

Знаете, как дата-сайентисты оценивают производительность моделей машинного обучения? Вводят базовый классификатор — простейший, но эффективный инструмент в сфере науки о данных. Он подобен участнику соревнований, устанавливающему контрольную планку, которую должны поднять более опытные спортсмены — в данном случае более сложные модели.
Определение
Базовый классификатор (dummy classifier) — это простейшая модель машинного обучения, которая делает предсказания, используя основные правила, не обучаясь на входных данных. Она служит эталоном при определении производительности более сложных моделей. Базовый классификатор помогает понять, действительно ли сложные модели изучают полезные закономерности или просто угадывают их.

Набор данных и библиотеки
При написании этой статьи был использован в качестве образца простой искусственный набор данных для игры в гольф (вдохновленный книгой Тома Митчелла «Машинное обучение»). На этом наборе данных модель обучают предсказывать, будет ли человек играть в гольф, основываясь на погодных условиях. Он включает такие характеристики, как ориентировочный прогноз, температура, влажность и ветер, а целевой переменной является то, будет ли человек играть в гольф.
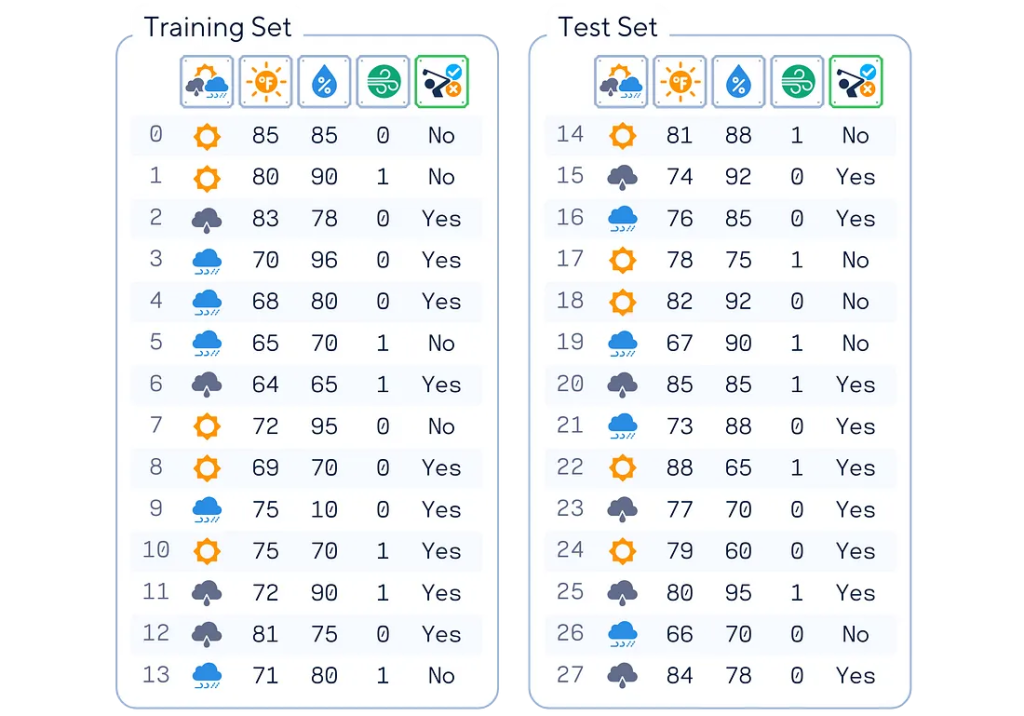
# Импорт библиотек
from sklearn.model_selection import train_test_split
import pandas as pd
# Подготовка набора данных
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain', 'sunny', 'overcast', 'overcast', 'rain', 'sunny', 'overcast', 'rain', 'sunny', 'sunny', 'rain', 'overcast', 'rain', 'sunny', 'overcast', 'sunny', 'overcast', 'rain', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df = pd.DataFrame(dataset_dict)
# Быстрое кодирование столбца Outlook
df = pd.get_dummies(df, columns=['Outlook'], prefix='', prefix_sep='', dtype=int)
# Конвертация столбцов Windy (булево значение) и Play (бинарное) в 0 и 1
df['Wind'] = df['Wind'].astype(int)
df['Play'] = (df['Play'] == 'Yes').astype(int)
# Установка матрицы признаков X и целевого вектора y
X, y = df.drop(columns='Play'), df['Play']
# Разделение данных на обучающий и тестовый наборы
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.5, shuffle=False)
Основной механизм
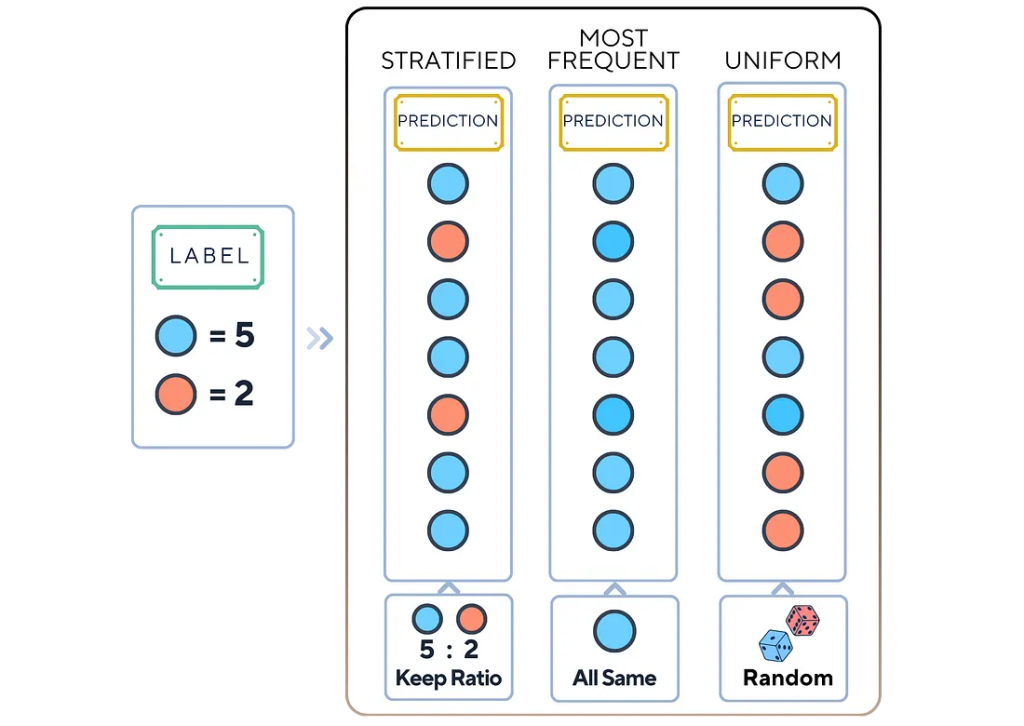
Базовый классификатор оперирует простыми стратегиями прогнозирования. Эти стратегии не предполагают никакого реального обучения на основе данных. Вместо этого они используют такие базовые правила, как:
- Всегда предсказывать наиболее часто встречающийся класс.
- Случайно предсказывать класс на основе распределения классов в обучающем наборе.
- Всегда предсказывать определенный класс.
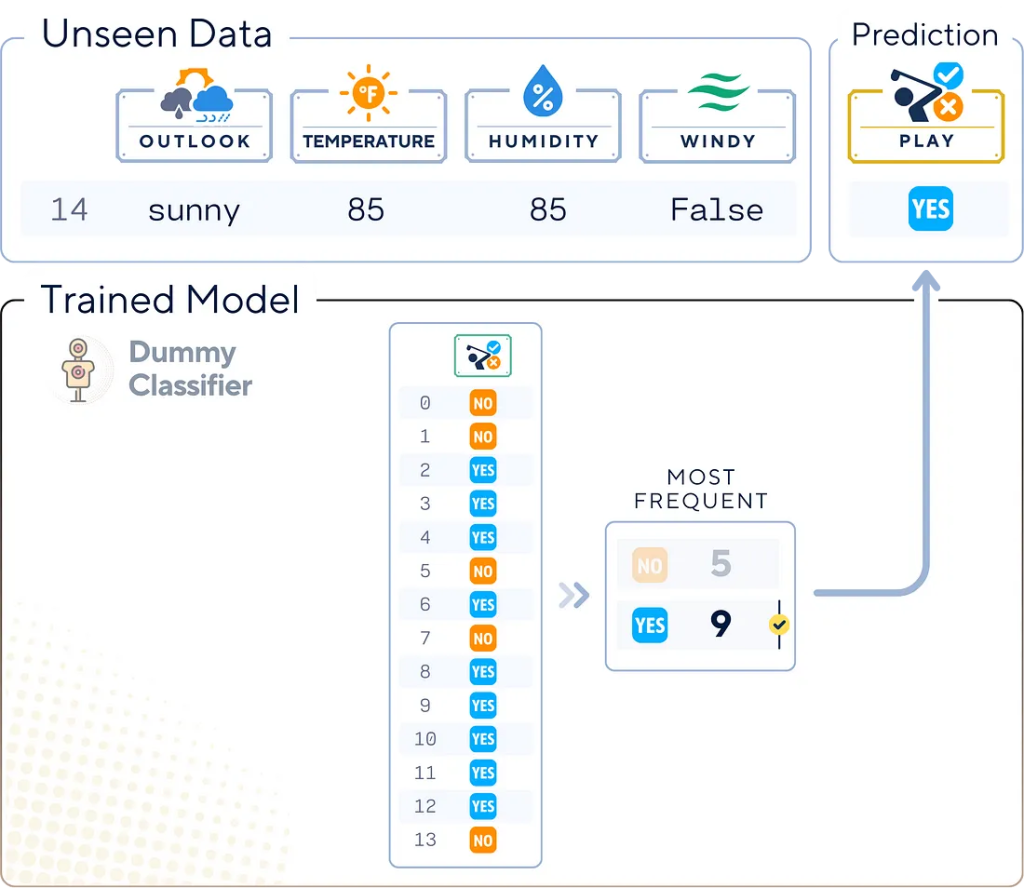
Этапы обучения
Процесс обучения базового классификатора довольно прост: он не включает обычные алгоритмы обучения. Вот общая схема.
1. Выбор стратегии
Выберем одну из следующих стратегий.
- Стратифицированный анализ (Stratified): делать случайные предположения на основе исходного распределения классов.
- Наиболее часто встречающийся класс (Most Frequent): всегда выбирать наиболее часто встречающийся класс.
- Равномерный подход (Uniform): случайно выбирать любой класс.
from sklearn.dummy import DummyClassifier
# Подберите стратегию для вашего DummyClassifier (e.g., 'most_frequent', 'stratified', etc.)
strategy = 'most_frequent'
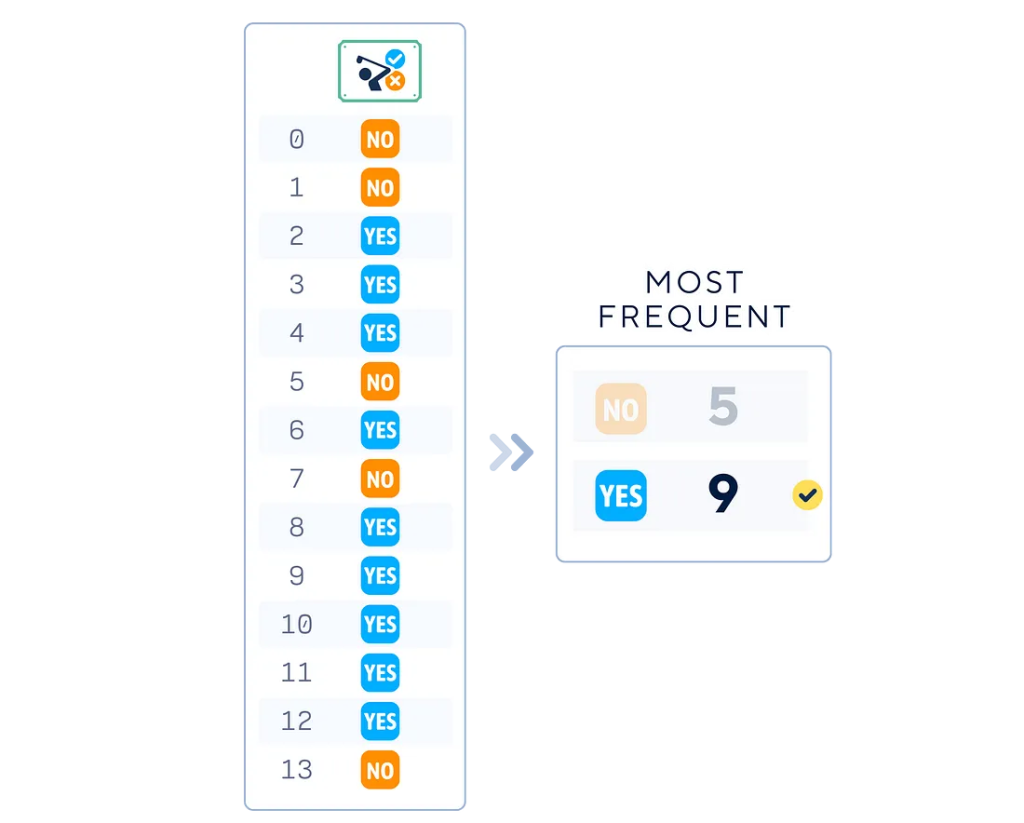
2. Сбор обучающих меток
Соберем метки классов из обучающего набора данных, чтобы определить параметры стратегии.
# Инициализация DummyClassifier
dummy_clf = DummyClassifier(strategy=strategy)
# "Обучение" DummyClassifier (although no real training happens)
dummy_clf.fit(X_train, y_train)
3. Применение стратегии к тестовым данным
Используем выбранную стратегию для создания списка прогнозируемых меток для тестовых данных.

# Используйте DummyClassifier для составления прогнозов
y_pred = dummy_clf.predict(X_test)
print("Label :",list(y_test))
print("Prediction:",list(y_pred))
4. Оценка модели
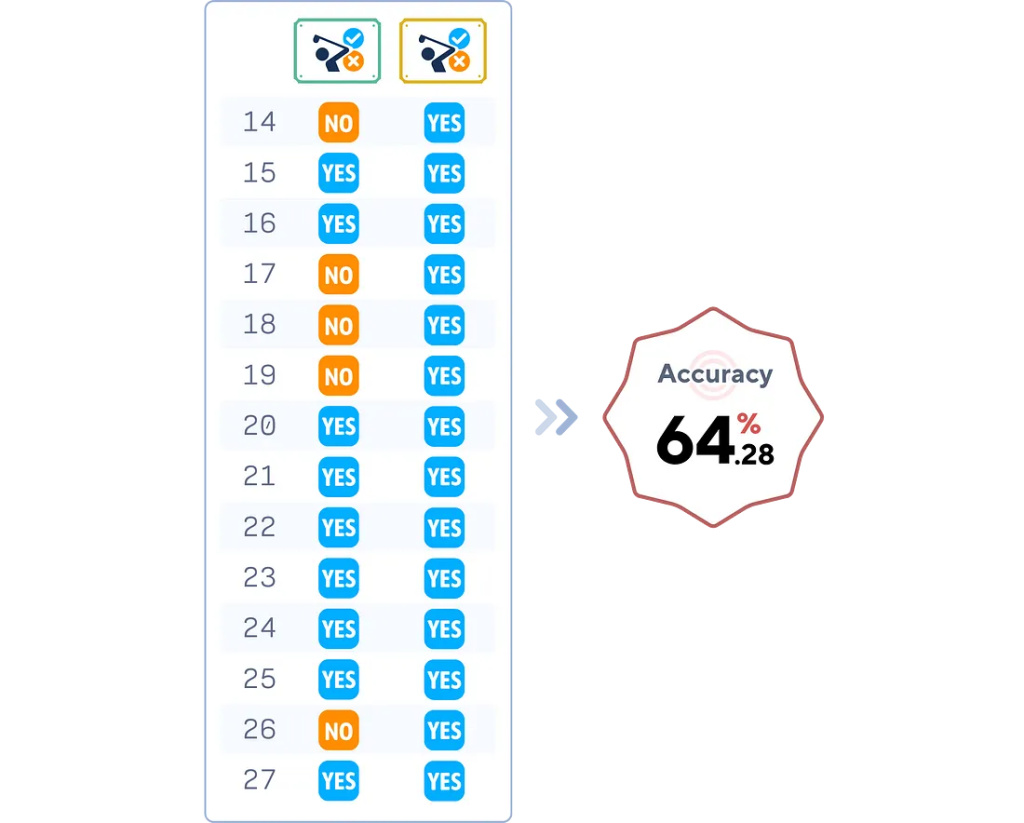
# Оценка точности DummyClassifier
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print(f"Dummy Classifier Accuracy: {accuracy.round(4)*100}%")
Ключевые параметры
У базовых классификаторов, несмотря на их простоту, есть несколько важных параметров.
- Стратегия (Strategy): определяет, как классификатор делает предсказания. Общие параметры включают:
- most_frequent: всегда предсказывает наиболее распространенный класс в обучающем наборе;
- stratified: генерирует предсказания на основе распределения классов в обучающем наборе;
- uniform: генерирует предсказания равномерно случайным образом;
- constant: всегда предсказывает определенный класс.
- Случайное состояние (Random State): при использовании стратегии, предполагающей случайность (например, stratified или uniform), этот параметр обеспечивает воспроизводимость результатов.
- Постоянство (Constant): при использовании стратегии constant этот параметр определяет, какой класс всегда предсказывать.

Плюсы и минусы
Как и у любого инструмента машинного обучения, у базового классификатора есть сильные стороны и ограничения.
Плюсы
- Простота: такую модель легко освоить и внедрить.
- Базовая производительность: обеспечивает уровень производительности, являющийся эталоном для других моделей.
- Проверка переобучения: помогает определить, когда сложные модели переобучаются, сравнивая их производительность с базовым уровнем.
- Экономичность: быстро обучаясь прогнозированию, требует минимальных вычислительных ресурсов.
Минусы
- Ограниченная способность к прогнозированию: базовый классификатор не учится на данных, поэтому его прогнозы часто бывают неточными.
- Отсутствие параметра важности признаков: не дает представления о том, какие признаки наиболее важны для прогнозирования.
- Не подходит для решения сложных задач: в реальных сценариях со сложными закономерностями базовые классификаторы слишком упрощены, чтобы быть полезными сами по себе.
Заключение
Освоение базовых классификаторов имеет решающее значение как для дата-сайентистов, так и для энтузиастов машинного обучения. Эти инструменты служат средством проверки реального положения вещей, помогая специалистам убедиться в том, что их более сложные модели действительно извлекают полезные закономерности из данных. Продвигаясь в машинном обучении, не забывайте проверять эффективность своих моделей, сравнивая их с базовыми классификаторами — не исключено, что вы будете удивлены результатами проверки.
Полный код базового классификатора
# Импорт необходимых библиотек
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.dummy import DummyClassifier
# Подготовка набора данных
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain', 'sunny', 'overcast', 'overcast', 'rain', 'sunny', 'overcast', 'rain', 'sunny', 'sunny', 'rain', 'overcast', 'rain', 'sunny', 'overcast', 'sunny', 'overcast', 'rain', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df = pd.DataFrame(dataset_dict)
# Быстрое кодирование столбца Outlook
df = pd.get_dummies(df, columns=['Outlook'], prefix='', prefix_sep='', dtype=int)
# Конвертация столбцов Wind и Play в бинарные индикаторы
df['Wind'] = df['Wind'].astype(int)
df['Play'] = (df['Play'] == 'Yes').astype(int)
# Разделение данных на признаки (X) и цель (y), затем на обучающий и тестовый наборы
X, y = df.drop(columns='Play'), df['Play']
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.5, shuffle=False)
# Инициализация и обучение модели базового классификатора
dummy_clf = DummyClassifier(strategy='most_frequent')
dummy_clf.fit(X_train, y_train)
# Составление прогнозов на тестовых данных
y_pred = dummy_clf.predict(X_test)
# Расчет и вывод точности модели на тестовых данных
print(f"Accuracy: {accuracy_score(y_test, y_pred)*100:.4f}%")
Читайте также:
- Как обучить модель квантового МО, используя данные из CSV?
- Пошаговое руководство по созданию синтетических данных в Python
- 7 признаков того, что вы стали продвинутым пользователем Sklearn
Читайте нас в Telegram, VK и Дзен
Перевод статьи Samy Baladram: Dummy Classifier Explained: A Visual Guide with Code Examples for Beginners





