
В последнее время в социальных сетях активно обсуждались контракты о передаче данных. Некоторые дата-саентисты делились мнениями о плюсах и минусах этого новшества и о том, что это вообще такое.
Это малоизученная тема, но я хотел бы поделиться своим опытом и конструктивными советами о том, как начать работу в этом направлении. Контракты о передаче данных — это нечто реальное и ценное, что можно использовать уже сегодня, прилагая меньше усилий, чем кажется.
Что особенного в контрактах о передаче данных
Если вы работаете с данными, скорее всего, вам не раз придется столкнуться с такой ситуацией: данные неверны, и вы не можете установить причину. Кажется, что на начальном этапе сбора данных есть проблема, но никто из коллег не знает, почему она возникла. Что же делать и к кому обратиться?
Поскольку качество предоставляемых данных не всегда безупречно, команды дата-саентистов начинают анализировать существующую инфраструктуру, которая служит другим первоначальным целям. Они “подключают” конвейеры к актуальной оперативной базе данных, выгружают данные в хранилище и выполняют дальнейшие действия.
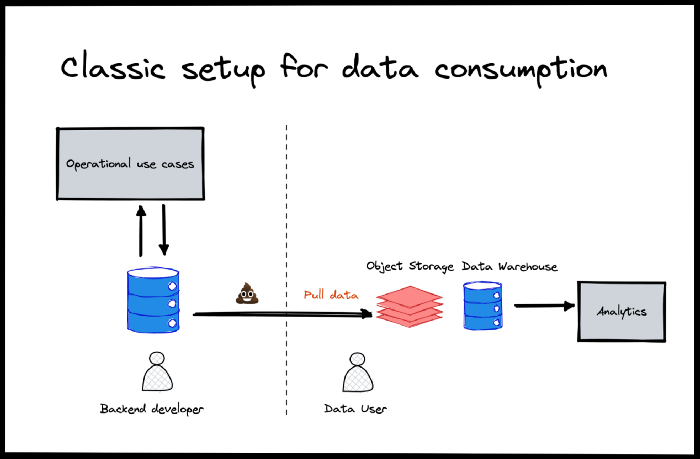
Команды по работе с данными оказываются между двух огней — оперативными базами данных, которые они не могут контролировать, и жестко поставленными бизнес-целями.
Немного “поколдовав”, дата-саентисты пытаются что-то исправить, но принцип “мусор на входе — мусор и на выходе” действует безотказно. Чем больше проблем во входящем потоке данных, тем сложнее командам по работе с ним.
Именно в такой ситуации может прийти на помощь контракт о передаче данных. Он позволяет команде дата-саентистов четко сформулировать свои условия и договориться о более строгом процессе управления изменениями.
Как реализуются такие контракты
Поначалу это кажется нереальным, поскольку редко есть возможность начать работу с инфраструктуры, созданной с нуля. Однако с сегодняшними облачными технологиями это выполнимо.
Событийно-ориентированная архитектура способна оказать поддержку контрактам о передаче данных по нескольким причинам.
- События могут быть сильно типизированы, и каждое из них может быть связано с версией схемы.
- Это дешево, если вы используете бессерверный поток событий, а инфраструктура — автономна (в каждом отдельном случае).
- Платформы событий (они же pub/sub) предлагают встроенные коннекторы для потребления классических нисходящих данных (хранилище объектов, хранилище данных).
Такие технологии, как AWS Kinesis и Kafka (с управляемым Kafka, например, AWS MSK и Confluent), Cloud Pub/Sub — хорошие варианты для начала работы.
Идея заключается в том, чтобы создать качественно новый контракт с бэкенд-разработчиками, основанный на важнейших целях потребителей (данных).
Бэкенд-специалисты часто располагают опытом работы с шаблонами, управляемыми событиями, не затрагивающим аналитику. Например, взаимодействие между микросервисами. Здесь возможны два варианта.
- Достичь компромисса в отношении схемы, чтобы она подходила как для аналитики данных, так и для конкретного сценария использования.
- Создать событие, предназначенное для использования в области аналитики данных.
Выбор варианта 1 позволит избежать взрывного роста типа событий, создаваемых у источника, но, возможно, усложнит ход обсуждения изменений, поскольку в процесс будет вовлечено больше заинтересованных сторон.
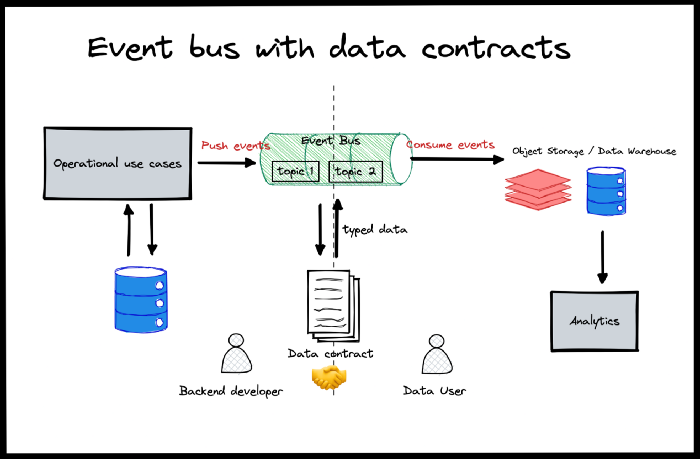
Определение создания/изменения контракта
Большинство платформ потоковой обработки событий, таких как Kafka и AWS MSK, имеют свой реестр схем (реестр AWS Glue в случае AWS). Для каждой создаваемой темы необходимо регистрировать схему.
Простым способом реализации такого процесса между производителем и потребителем данных является повторное использование процесса git.
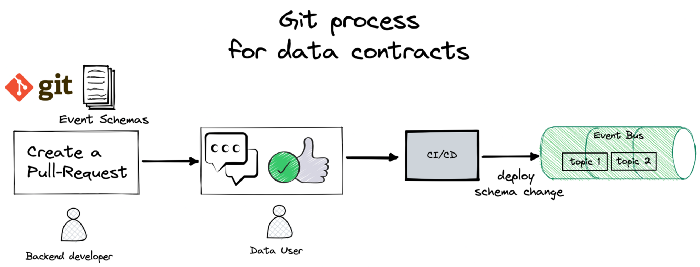
Весь процесс создания, изменения и удаления схемы может проходить через пул-реквест git. Имея четкое представление о собственнике и потребителе темы, вы всегда будете знать, кто может утверждать изменения в схеме. При слиянии конвейер CI/CD подхватывает и развертывает изменение с соответствующей схемой.
Прелесть такого процесса в том, что он обязывает обсуждать изменения до их внесения.
Производственный чек-лист
Вот несколько моментов, которые можно порекомендовать при реализации контрактов о передаче данных с шиной событий.
Используйте типизированную схему
Поддерживать схему JSON довольно проблематично. Слишком много свободы действий. Общим стандартом для типизированных событий является использование Avro. Он поддерживается всеми реестрами схем и имеет много возможностей взаимодействия с другими механизмами обработки (Flink, Spark и т. д.) для дальнейшего преобразования.
Не зацикливайтесь на вложенных полях
Поскольку мы обычно анализируем данные в столбцовом формате, наличие слишком большого количества вложенных сложных полей может быть проблемой для развития схемы, которая еще и скажется на стоимости обработки. Если у вас много вложенных полей, подумайте о разделении события на несколько с определенными схемами.
Иногда допускайте компромисс в отношении вложенных полей
Если производитель не уверен в определении всех схем (например, они зависят от API сторонних производителей), можно оставить остальную часть unknown в виде строки JSON. Это потребует больше затрат на вычисления для получения доступа к такому полю, но оставит больше возможностей для гибкости на стороне производителя данных.
Настройте дополнительные поля метаданных в событии
Такие элементы, как owner, domain, team_channel и идентификация столбцов PII определенными полями, будут полезны в дальнейшем для четкого определения прав собственности, адресной области и управления доступом.
Schemata — полезный ресурс, в котором также можно черпать вдохновение для моделирования схем событий.
Не меняйте тип данных для указанного поля
Лучше переименовать поле в новый тип. Хотя можно воспользоваться механизмом для обнаружения версии схемы в нисходящем потоке данных, разрешение изменения типа поля без его переименования всегда будет вызывать головную боль. Выполнив это в одном случае, вы будете вынуждены обрабатывать все остальные. Так, если изменение int нa string не причинит проблем, то что произойдет, если изменить int на float или float на int?
Реализуйте контракты о передаче данных без шины событий при возможности
Если есть место в git, где хранятся все DDL-запросы для оперативной базы данных, можно реализовать большинство из вышеперечисленного. Например, при любом изменении, внесенном в базу данных, git-процесс будет извещать потребителя, которому необходимо утвердить изменение. Однако это достаточно сложно, поскольку вы заключали контракт о передаче уже существующих данных, и у команды дата-саентистов не было возможности высказаться при создании схемы.
Право собственности — производителю данных
Контракты о передаче данных — это возможность отдать право собственности производителям данных, а не заставлять команды дата-саентистов страдать от непроверенных данных, которые им предоставляют. Это позволяет устранить изолированность продуктов и данных.
Самая большая проблема — организационная. Команды по работе с данными должны преодолеть барьер и обсуждать новые процессы с бэкенд-разработчиками, а это не всем дается легко. Выделение текущих болевых точек и обеспечение видимости того, как потребляются данные, — действенные стимулы для такого обсуждения.
Что касается инструментария, то все можно настроить постепенно, используя сервис pub/sub платформы событий, реестр схем и git в процессе заключения контрактов о передаче данных.
Нет необходимости сразу приступать к глобальной реорганизации — начните с малого и постепенно двигайтесь по пути освоения нового паттерна!
Читайте также:
- Ludwig на PyTorch
- Собеседование в области науки о данных: 7 распространенных ошибок
- Моделирование данных в мире современного стека данных 2.0
Читайте нас в Telegram, VK и Дзен
Перевод статьи mehdio: Data Contracts — From Zero To Hero





