
Начиная заниматься машинным обучением, я следовал рекомендациям и создавал собственные характеристики, комбинируя несколько столбцов в наборе данных. И делал я это ужасно неэффективно, теряя по несколько минут на самые простые операции.
Проблема была проста: я не знал, как эффективно выполнять итерации по строкам в Pandas.
В интернете встречается немало людей, поступающих так же. Используемые ими методы не элегантны, но вполне подходят для небольших объемов данных. Однако при необходимости обработать более 10 тысяч строк сразу ухудшается производительность.
Поэтому я решил поделиться более эффективным способом итерации по строкам в Pandas DataFrame, не требующим дополнительного кода. Он позволит не только повысить производительность, но и разобраться в происходящем “за кадром” — это навык, который отличает успешных исследователей данных.
Итак, импортируем набор данных в Pandas. В данном случае я выбрал тот, над которым работал ранее — пришло время исправлять ошибки прошлого!
import pandas as pd
import numpy as np
df = pd.read_csv('https://raw.githubusercontent.com/mlabonne/how-to-data-science/main/data/nslkdd_test.txt')
dfЭтот набор данных содержит 22 тысячи строк и 43 столбца с комбинацией категориальных и числовых значений. Каждая строка описывает соединение между двумя компьютерами.
Допустим, нам необходимо создать новую характеристику — общее количество байт в соединении. Для этого нужно просто просуммировать две существующие характеристики: src_bytes и dst_bytes. Рассмотрим различные методы вычисления этой новой характеристики.
1. Iterrows
Согласно официальной документации, iterrows() выполняет итерацию “по строкам Pandas DataFrame в виде пар (index, Series)”. Эта функция преобразует каждую строку в объект Series, что вызывает две проблемы.
- Может изменится тип данных (
dtypes). - Преобразование значительно снижает производительность.
По этим причинам функция iterrows(), и без того имеющая плохую репутацию, является худшим методом для фактической итерации по строкам.
%%timeit -n 10
# Iterrows
total = []
for index, row in df.iterrows():
total.append(row['src_bytes'] + row['dst_bytes'])10 циклов, лучший результат из 5 — 1,07 с на цикл.
Теперь обратимся к более продвинутым методам.
2. For loop с .loc или .iloc (в 3 раза быстрее)
Раньше я использовал базовый for loop для выбора строк по индексу (с .loc или .iloc). Почему это плохо? Потому что DataFrame не предназначен для этой цели. Как и в предыдущем методе, строки преобразуются в объекты Pandas Series, что снижает производительность. Стоит отметить, что .iloc быстрее, чем .loc. Это имеет значение, поскольку Python не нужно проверять пользовательские метки и напрямую отслеживать, где в памяти хранится строка.
%%timeit -n 10
# For loop с .loc
total = []
for index in range(len(df)):
total.append(df['src_bytes'].loc[index] + df['dst_bytes'].loc[index])10 циклов, лучший результат из 5 — 600 мс на цикл.
%%timeit -n 10
# For loop с .iloc
total = []
for index in range(len(df)):
total.append(df['src_bytes'].iloc[index] + df['dst_bytes'].iloc[index])10 циклов, лучший результат из 5 — 377 мс на цикл.
Даже базовый for loop с .iloc в 3 раза быстрее, чем первый метод!
3. Apply (в 4 раза быстрее)
Метод apply() — еще один популярный способ итерации по строкам. Он создает код, который легко понять, но за это приходится платить: производительность почти такая же плохая, как у предыдущего for loop.
Поэтому настоятельно советую избегать этой функции для данной цели (для других она вполне подойдет).
Обратите внимание, что при преобразовании DataFrame в список с помощью метода to_list() получаются идентичные результаты.
%%timeit -n 10
# Apply
df.apply(lambda row: row['src_bytes'] + row['dst_bytes'], axis=1).to_list()10 циклов, лучший результат из 5 — 282 мс на цикл.
Метод apply() — это замаскированный for loop. Поэтому производительность повышается не так заметно: он всего в 4 раза быстрее, чем первый метод.
4. Itertuples (в 10 раз быстрее)
Если вы знакомы с функцией iterrows(), то наверняка знаете и о itertuples(). Согласно официальной документации, она выполняет итерацию “по строкам DataFrame в виде именованных кортежей значений”. На практике это означает, что строки преобразуются в кортежи, которые являются гораздо более легкими объектами, чем Pandas Series.
Вот почему itertuples() является улучшенной версией iterrows(). Единственная проблема заключается в том, что нужно выбирать столбцы на основе их индекса, что делает этот прием менее удобным, чем предыдущие.
%%timeit -n 10
# Itertuples
total = []
for row in df.itertuples():
total.append(row[5] + row[6])10 циклов, лучший результат из 5 — 99,3 мс на цикл.
Итак, этот метод в 10 раз быстрее, чем iterrows(), что означает определенный прогресс.
5. Генерация списка (в 200 раз быстрее)
Генерация списка — это элегантный способ итерации по списку в виде одной строки. Например, [print(i) for i in range(10)] выводит числа от 0 до 9 без явного использования for loop. Я говорю “явного”, потому что Python на самом деле обрабатывает эти данные подобно for loop, о чем можно судить по байткоду. Так почему же этот метод быстрее? Просто потому, что в этом случае не вызывается метод .append().
%%timeit -n 100
# Генерация списка
[src + dst for src, dst in zip(df['src_bytes'], df['dst_bytes'])]100 циклов, лучший результат из 5 — 5,54 мс на цикл.
Действительно, этот метод в 200 раз быстрее, чем первый! Но мы все еще можем добиться большего.
6. Векторизация Pandas (в 1500 раз быстрее)
Все использованные выше техники просто суммировали отдельные значения. Почему бы вместо сложения отдельных значений не сгруппировать их в векторы, чтобы потом суммировать? Разница между сложением двух чисел или двух векторов не велика для центрального процессора, что должно ускорить работу.
Кроме того, Pandas может обрабатывать объекты Series параллельно, используя все доступные ядра процессора!
Синтаксис также является самым простым из всех возможных: это решение чрезвычайно интуитивно понятно. “За кадром” Pandas позаботится о векторизации данных с помощью оптимизированного кода языка C, используя блоки непрерывной области памяти.
%%timeit -n 1000
# Векторизация
(df['src_bytes'] + df['dst_bytes']).to_list()Этот код в 1500 раз быстрее, чем iterrows(), и его даже проще написать.
7. Векторизация NumPy (в 1900 раз быстрее)
Библиотека NumPy предназначена для обработки научных вычислений. Она требует меньше затрат, чем методы Pandas, поскольку строки и датафреймы приобретают вид np.array. При этом она опирается на те же оптимизации, что и векторизация Pandas.
Существует два способа преобразования Series в np.array: с помощью .values и .to_numpy(). Поскольку первый уже давно устарел, в данном примере будем использовать .to_numpy().
%%timeit -n 1000
# Векторизация Numpy
(df['src_bytes'].to_numpy() + df['dst_bytes'].to_numpy()).tolist()1000 циклов, лучший результат из 5 — 575 µс на цикл.
Метод-победитель найден: он в 1900 раз быстрее, чем первый! Пришло время подвести итоги.
Заключение
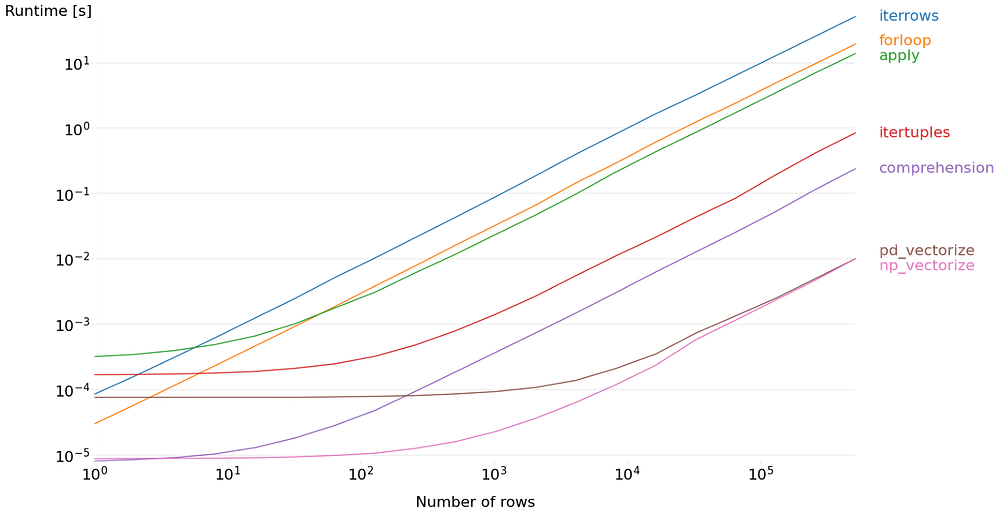
Если нужно итерировать строки в DataFrame, то используйте векторизацию! Код для экспериментирования можно найти здесь. Векторизация легко читается, быстро пишется и невероятно повышает производительность.
Понимая, как каждый метод работает “за кадром”, можно значительно оптимизировать код. Эффективность обработки данных достигается одним и тем же способом — преобразованием данных в векторы и матрицы, что позволяет использовать преимущества параллельной обработки. Увы, часто это происходит в ущерб читабельности кода. Хотя и не всегда.
Читайте также:
- Четыре метода, которые повысят качество работы с Pandas
- Внимание: работает пакет Python Tweepy!
- Лучшие языки программирования для изучения
Читайте нас в Telegram, VK и Дзен
Перевод статьи Maxime Labonne: Efficiently iterating over rows in a Pandas DataFrame





