
Введение
После реализации множества проектов в разных командах я понял одну простую вещь: не все разработчики думают о том, что будет с их проектом. «Субъективное» благополучие одного человека или группы разработчиков сейчас важнее, чем будущая поддержка и развитие проекта, не говоря уже о конечном пользователе продукта.
Как следствие, выполнение любых простых задач, которые можно решить за 1-2 часа, выливается в недели разработки. Почему? Потому что команда разработчиков не может ничего изменить без рефакторинга.
Ваш менеджер по разработке уже знает, каким будет диалог, еще до постановки какой-либо задачи.

Если вы команда энтузиастов, работающая над проектом с открытым исходным кодом, — у вас много свободного времени, меняйте код хоть по 100 раз на день. Но если вы работаете в бизнесе, то не можете тратить все свое время на изменение кода только потому, что считаете его недостаточно абстрактным или не соответствующим требованиям SOLID.
Для меня, как человека, руководившего множеством проектов, важно получить результат в оговоренные сроки, а не тратить рабочее время и ресурсы на создание абстракции ради абстракции из-за пары повторений кода. Да, вечный конфликт интересов разработки ПО и бизнеса заключается в том, на что тратить ресурсы — что в данный момент важнее, а что менее приоритетно.
В этой статье рассмотрим несколько основополагающих правил, которые помогут сократить объем потенциального технического долга и обеспечить беспроблемное развитие проекта. Не будем углубляться в конкретные ситуации и затрагивать весь спектр возможных решений — разберем только базовые практики.
Выбор технологии
Это один из самых важных этапов при запуске любого фронтенд-проекта. Не поленитесь собрать как можно больше требований к проекту на старте, даже несмотря на MVP-статус разрабатываемого продукта (MVP — minimum viable product — минимально жизнеспособный продукт). Выбор технологии — не только шанс найти лучшее на данный момент решение, но и возможность безболезненно отказаться от него в будущем, если первоначальные требования к проекту изменятся.
Является ли страница «маркетинговой»?
Любая фронтенд-разработка нацелена прежде всего на создание конечной версии сайта для определенного пользователя. Чем лучше веб-страница воспринимается разными пользователями на разных устройствах, тем выше шанс получить желанные для бизнеса лиды.
Выход сайта в топ поиска, его быстрый отклик, возможность взаимодействия со страницей в первые секунды и другие возможности — вот задача фронтенд-разработки.
SEO здесь имеет решающее значение, включая следующие требования:
- метрики страницы (Core Web Vitals);
- robots.txt;
- метаданные (Open-Graph, Twitter Card, keywords);
- микроданные (JSON-LD);
- время отклика (CDN);
- оптимизация изображений и CSS;
- семантически корректная разметка HTML (иерархия заголовков).
Варианты возможных технологий:
- Статические: HTML, HTMX;
- SSG (static site generator — генерирование содержимого сайта в html-файлы): Gatsby, Astro;
- Решения SSR (server-side rendering — генерирование html на стороне сервера): NextJs, NuxtJs (пререндеринг).
Какая часть страницы является «интерактивной»?
Допустим, ваше приложение — не просто набор текстовых блоков с формой заявки, а требует Google Maps, диалоговых окон, анимации прокрутки и других функций, которые невозможно реализовать в HTML (в принципе можно, но крайне затруднительно для поддержки таких решений).
В данном случае многое будет определять количество CSS и JS, передаваемых на сторону клиента.
Помимо поддержки SEO-показателей, с увеличением работ по сборке исходников потребуется:
- обеспечить ленивую загрузку скриптов в нужный момент, не влияя на сборку исходников;
- не перегружать пользователя лишними скриптами (используя библиотеки React-hook-form и Zod), а оставить валидацию данных на сервере;
- разделить CSS на критические и ленивые компоненты для разных размеров представлений;
- определить ленивые компоненты и подготовить для них скелетную загрузку.
Варианты возможных технологий:
- Статический генератор: Astro (компоненты Server Islands);
- SSR-решения: NextJs, NuxtJs, Remix.
Что, если приложение не нуждается в SEO?
В альтернативных случаях, когда приложение не нуждается в SEO, можно использовать стандартный SPA-подход (SPA — single-page application — одностраничное приложение). Это самое простое решение, но с рядом ограничений в выборе технологии, зависящих от среды, в которой используется приложение, и его будущего размера.
Важно определить назначение SPA:
- внутреннее приложение с широкополосным подключением;
- внешнее приложение для работы с данными (CMS, CRM и т. д.);
- SPA, требующее развития в направлении PWA (progressive web app — прогрессивное веб-приложение).
Варианты возможных технологий:
- Angular;
- React;
- Vue.
Архитектура репозитория
Как ни странно, корректно выбранная архитектура хранилища зачастую определяет наиболее эффективную архитектуру приложения. Необходимо понимать, что не существует правильных или неправильных архитектур, есть только более подходящие архитектуры для конкретных задач и проблем.
Пример из личной практики
Однажды я столкнулся с ситуацией, когда для каждой новой библиотеки разрабатывался отдельный репозиторий. Создание любой новой функции занимало очень много времени и сопровождалось длительным процессом релиза. Ведь помимо обновления кода в репозитории библиотеки, необходимо было публиковать rc-версию библиотеки для других библиотек и обновлять их по цепочке.

Самое главное, что эти библиотеки не были абстрактными и требовали только одной окончательного версии приложения.
Вот ряд вопросов, на которые невозможно получить ответы в такой ситуации:
- Какова архитектура приложения?
- По какому принципу добавлялся и масштабировался новый код?
- Существуют ли диаграмма зависимостей между пакетами библиотек и диаграмма слоев?
Знаю, в это трудно поверить, но так и было. Не допускайте ничего подобного.

Другая тупиковая ситуация — когда разработчики полагаются на примитивные статьи с таким содержанием: «У вас должны быть папки Core, Features и Shared. Это и есть чистая архитектура».

При таком подходе каталог Shared со временем превратится в «мусорный бак для всего»:
- Используется более 2 раз? — Shared.
- Абстрактный элемент? — Shared.
- API и DTO-сервисы? — Shared.
Подобные примеры можно приводить до бесконечности. Так какие вопросы необходимо задать себе, чтобы определить наиболее подходящую архитектуру.
Будет ли несколько приложений?
Всегда задавайтесь вопросом «Будет ли несколько приложений?», даже если кажется, что для этого нет причин.
На данном этапе невозможно заглянуть в будущее и сказать, что у вас будет 33 приложения и 140 библиотек для них. Но просто представьте, что 50 % вашего кода придется использовать в новом приложении. Рефакторинг? Разработка по принципу «любой абстрактный компонент должен быть общим»? Вам нужно заложить фундамент на будущее, чтобы при решении новых задач отталкиваться от предыдущего опыта.
В любой неопределенной ситуации попробуйте начать разработку с создания монорепозитория + DDD (domain driven design — предметно-ориентированное проектирование).
На мой взгляд, «монорепозиторий + DDD» — панацея на все случаи жизни.
Вот несколько преимуществ этого подхода:
- Граф зависимостей. Монорепозиторий требует инструментов управления репозиторием — Nx, Lerna или Turborepo. Их главное преимущество в том, что они могут построить график зависимостей объектов даже для 1 приложения, которое можно визуализировать (например, Nx). Это избавляет от ведения тонн документации по архитектуре приложения, позволяя наглядно судить о добавлении новых модулей и слоев, а не предполагать по структуре папок, «как организовано то или иное приложение» в рамках DDD.
- Shared — не черная дыра. Все, что нужно сделать при добавлении нового приложения, — переместить требуемый модуль из домена конкретного приложения в общий домен. Процент повторного использования кода может варьироваться от 1 до 90 %. Создание и использование общего домена имеют совершенно определенную цель.
- Удобство работы с MF-приложениями (MF — micro-frontend — микро-фронтенд). Благодаря графу зависимостей, запуск большого хост-приложения больше не является проблемой. Все необходимые MF-приложения разворачиваются вместе с основным приложением без необходимости явного указания всех MF-приложений в npm-скриптах.
- Валидация слоев. Наличие валидации взаимосвязи между слоями посредством Eslint (см. обсуждение ниже).
- Модульность. Если вы думаете, что поддерживать монорепозиторий со временем станет проблематично из-за множества связей между модулями и их перепроверками при изменении основных компонентов — не волнуйтесь, это этап «эволюции репозитория». На этом этапе вы поймете, что некоторым приложениям больше не нужны сильные связи с текущими базовыми компонентами монорепозитория и что для работы достаточно иметь их фиксированную стабильную версию кода. Можете смело перенести текущие приложения в отдельный репозиторий с отдельным CI.
Будет ли только одно приложение?
Для этого вопроса подойдет даже ответ «мы разработаем монолит».
Проблема монолитов хорошо известна. Поэтому, чтобы ваши репозитории и код не выглядели как клубок ниток, залитый суперклеем, рассмотрите, как вариант, метод FSD (Feature-Sliced Design — послойное проектирование функциональности).
Метод FSD предназначен для работы в рамках приложения (единого домена), в котором указано, как разделить код на уровни, слои и сегменты. В итоге получается монолит, но распределенный.
Кроме того, рассмотрите метод DDD (Domain-Driven Design — предметно-ориентированное проектирование), который обеспечит вашим подстраницам отдельные домены.
Разделение кода и зон ответственности
Следующий шаг после выбора архитектуры репозитория и приложения (приложений) — определение способов обеспечения соблюдения правил архитектуры для обслуживания и масштабирования.
Независимо от выбранной архитектуры приложения, необходимо иметь возможность проверять взаимосвязи между его уровнями, библиотеками и модулями. Не стоит сводить эту проверку к ревизии кода или анализу архитектуры — полезнее сделать отношения между всеми сущностями саморегулируемыми.
Попробуйте мыслить категориями трудоустройства: «каждый день новый сотрудник», когда не нужно каждый раз объяснять, «как создавать и добавлять новый код» — архитектура просто не допустит неправильное использование этого кода.
Предположим, вы создали некую DDD-подобную архитектуру, где в каждом домене будет четыре слоя:
- Слой приложения (App layer) — окончательная версия приложения, предоставляемая пользователю.
- Слой функциональности (Feature layer) — объединение компонентов, сервисов и утилит в функциональные единицы.
- Базовый слой (Base layer) — дополнительный уровень между функциональностью и абстракциями для создания многократно используемых сущностей в домене.
- Слой абстракций (Abstract layer) — уровень, на котором сущности не знают своего назначения и создаются под единственную ответственность.
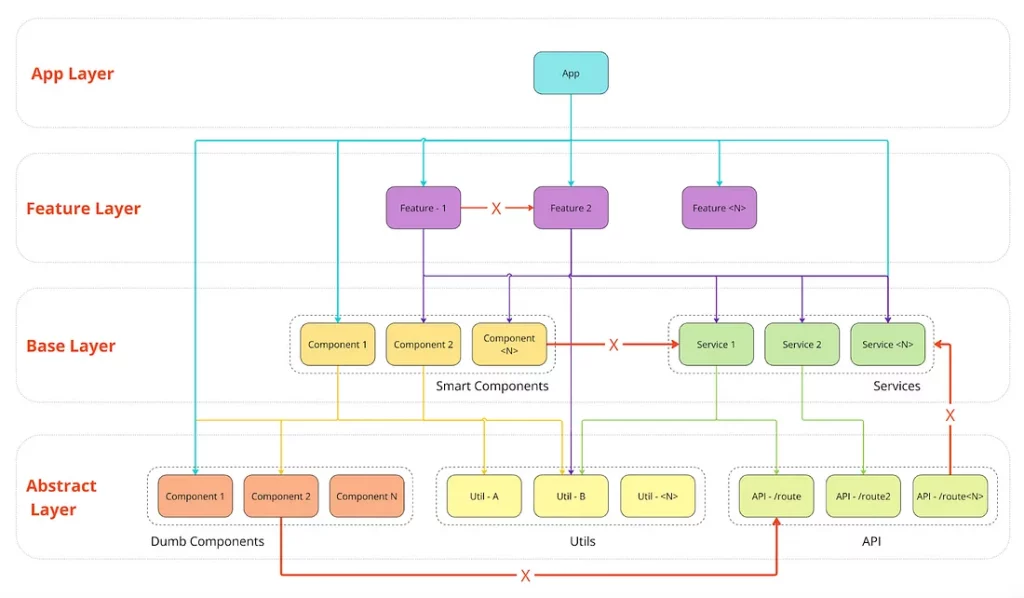
Каждый новый слой в этой архитектуре может ссылаться на предыдущий слой, вплоть до начального. Но «младшие» слои не могут запрашивать код у «старшего» слоя, как и сущности внутри слоя не могут взаимодействовать друг с другом в пределах текущего домена.
Я опустил детали, связанные с доменом Shared, который предоставляет многократно используемые сущности для каждого домена, поскольку отношения между слоями повторяются в каждом отдельном домене.
Как сделать такую схему саморегулируемой и поддерживаемой в течение длительного периода времени?
Проверка использования модуля
- Eslint — import/no-cycle
Обычно, как только создается какой-либо поддомен или логический слой, разработчики пытаются обозначить его с помощью псевдонимов в tsconfig.json. Проблемы возникают, когда код, экспортируемый через index.ts из поддомена, становится циклическим из-за использования в промежуточных областях.
К сожалению, typescript прощает такие ошибки, потому что циклическая зависимость может быть косвенной, и вы не получаете уведомления о проблеме. Неважно, используете ли вы фактический код или объявление типов, вы нарушили границы между модулями во время разработки.

Правило import/no-cycle — отличный способ решить эту проблему.
Если вы используете непрямую циклическую зависимость, то на этапе разработки или при валидации кода в CI получите ошибку, которая будет сигнализировать о том, что вы взаимодействуете с другим слоем или неправильно создаете код.
- Подход на основе NPM-пакетов
Это более сложный в поддержке подход, но и более надежный. Суть его в том, что любая библиотека или модуль — это npm-пакет, используемый разработчиком через локальную систему установки пакетов.
Преимущества:
- При наличии циклической зависимости сборка нарушится, поскольку невозможно установить библиотеку, которая зависит от другой библиотеки в цикле.
- В сочетании с правилом
import/no-extraneous-dependencies, можно добиться прозрачности использования кода в библиотеке, явно объявив все внешние зависимости в package.json.
- Учитывая процесс «эволюции репозитория», все, что нужно сделать — изменить флаг
private: true->private: falseи использовать код пакета в новом выделенном репозитории через npm-registry. Все ссылки и способы определения кода остаются прежними.
- Код ограничен только вашим пакетом. Это означает, что вам не нужно создавать сложные имена для констант, классов или интерфейсов. Сложные имена, если хотите, можете объявить в выходном файле пакета (
index.ts \ public_api.ts).
Проверка взаимосвязи между слоями и доменами
Как уже упоминалось, при разработке с использованием DDD предусматривается проверка с помощью Eslint. Это очень полезно, когда необходимо обеспечить самоуправляемую архитектуру.
- Обеспечение соблюдения границ модулей (enforce module boundaries)
Это решение, поставляемое по умолчанию с Nx. Для нашей архитектуры достаточно объявить простую конфигурацию:
{
"@nx/enforce-module-boundaries": [
"error",
{
"allow": [],
"depConstraints": [
{
"sourceTag": "scope:shared",
"onlyDependOnLibsWithTags": ["scope:shared"]
},
{
"sourceTag": "scope:some-domain",
"onlyDependOnLibsWithTags": ["scope:shared", "scope:some-domain"]
},
{
"sourceTag": "layer:app",
"onlyDependOnLibsWithTags": ["layer:abstract", "layer:based", "layer:feature"]
},
{
"sourceTag": "layer:feature",
"onlyDependOnLibsWithTags": ["layer:abstract", "layer:based"]
},
{
"sourceTag": "layer:based",
"onlyDependOnLibsWithTags": ["layer:abstract"]
},
{
"sourceTag": "layer:abstract",
"onlyDependOnLibsWithTags": []
}
]
}
]
}
Где:
- разрешается совместное использование кода только в общем (shared) домене:
{
"sourceTag": "scope:shared",
"onlyDependOnLibsWithTags": ["scope:shared"]
}
- домен может использовать свои зависимости и только общие (shared) зависимости:
{
"sourceTag": "scope:some-domain",
"onlyDependOnLibsWithTags": ["scope:shared", "scope:some-domain"]
}
- устанавливается область использования кода из библиотек между слоями:
{
"sourceTag": "layer:app",
"onlyDependOnLibsWithTags": ["layer:abstract", "layer:based", "layer:feature"]
},
{
"sourceTag": "layer:feature",
"onlyDependOnLibsWithTags": ["layer:abstract", "layer:based"]
},
{
"sourceTag": "layer:based",
"onlyDependOnLibsWithTags": ["layer:abstract"]
},
{
"sourceTag": "layer:abstract",
"onlyDependOnLibsWithTags": []
}
Для корректной валидации взаимодействия между слоями больше ничего не нужно.
Чтобы этот плагин и его настройки правил работали, необходимо обернуть каждый модуль во внутренний проект Nx и добавить соответствующие теги. По сути, вы создаете код с помощью «библиотек», обеспечивая «мелкомодульность» репозитория.
Начинающему разработчику это может показаться излишним: «Зачем создавать библиотеку, если она будет использоваться только один раз?»
Отчасти такой вопрос правомерен. Но необходимость создавать отдельный Nx-проект для каждого модуля помогает в реализации подхода NPM-package based (на основе NPM-пакетов), позволяющего просто добавить package.json в созданный проект.
Стоит отметить, что «мелкомодульность» повышает эффективность проверки кода в рамках валидации в CI благодаря наличию графа зависимостей. Если изменения произошли в App-слое, то код будет проверен только из этого слоя, что сокращает время валидации в CI.
Этот плагин служит расширением правила @nx/enforce-module-boundaries. Он автоматически генерирует теги на основе вложенности папок в index.ts и обеспечивает лаконичное расположение и унификацию созданных Nx-проектов в репозитории.
Плагин также может применяться к файловым структурам и определению границ использования кода за пределами экосистемы монорепозитория, например, в том же FSD. Правильное размещение папок, хотя и не создает архитектуру, помогает установить структурные границы и конкретные имена каталогов для слоев, сегментов и срезов.
Итак, вы выбрали подход и создали фреймворк для проверки слоев. Что дальше?
Проверка кода
Вам понадобятся инструменты для проверки кода как на этапе разработки, так и на этапе сборки в конвейере CI/CD.
Typescript + строгий режим
Хотя некоторые команды отказываются от Typescript и продолжают разрабатывать на Javascript, Typescript, на мой взгляд, предлагает разработчикам некоторые преимущества.
Основное назначение Typescript — сообщить разработчику, что его код и ожидания по взаимодействию с ним будут полностью реализованы в остальном коде.
Это очень удобно, когда не нужно держать в голове тысячи фактов о том, где и как используется ваша функция.
Да, вы можете возразить, что это бюрократизм, усложняющий код и заставляющий тщательно описывать все моменты. Но на начальном этапе проекта, когда время имеет решающее значение, вы не можете его тратить на написание тестов или ручную проверку всех случаев использования. Даже если в будущем вам придется рефакторить такой код, у вас уже будут объявленные контракты, а благодаря Typescript вы получите сигналы о том, что функция используется некорректно.
Строгий режим (strict mode) — ваш друг. Отключая проверку allowUnreachableCode и noUnusedLocals, вы увеличиваете количество потенциальных ошибок, как сейчас, так и в будущем.
Линтеры
Трудно представить, что сегодня никто не использует линтеры для проверки кода и обеспечения его согласованности. Упрощенно говоря, линтеры — это дополнительная автоматическая валидация кода за пределами конструкторов, которые не могут проверить код с помощью стандартных инструментов.
Популярными инструментами являются Eslint и Stylelint, но cSpell и Sonar также заслуживают внимания.
Самый важный аспект использования линтеров — придерживаться принципа «правило либо действует (error), либо отключено (off)».
Почему нельзя использовать предупреждение (warn)? — Потому что это разрешение на ошибку, и разработчики будут игнорировать это warn.

Правило либо должно строго соблюдаться с обязательным исправлением нарушений, либо оно неважно и не требует внимания. Поэтому используйте только два состояния: error или off.
Состояние warn нужно только тогда, когда правило добавляется в существующую кодовую базу и должно быть исправлено в будущем, но не сейчас.
Тестирование
Тесты при разработке фронтенда необходимы для обеспечения стабильности и качественной работы приложения. Они автоматизируют проверку функциональности, предотвращают ошибки при изменениях, упрощают рефакторинг и служат документацией для кода, помогая разработчикам уверенно вносить изменения, не боясь нарушить существующую функциональность.
Допустим, у вас есть немного времени на написание тестов на ранней стадии работы над приложением. Что вы должны обязательно протестировать? Как ни странно, обязательным является только модульное тестирование основной части, а остальной код — это уже частные случаи функционирования основной части.
Добивайтесь покрытия данной области на уровне 80 %. Этого достаточно для большинства случаев, когда нужно получить максимальную отдачу от тестирования при минимальных трудозатратах.
Смарт-компоненты, доменные службы и другие частные случаи также можно тестировать в рамках BDD (behavior driven development — разработка через тестирование поведения). Но если вы не разрабатываете библиотеку, их функциональность уже будет проверена в рамках e2e-тестирования (e2e — end-to-end — сквозное тестирование).
Общие сведения
Корневой пакет.json
Хотел бы затронуть два момента, которые могут показаться неочевидными.
- Контроль зависимостей
Если у вас в репозитории планируется только одно приложение, то здесь нет никаких проблем. Все зависимости, установленные в этом файле, являются целевыми.
Но по мере добавления новых приложений в репозиторий, специфичность зависимостей для каждого приложения будет возрастать. Даже без применения подхода «на основе NPM-пакета» ничто не мешает физически разделить эти приложения на отдельные рабочие пространства и установить для них зависимости через npm/yarn/pnpm-workspaces.
Старайтесь указывать зависимости для приложений явно, потому что никто не сможет потом сказать, зачем и для чего используется та или иная зависимость.
- Скрипты для работы
Независимо от количества приложений и архитектуры репозитория, позаботьтесь о шаблоне для новых команд. В начале все просто — есть начальные команды:
- build;
- serve;
- test;
- lint.
Затем добавятся команды для CI, тестового покрытия, сборки с картами исходного кода или для анализа размера сборки, docker и другие команды. Чтобы все это не скапливалось в беспорядке, нужен шаблон для команд npm script command.
Я вывел для себя универсальный шаблон команд, который позволяет писать столько команд, сколько нужно, не теряя контекста:
<scope?><delimiter><type-command><delimiter><modificator>
В этом шаблоне:
- Scope — опциональный префикс, который указывает, к какому приложению (если их больше двух) относится команда (
mf_booking,host_appи т.д.).
- Type-command — целевая исполняемая команда для приложения (
build,test,lintи т. д.).
- Modificator — определитель типа команды, который может представлять дополнительные параметры или условия для выполнения команды, указывая на среду выполнения или особенности запуска (
prod,watch,coverage,ci).
- Delimiter — разделитель, используемый для разделения различных частей команды (
:,-).
Примеры команд:
host_app:build:prod;host_app:lint:fix;mf_booking:test:silent;mf_booking:build:analyze.
Storybook
Storybook уже давно зарекомендовал себя не только как инструмент для демонстрации компонентов из UI-kit. Он позволяет не только визуализировать и тестировать по отдельности большие и малые UI-компоненты, но и способствует улучшению сотрудничества между разработчиками, дизайнерами, бизнес-аналитиками и менеджерами, а также ускоряет процесс разработки.
Storybook позволяет:
- быстро создавать и тестировать компоненты изолированно друг от друга без необходимости создавать пустую страницу в приложении;
- легко создавать документацию по компонентам и проводить реализации сценариев использования;
- проводить визуальное тестирование компонентов (например, используя
storybook-addon-a11yдля тестирования доступности);
- автоматизировать проверку качества кода и компонентов с помощью интеграции Cypress или Jest.
Заключение
Программирование — дело субъективное, предполагающее различные пути достижения цели. Я описал лишь некоторые из этих путей, которые позволяют снизить риски и потенциальные проблемы.
Большинство рассмотренных подходов и решений никоим образом не привязаны к какой-либо конкретной технологии фронтенда, что позволяет использовать их в большинстве сценариев. Но выбор всегда остается за вами.
Читайте также:
- 12 библиотек для прокачки фронтенд-разработки
- Микрофронтенды: 9 шаблонов для каждого разработчика
- Чистая архитектура фронтенда: 7 советов для достижения успеха
Читайте нас в Telegram, VK и Дзен
Перевод статьи Maksim Dolgikh: Frontend development practices that will help you avoid failure





