
Любая современная компания, достигнув определенного момента в своем развитии, сталкивается с непростой задачей: сделать свою продукцию более кастомизируемой для клиентов. Стремление к персонализации товаров или услуг вынуждает организацию определять индивидуальный выбор покупателей, исследовать их отзывы и поведение, то есть создавать уникальный профиль для каждого клиента.
С чего начинается процесс персонализации?
Как правило, компания начинает персонализацию по разным вертикалям системы, в зависимости от сферы бизнеса. Возьмем для примера такую популярную отрасль, как электронная коммерция. Здесь процесс кастомизации начинается со следующих шагов:
- персонализация предложений для клиентов;
- выявление мошеннических транзакций, совершаемых через учетную запись пользователя;
- анализ отзывов и составление общего мнения о компании в социальных сетях;
- оценка популярности продуктов из каталога и т.д.
Сегодня мы расскажем вам о том, какие действия должна предпринять ваша команда специалистов, чтобы реализовать на практике модель персонализации.
Настройка стандартной ML-системы для существующего приложения
Для того, чтобы решить большинство вышеперечисленных бизнес-задач, вам необходимо внедрить ту или иную модель ML из тех, которые доступны сейчас на рынке. Это может быть предварительно обученная или новая модель, которую вы хотите обучить сами с помощью существующего набора данных. Если ваша команда планирует внедрить ML в свою систему, она должна выполнить 5–6 шагов, указанных ниже.
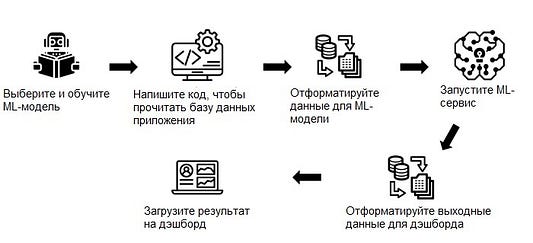
Необходимость выбора и обучения ML-модели зависит от типа постановки проблемы, которую вы хотите решить. Эти два шага не всегда будут обязательными. Но остальные этапы вам всегда придется проходить для настройки любого ML-сервиса в вашем приложении.
Задействование машинного обучения ставит перед компанией ряд задач и проблем (и это еще не полный их список):
- увеличение ресурсов для интеграции и/или обучения модели ML в соответствии с требованиями организации;
- создание дополнительной логики приложения для идентификации и изменения данных в соответствии с требованиями модели ML;
- необходимость переработки выходных данных для публикации результата на дашборде;
- дополнительные циклы спринтов и затраты на обслуживание из-за создания конвейеров обработки данных;
- отсутствие возможности быстрого запуска проекта.
Что может предложить Amazon Aurora ML?
Для предотвращения этих трудностей на базе AWS был запущен сервис Aurora ML. Он позволяет компаниям упростить процесс внедрения сервисов ML поверх существующей базы данных Aurora на основе SQL.
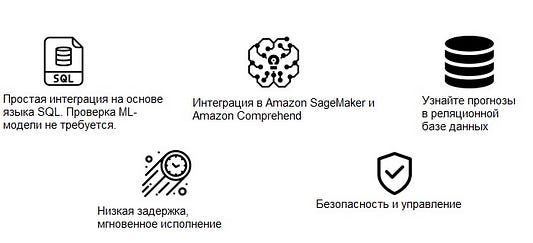
Вы можете объединить ML-сервис и базу данных Aurora, а также запускать сервис с помощью простых запросов на основе языка SQL. Так что вашему персоналу не придется повышать квалификацию для того, чтобы осуществить такую интеграцию.
В настоящее время Aurora ML от Amazon совместима с Amazon SageMaker и Amazon Comprehend, что позволяет легко интегрировать и использовать несколько предварительно обученных сервисов ML, предлагаемых AWS.
Таким образом, вы сможете получать прогнозы в упрощенном формате непосредственно в вашей реляционной базе данных.
Запущенные ML-сервисы инициируют процесс интеграции с пакетами данных в строках базы данных. Поскольку Aurora напрямую объединяется с различными сервисами ML, она предоставляет результаты с минимальной задержкой, выдавая прогнозы практически моментально.
Здесь стоит упомянуть одно из ключевых преимуществ Aurora. Вне всякого сомнения, безопасность данных — приоритетная задача для любой компании. При показанной настройке не наблюдается постоянного состояния ваших данных, созданных вне существующей базы данных Aurora. Сервисы ML интегрируются с базой данных Aurora с помощью ролей IAM.
Настройка Aurora ML от Amazon
С помощью Aurora ML от Amazon описанный выше сложный шестиэтапный процесс можно свести к простым трем шагам.

Выбирать и обучать ML-модель, как упоминалось ранее, в этом случае необязательно. Если вам требуется провести анализ тональности текста, вы можете воспользоваться Amazon Comprehend и обойти таким образом первый шаг.
Второй этап включает в себя вызов ML-сервисов. Для этого вам нужно прибегнуть к помощи простых SQL-функций, после чего вы получите необходимые результаты в простом реляционном формате, который может быть непосредственно интегрирован с вашим дашбордом.
Настройка Aurora ML для вашей системы
Давайте рассмотрим этапы настройки Aurora ML для вашей платформы. Мы покажем вам пример интеграции Amazon Aurora ML с Amazon Comprehend. Ниже представлены иллюстрации такой настройки.
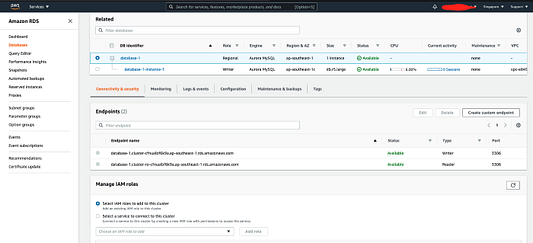
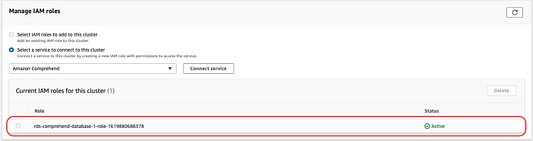
Перейдите в раздел “Управление ролями IAM” и выберите сервис для подключения к этому кластеру. В выпадающем списке выберите Amazon Comprehend и нажмите “Подключить сервис”.
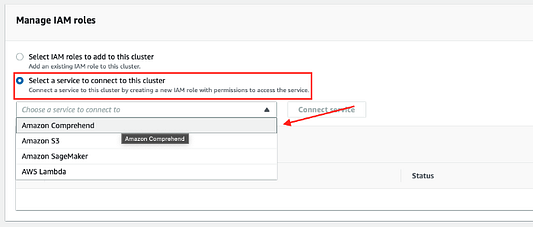
AWS создаст роль IAM для базы данных Amazon Aurora для обеспечения возможности подключения к Amazon Comprehend.
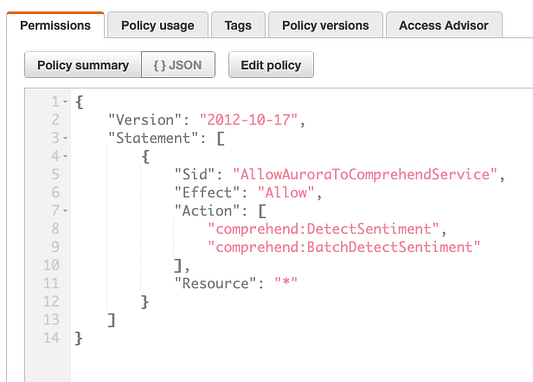
Взглянув на приведенный выше скриншот с отображением политики IAM по отношению к ролям IAM, вы можете видеть, что у сервиса есть разрешение на доступ только к comprehend DetectSentiment и DetectBatchSentiment.
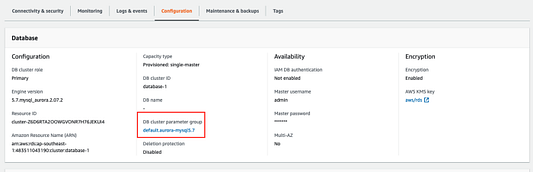
Далее нам нужно скопировать роль IAM ARN, которую вы можете найти на той же странице (см. ниже).

Нам нужно будет обновить эту роль в группе параметров кластера БД Aurora. Обратите внимание: вы не сможете изменить кластерную группу по умолчанию, созданную с помощью кластера БД Aurora. Следовательно, вам необходимо создать настраиваемую группу и изменить кластер БД Aurora, чтобы присоединить его к группе пользовательских параметров.
В группе пользовательских параметров забейте в поиск “comprehend” и отредактируйте значение параметра aws_default_comprehend_role, вставив значение ARN.
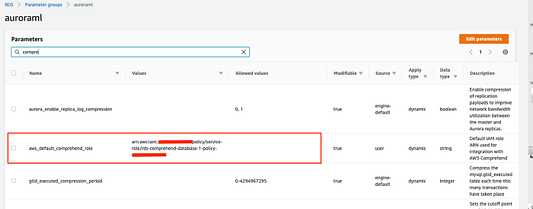
Как только это будет сделано, считайте, что настройка завершена. Теперь вы можете использовать сервис Amazon Comprehend вместе с базой данных Amazon Aurora.
Испытание модели на примере тестового набора данных
Давайте посмотрим, как вся эта система будет работать с вашей базой данных. Для этого мы создадим пробную таблицу и назовем ее Feedback. Пусть в ней будут столбцы “ID” (целочисленный тип данных с автоматическим увеличением индекса) и “user_feedback”.
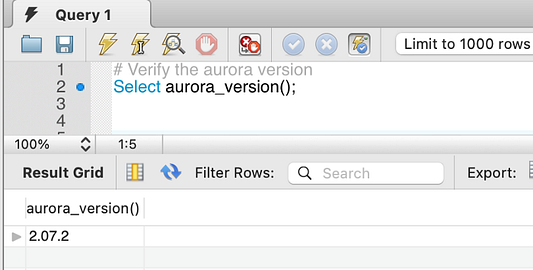
Aurora ML доступна для любого кластера Aurora, работающего под управлением Aurora MySQL 2.07.0 и более новых версий или Aurora PostgreSQL 10.11, 11.6 и новее в тех регионах AWS, где поддерживается Aurora ML.
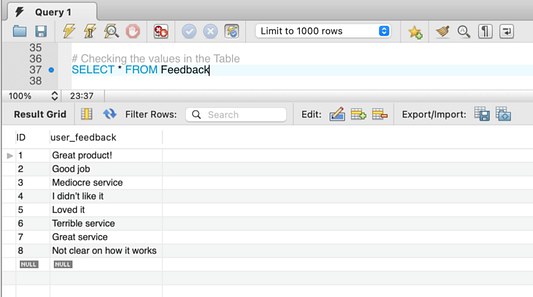
Вызвав функцию Amazon Comprehend с помощью SQL-оператора, как показано ниже, вы получите оценку тональности высказывания и достоверный прогноз. Более подробная информация об анализе тональности текста содержится в документации Amazon Comprehend.
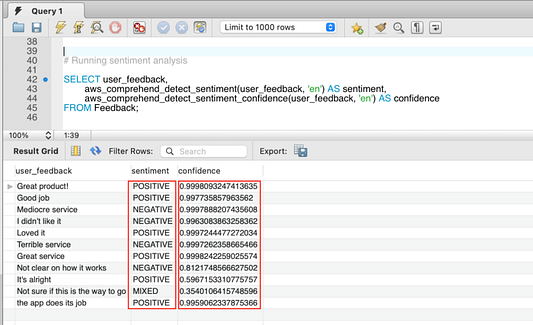
Этот SQL-запрос по умолчанию запускает анализ тона высказывания в пакетном режиме. Для построчного запуска ML-сервиса вам нужно добавить третий параметр в функцию, который должен представлять собой целое число от 1 до 25, так как ограничение по текущему пакету для функции comprehend равно 25. Ниже показан пример такого запроса.

Однако стоит помнить, что такой режим повлияет на производительность. Давайте сравним эффективность сервиса при запуске в пакетном режиме по сравнению с построчным запуском.
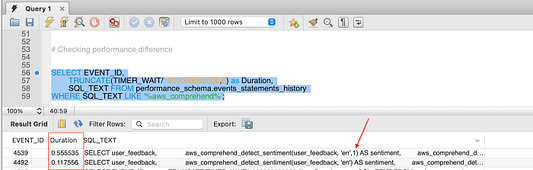
Как видите, построчный запуск (в нашем случае, 11 строк) занимает почти в 4 раза больше времени. Вот почему те, кто хотят получить результат анализа быстро, применяют режим пакетной обработки.
Некоторые варианты использования Amazon Aurora ML

Способов применения Amazon Aurora ML великое множество. Некоторые примеры приведены выше. В основном они связаны с сервисами ML, доступными в тандеме с Amazon Comprehend и Amazon SageMaker.
Заключение
Каждой команде специалистов, желающей внедрить ML-сервис в свою систему, стоит попробовать реализовать этот проект на практике. Так вы сможете продвинуться еще на одну ступеньку в изучении технологии машинного обучения.
Читайте также:
- Как инструменты дизайна интерфейса и визуализации способствуют развитию Machine Teaching?
- 5 причин смещения в машинном обучении и что с этим делать
- 5 минут на машинное обучение
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Ajatshatru Singh: Machine Learning with Amazon Aurora





