
Введение
X обрабатывает около 400 миллиардов событий в режиме реального времени и ежедневно генерирует петабайты данных. Источники событий, из которых X потребляет данные, самые разные — распределенные базы данных, Kafka, шины событий X и т. д.
Для обработки событий у X есть набор внутренних инструментов.
- Scalding — инструмент, который X использует для пакетной обработки.
- Heron, который является собственным потоковым движком X.
- TimeSeriesAggregatoR (TSAR) — инструмент для пакетной обработки и обработки в реальном времени.
Прежде чем углубиться в то, как развивалась система событий X, ознакомимся вкратце с этими внутренними инструментами.
Scalding
Scalding — это Scala-библиотека, позволяющая определять задания Hadoop MapReduce. Scalding создана на основе Cascading — Java-библиотеки, которая абстрагирует низкоуровневые элементы Hadoop. Scalding сопоставима с Pig, но предлагает тесную интеграцию со Scala, что позволяет использовать преимущества Scala при выполнении заданий MapReduce.
Heron
Apache Heron — это собственный потоковый движок X. Его разработка была вызвана необходимостью создания системы для обработки петабайтов данных, повышения производительности разработчиков и упрощения отладки.
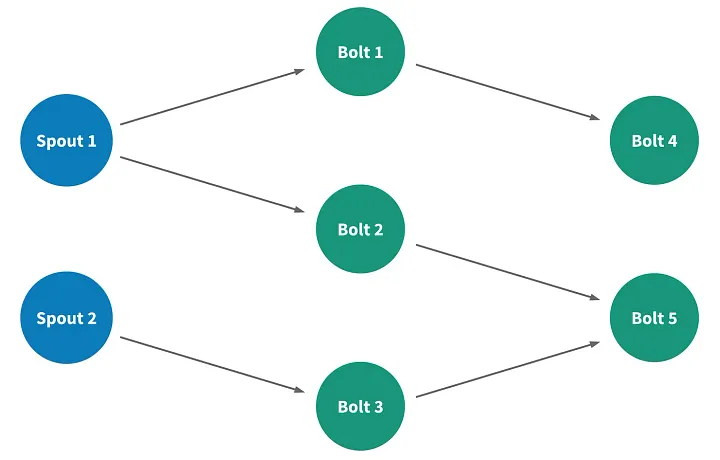
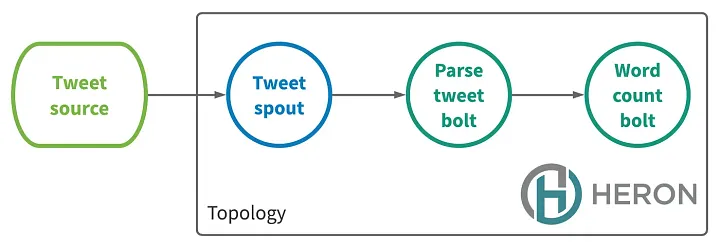
Потоковое приложение в Heron называется топологией. Топология — это направленный ациклический граф, узлы которого представляют собой элементы вычисления данных, а ребра — потоки данных, проходящие между элементами.
Существует 2 типа узлов.
- Spout: подключаются к источнику данных и вводят данные в поток.
- Bolt: обрабатывают входящие данные и выпускают данные.
TimeSeriesAggregator
Команда инженеров данных X столкнулась с необходимостью обрабатывать миллиарды событий ежедневно в пакетном режиме и в реальном времени. TSAR — надежный масштабируемый фреймворк для агрегирования временных рядов в реальном времени. Он создан в первую очередь для мониторинга вовлеченности — агрегирования взаимодействий с твитами, сегментированных по множеству параметров, таких как устройство, тип вовлечения и т. д.
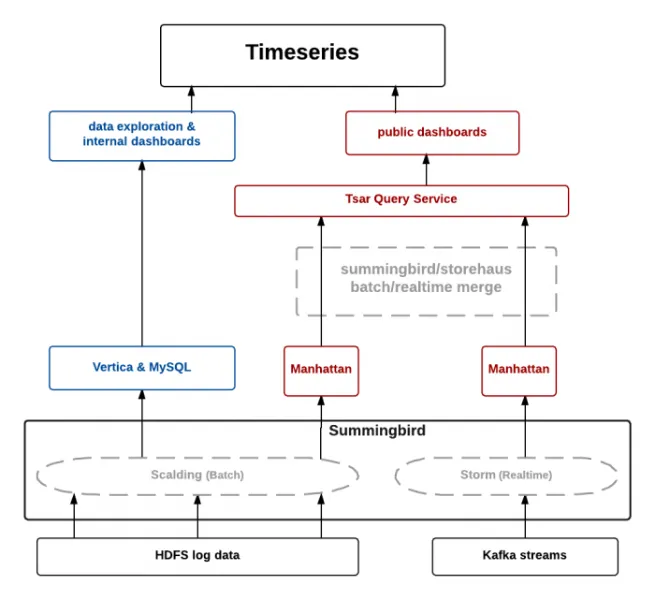
Представим в общих чертах, как работает X. Все функции этой платформы поддерживаются микросервисами, которые включают в себя более 100 тысяч экземпляров, рассредоточенных по всему миру. Они генерируют события, которые отправляются на слой агрегирования событий, созданный на основе проекта с открытым исходным кодом от Meta. Этот слой отвечает за группировку событий, выполняя задания по агрегированию и сохраняя данные в HDFS. Затем события обрабатываются, форматируются и перекомпрессируются для создания эффективно сгенерированных наборов данных.
Прежняя архитектура
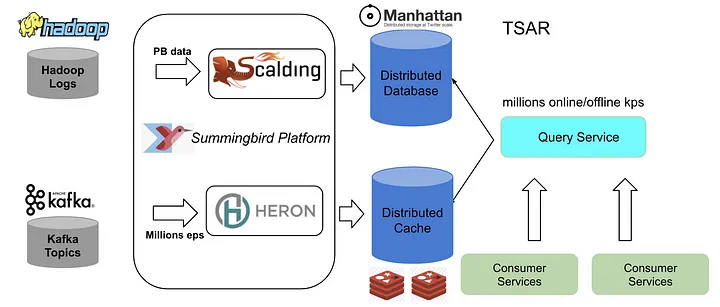
Прежняя архитектура X была основана на Lambda-архитектуре, ключевыми слоями которой были пакетный, потоковый и сервисный. Пакетный компонент — это логи, генерируемые клиентами и хранящиеся в распределенной файловой системе Hadoop (HDFS) после обработки событий. X создал несколько конвейеров масштабирования для предварительной обработки исходных логов и их загрузки на платформу Summingbird в качестве автономных источников. Источниками компонентов реального времени были темы Kafka, которые являлись частью уровня ускорения.
Обработанные пакетные данные хранились в распределенных системах Manhattan, а данные реального времени — в Nighthawk (собственном распределенном кэше X). Системы TSAR, такие как сервис запросов TSAR, который запрашивал как кэш, так и базу данных, являлись частью обслуживающего слоя.
Конвейеры реального времени и сервисы запросов находились в трех дата-центрах. Чтобы снизить затраты на пакетные вычисления, X запускал пакетные конвейеры в одном дата-центре и реплицировал данные в два других дата-центра.
Как вы думаете, почему данные реального времени хранились в кэше, а не в базе данных?
Проблемы, связанные с прежней архитектурой
Попробуем выявить проблемы, которые могут возникнуть в этой архитектуре в отношении событий реального времени.
Предположим, происходит большое событие, например чемпионат мира по футболу. Источник твитов начинает посылать в топологию твитов множество событий. Bolt’ы, выполняющие парсинг твитов, не успевают обрабатывать события, и в топологии возникает противодавление. Когда система находится под противодавлением в течение длительного времени, Bolt’ы в движке Heron могут накапливать spout-лаги, что указывает на высокую задержку в системе. В X заметили, что в таких случаях требуется очень много времени для сокращения лагов в топологии.
Оперативное решение, которое использовала команда, заключалось в перезапуске контейнеров Heron для возобновления потоковой обработки. Это могло привести к потере событий во время работы, что было чревато неточностями в агрегированных подсчетах в кэше.
Теперь рассмотрим пример с пакетными событиями. В X есть несколько конвейеров со сложными вычислениями, обрабатывающих петабайты данных и выполняющих их почасовую синхронизацию в базе данных Manhattan. Представим ситуацию, когда синхронизация занимает более часа, а запуск следующего задания уже запланирован. Это может привести к возрастанию противодавления в системе и потере данных.
Сервис запросов TSAR, как видим, объединяет в себе и службу Manhattan, и службу кэширования для предоставления данных клиентам. Из-за потенциальной потери данных в реальном времени сервис TSAR может предоставлять клиентам неточные метрики.
Нетрудно выявить последствия этих проблем для клиентов и бизнеса, которые заставили X разработать новую архитектуру:
- Рекламные сервисы X — одна из основных моделей доходов X, и снижение их производительности напрямую влияет на бизнес-модель.
- X предлагает различные услуги по обработке данных для получения информации о показателях впечатлений и вовлеченности. Неточность данных может повлиять на качество этих услуг.
- Время от создания события до его доступности для использования может занять несколько часов из-за пакетной обработки данных. Это означает, что аналитика данных или любые другие операции, которые необходимо выполнять клиентам, не будут опираться на актуальные данные. Временная задержка может составлять несколько часов.
Таким образом, до завершения пакетной обработки клиент не сможет ни обновить временную шкалу пользователей на основе сгенерированных ими событий, ни провести поведенческий анализ пользователей на основе их взаимодействия с системами X.
Новая архитектура
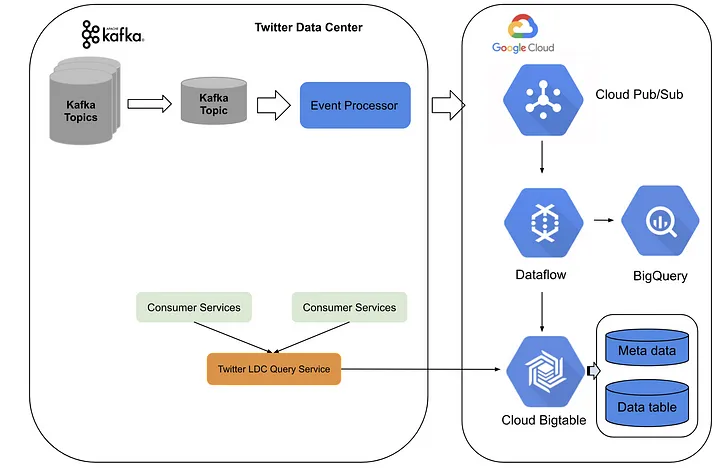
Новая архитектура была создана на базе сервисов как дата-центра X, так и платформы Google Cloud. X создал конвейер обработки событий, преобразующий темы Kafka в Pub-подтемы, которые отправляются в Google Cloud. Там, в DataFlow, задания по потоковой обработке выполняют агрегирование данных в режиме реального времени, после чего данные сбрасываются в BigTable.
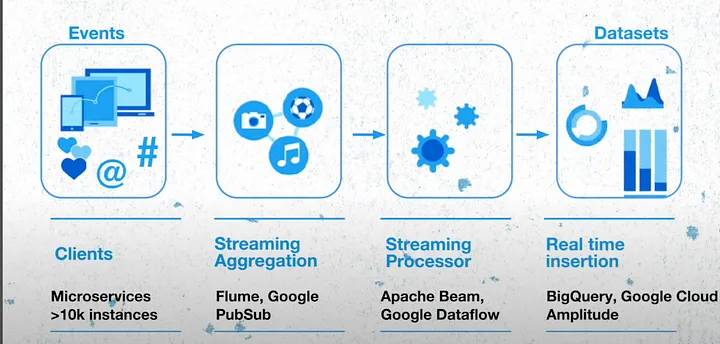
В качестве обслуживающего слоя X использует сервис запросов LDC с фронтендом в дата-центрах X и бэкендом в BigTable и BigQuery. Вся система может передавать до миллионов событий в секунду с низкой задержкой до ~10 мс и легко масштабируется при высоком трафике.
Новая архитектура позволяет сократить расходы на создание конвейеров пакетной обработки, а конвейерам реального времени обеспечивает более высокую точность агрегирования и стабильно низкую задержку. Кроме того, X избавился от необходимости поддерживать агрегирование событий в реальном времени в нескольких дата-центрах.
Сравнение производительности
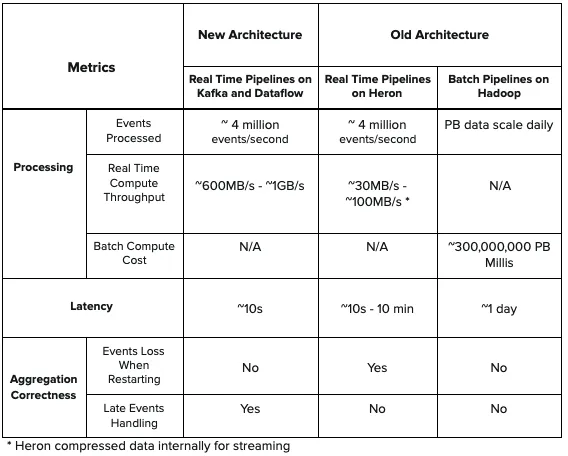
Новая архитектура обеспечивает меньшую задержку по сравнению с топологией Heron в прежней архитектуре и более высокую пропускную способность. Кроме того, новая архитектура гарантирует подсчет последних событий и не допускает потерь событий при агрегировании в реальном времени. Помимо этого, в новой архитектуре отсутствует пакетный компонент, что упрощает проектирование и снижает затраты на вычисления, которые существовали в прежней архитектуре.
Заключение
Благодаря переходу от прежней архитектуры, созданной на TSAR, к гибридной архитектуре на базе дата-центра X и платформы Google Cloud, X может обрабатывать миллиарды событий в реальном времени и достигать низкой задержки, высокой точности, стабильности, простоты архитектуры и снижения эксплуатационных расходов для инженеров.
Читайте также:
- Как создать платформу обработки и анализа данных за неделю
- 4 важных навыка, которые специалисты по обработке данных часто недооценивают
- 4 пакета Python для причинно-следственного анализа данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи Mayank Sharma: How Twitter improved the processing of 400 billion events




