
Что такое YOLO? Эта аббревиатура расшифровывается как “You Only Look Once” (“Стоит только раз взглянуть”). YOLO — современный алгоритм глубокого обучения, который широко используется для обнаружения объектов. Он был разработан Джозефом Редмоном и Али Фархади в 2016 году.
Чем YOLO отличается от других алгоритмов глубокого обучения для обнаружения объектов?
Основное отличие YOLO от других алгоритмов сверточной нейронной сети (CNN), используемых для обнаружения объектов, заключается в том, что он очень быстро опознает объекты в режиме реального времени. Принцип работы YOLO подразумевает ввод сразу всего изображения, которое проходит через сверточную нейронную сеть только один раз. Именно поэтому он называется “Стоит только раз взглянуть”. В других алгоритмах этот процесс происходит многократно, то есть изображение проходит через CNN снова и снова. Так что YOLO обладает преимуществом высокоскоростного обнаружения объектов, чем не могут похвастать другие алгоритмы.
Представьте себе автомобиль, оснащенный функцией самостоятельного вождения, который использует обычный алгоритм обнаружения объектов сети CNN. Если алгоритм заметит впереди препятствие, машина затормозит сама. Но в данном случае все будет происходить медленно, и алгоритм увидит объект-препятствие довольно поздно. Это может привести к аварии. Теперь представьте себе ту же ситуацию с YOLO. На этот раз автомобиль оснащен алгоритмом YOLO и остановится как раз вовремя, так как очень быстро обнаружит препятствие в режиме реального времени.
Как работает YOLO?
Алгоритм YOLO был обучен на определенном типе набора данных, который состоит из 80 различных типов классов (см. ниже):
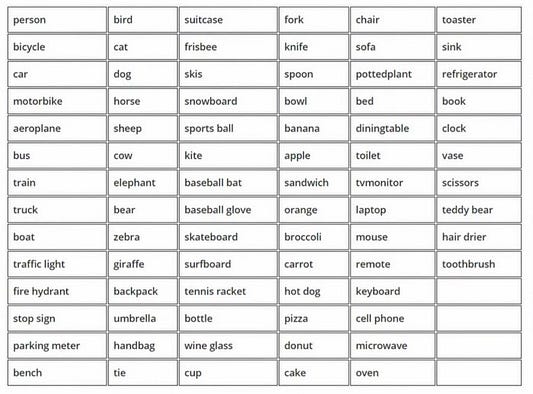
Алгоритм YOLO способен обнаруживать все эти 80 видов объектов на изображении. Он также может быть специально обучен, чтобы легко находить новые объекты. Набор данных, который использовался для обучения обнаружения 80 классов объектов, известен под названием “Coco”.
Мы расскажем о работе алгоритма YOLO очень кратко и просто, так как эта статья предназначена для новичков!
Сначала изображение, которое вводится в сеть, разделяется на секции. Возьмем для примера матрицу-сетку 3×3.

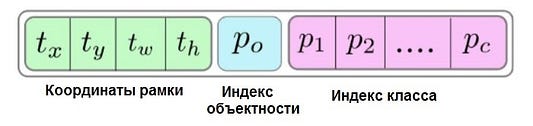
Итак, этому изображению был дан формат матрицы размером 3×3. На данном фото в общей сложности 9 секций. Каждая из них имеет определенные параметры. Если мы допустим, что общее количество классов, которые мы ищем на рисунке, равно 3 (предположительно это будут человек, автомобиль и самолет), то каждая секция будет иметь в общей сложности 8 параметров. Но почему именно 8? Потому что каждая секция содержит 5 параметров и три параметра класса. Эти 5 параметров перечислены ниже:
Чтобы комментировать эти параметры, нам нужно знать, что такое ограничивающие рамки. При подготовке обучающих данных мы должны выделить объект, который хотим обнаружить на изображении. Делаем мы это с помощью ограничивающих рамок. Как правило, они представляют собой квадраты или прямоугольники, которые выделяют определенную часть изображения (как на примере ниже):

В данном случае нам нужно обнаружить автомобили, поэтому мы помещаем ограничивающие рамки вокруг всех автомобилей, присутствующих на нем. Теперь нам необходимо узнать значения 5 параметров в каждой секции в матрице 3×3. Ниже представлена фотография отдельной секции, в которой есть автомобиль.

Красная точка в середине обозначает центр ограничивающей рамки. Горизонтальная синяя стрелка — это параметр “tx” (расстояние между красной точкой и самой левой частью этой секции). Вертикальная синяя стрелка — это “ty” (расстояние между красной точкой и самой верхней частью секции). Горизонтальная белая стрелка — это ширина ограничительной рамки по отношению к секции (параметр “tw”). Вертикальная белая стрелка обозначает высоту ограничивающей рамки по отношению к секции и указывается как “th”.
Параметр “po”, также известный как индекс объектности, выражает вероятность успешного обнаружения объекта в ограничивающей рамке. И да, вы угадали, значение 0,99 на первой картинке этой статьи— индекс объектности, указывающий на наличие лица в ограничивающей рамке, которая его окружает. Индексы “p1”, “p2” и “p3” говорят нам о вероятности того, что этот объект окажется человеком, автомобилем или самолетом соответственно. Все 9 секций, присутствующих в матрице 3×3, имеют эти 8 параметров, и именно они помогают алгоритму YOLO точно обнаружить объект.
Заключение
Работа алгоритма YOLO по корректному обнаружению объектов не обходится без некоторых сложностей. Здесь мы просто хотели дать вам краткое представление о его функционировании простым языком.
Читайте также:
- Как инструменты дизайна интерфейса и визуализации способствуют развитию Machine Teaching?
- 29 сниппетов Pytorch для ускорения цикла машинного обучения
- 5 причин смещения в машинном обучении и что с этим делать
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Kartikeya Rawat: Yolo Algorithm (The Layman’s Approach)





