=[prompt],
total_generation_steps=int(sampling_steps),
).text
return {"response": sampled_str}Сервер предоставляет два маршрута:
prompt— клиент отправляет промпт, сервер выполняет вывод Gemma и в JSON-ответе возвращает сгенерированный текст;echo— для тестирования и бенчмарков.
Вот как все это выглядит в совокупности:

Важный вывод здесь в том, что это всего лишь пример. Буквально любую часть этой структуры можно изменить: можно использовать другую библиотеку ML (возможно, PyTorch вместо JAX); можно использовать другую модель (не Gemma и даже не LLM), можно использовать другую структуру, чтобы создать веб-сервер на ее основе. Вариантов много, и каждый разработчик выберет тот, что лучше всего подходит для его проекта.
Также стоит отметить, что в итоге мы написали меньше 100 строк кода на Python, а большая часть из них представляет из себя фрагменты туториалов. Этого небольшого количества Python-кода достаточно, чтобы обернуть HTTP-сервер с простым REST-интерфейсом вокруг LLM, локально работающей на GPU через JAX. С этого момента мы благополучно возвращаемся к бизнес-логике приложения и Go.
И теперь несколько слов о производительности. Одна из проблем, с которой могут столкнуться разработчики решений на основе Sidecar, — это накладные расходы на производительность из-за межпроцессного взаимодействия Python и Go. Конечную точку echo я добавил, чтобы измерить этот эффект.
Взгляните на клиент Go, который выполняет запрос. На моей машине задержка отправки запроса JSON от Go на Python-сервер, а затем получения обратного ответа echo в среднем составляет около 0,35 мс. Это совершенно незначительно по сравнению со временем, которое для того же требует Gemma. Обычно ее задержка измеряется секундами или, может бытьпосотнями миллисекунд — на очень мощных GPU.
При этом не каждая пользовательская модель, которую может понадобиться запустить, является полноценной LLM. Что, если ваша модель маленькая и быстрая, и накладные расходы в 0,35 мс становятся значительными? Не волнуйтесь, такие расходы можно оптимизировать. И это тема следующего раздела.
Локально выполняемая быстрая модель для изображений на Python и TensorFlow
Последний пример этого поста вносит небольшую путаницу:
- Вместо LLM будем использовать быструю модель для изображений.
- Обучим ее отдельно, также вместо JAX используя TensorFlow и Keras.
- Вместо HTTP и REST используем другой метод IPC Python-сервера для Sidecar с его клиентами.
Модель по-прежнему реализована на Python в качестве Sidecar-сервера и все так же управляется клиентом на Go4. Идея в том, чтобы показать универсальность подхода Sidecar и IPC с меньшей задержкой.
Весь код примера вы найдете здесь. Этот код обучает простую CNN (сверточную нейронную сеть) классифицировать изображения набора данных CIFAR-10:

Структуру нейронной сети с TensorFlow и Keras я взял из официального руководства.
Вот полное определение сети:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation="relu", input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10))Изображения из CIFAR-10 имеют размер 32×32 пикселя, каждый из которых имеет 3 значения — красного, зеленого и синего цветов. В исходном наборе данных эти значения представляют собой байты со значениями от 0 до 255 включительно — интенсивность цвета. Это объясняет размерность (32, 32, 3), которая появляется в коде. Весь код обучения модели находится в файле train.py внутри примера. Какое-то время он работает, а затем сохраняет сериализованную модель с обученными весами в локальный файл.
Следующий компонент — «сервер изображений». Он загружает с диска обученный файл модели+весов, выполняет логический вывод по переданным в него изображениям и для каждого изображения возвращает метку, наиболее вероятную по мнению модели.
Однако этот сервер не использует HTTP и REST. Он создает сокет домена Unix и для связи использует простой протокол кодирования с длиной-префиксом:

Каждый пакет начинается с 4-байтового поля, которое определяет длину остального содержимого. Тип — это [всегда] один байт, тело может быть любым5.
Пример сервера изображений сейчас поддерживает две команды:
0означаетecho— сервер ответит клиенту тем же пакетом. Содержание тела пакета не существенно;1означает «классифицировать».
Тело пакета интерпретируется как изображение RGB размером 32×32, красный канал каждого пикселя закодирован в первых 1024 байтах (32×32, основной ряд), зеленый — в следующих 1024 байтах и, наконец, синий — в последних 1024 байтах. Здесь сервер пропустит изображение через модель и ответит меткой, которая, по мнению модели, описывает изображение.
Пример также содержит простой клиент Go, который может брать PNG-файл с диска, кодировать его в требуемый формат и отправлять через сокет домена на сервер, записывая ответ.
Клиент можно использовать, чтобы оценить задержку при обмене сообщениями туда и обратно. Легче просто показать код, чем объяснять, что он делает:
func runBenchmark(c net.Conn, numIters int) {
// Создаем []byte с 3072 байтами.
body := make([]byte, 3072)
for i := range body {
body[i] = byte(i % 256)
}
t1 := time.Now()
for range numIters {
sendPacket(c, messageTypeEcho, body)
cmd, resp := readPacket(c)
if cmd != 0 || len(resp) != len(body) {
log.Fatal("bad response")
}
}
elapsed := time.Since(t1)
fmt.Printf("Num packets: %d, Elapsed time: %s\n", numIters, elapsed)
fmt.Printf("Average time per request: %d ns\n", elapsed.Nanoseconds()/int64(numIters))
}В ходе моего тестирования средняя задержка туда и обратно составила около 10 мкс (это микросекунды). Учитывая размер сообщения и то, что на другом конце находится Python, это примерно соответствует моим тестам задержки сокетов домена Unix в Go.
Сколько времени занимает вывод одного изображения при помощи этой модели? По моим измерениям около 3 мс. Напомню, что задержка коммуникации при подходе HTTP+REST составляла 0,35 мс. Хотя это составляет всего 12% времени вывода изображения, оно достаточно близко к тому, чтобы вызывать беспокойство. На мощном GPU серверного класса время может быть намного короче6.
При использовании специального протокола через доменные сокеты задержка в 10 мкс кажется совершенно незначительной, независимо от того, что вы в конечном счете запускаете на своем GPU.
Код
Весь код примеров из этого поста находится на GitHub.
1. Если быть педантичным, то эти модели открыты не полностью: открыта архитектура вывода и доступны веса, но детали обучения модели остаются собственностью компании.
2. Детали тонкой настройки моделей выходят за рамки этой статьи, но в сети есть множество ресурсов по этому поводу.
3. «Семплирование» в LLM примерно означает «вывод». Обученной модели подается входной промпт, затем он «семплируется» для получения выходных данных.
4. В моих примерах сервер на Python и клиент на Go просто работают в разных терминалах и общаются друг с другом, а структура управления сервисами очень специфична для проекта. Можно представить себе подход, при котором приложение Go запускает Python-сервер для работы в фоновом режиме и взаимодействует с ним. Однако в наши дни все более вероятна контейнерная установка, когда каждая программа — это отдельный контейнер, а решение оркестрации запускает эти контейнеры и управляет ими.
5. Вам может быть интересно, почему я реализую здесь собственный протокол вместо того, чтобы использовать что-то известное. В реальной жизни я бы определенно рекомендовал использовать что-то вроде gRPC. Однако ради этого примера мне хотелось чего-то (1) простого без дополнительных библиотек и (2) очень быстрого. Кстати, не думаю, что показатели задержки для gRPC будут сильно отличаться. Прочтите мою публикацию об RPC через доменные сокеты Unix на Go.
6. С другой стороны, модель, которую я здесь использую, на самом деле мала. Справедливо сказать, что реалистичные модели, которые вы будете применять в своем приложении, будут намного больше и, следовательно, медленнее.
Читайте также:
- Генерация аналитических данных из PDF-файлов с помощью Apryse и GPT
- Текстовой эмбеддинг: классификация и семантический поиск
- Создание LLM-приложений: четкое пошаговое руководство
Читайте нас в Telegram, VK и Дзен
Перевод статьи Eli Bendersky: ML in Go with a Python sidecar





