
Специалисты по анализу данных и инженеры машинного обучения часто представляют проекты предиктивной аналитики в виде конвейера — производственного процесса, который принимает четко определенные вводы и возвращает конкретные выводы. Совокупность всех взаимосвязанных этапов, а именно сбора, обработки, моделирования данных и т. д., приводит к достижению конечной цели. Вместе с тем эти процессы могут выполняться независимо друг от друга в своем собственном темпе.
Согласитесь, было бы замечательно найти способ автоматически сохранять версии результатов каждого этапа конвейера МО!
Обычно на выводе этапов конвейера мы получаем преобразованные датасеты, вручную сохраняем эти изменения и отправляем их в корзину объектного хранилища (Object Storage bucket). Однако в качестве выводов также могут производиться различные артефакты: от примитивных данных до обученных моделей МО. Есть ли способ сохранить версии всего этого? Может их замариновать? А как вам идея использовать Git? Или хранилище больших файлов Git (далее Git LFS)? Но лучше всего было бы наладить автоматическое сохранение версий всех конечных результатов, не так ли?
Далее разберем, как автоматически, даже не задумываясь, сохранить мельчайшие изменения внутри проекта.
Контроль версий для МО
Большую часть времени специалист по анализу данных проводит в Jupyter Notebook, изучая данные и придумывая новые идеи. Как правило, наши попытки сохранить версии результатов работы приводят лишь к созданию массы повторяющихся файлов ipynb, предполагающих различные схемы именования.
Существует ли средство автоматически делать снимки состояний до и после выполнения каждого этапа конвейера МО? Кроме того, возможен ли вариант его использования без долгих и утомительных настроек? Просто открываешь Jupyter Notebook, выполняешь задуманное и остаешься в полной уверенности, что все остальное будет сделано без твоего участия.
С другой стороны, невероятно сложно отслеживать блокноты Jupyter с помощью Git, а об использовании распространенной системы контроля версий (далее СКВ) в отношении датасета не может быть и речи. Git LFS заменяет крупные файлы, такие как аудио образцы, видео, датасеты и графику, на текстовые указатели в Git и хранит их содержимое на удаленных серверах — это, конечно, вариант, но далеко не оптимальный.
Также можно было бы воспользоваться системой контроля версий данных DVC, но это просто аналог СКВ Git для данных. Как правило, предложенный вариант сопряжен с дополнительными сложностями для специалистов по работе с данными, так как вряд ли кто-либо из них с энтузиазмом бросится изучать другой инструмент для решения своих задач.
Так что вопрос о том, как автоматически сохранять снимки состояний нашей работы, по-прежнему остается открытым. К счастью, мы узнали ответ и готовы поделиться с вами!
Подготовка рабочей среды
Мысль об автоматическом контроле версий всего, что мы делаем в проекте, кажется невероятной, не правда ли? Но мечты сбываются при использовании MiniKF (mini Kubeflow) на облачной платформе Google (GCP). Процесс установки этого инструмента довольно простой — для этого требуются лишь аккаунт GCP и возможность развертывания приложений из маркетплейса.
- Посетите страницу MiniKF на GCP .
2. Выберите Launch, установите конфигурацию VM (виртуальная машина) и кликните Deploy.
В целях лучшей производительности рекомендуется оставить конфигурацию VM по умолчанию.
Сказано-сделано! На развертывание уйдет около 10 минут, вы же можете отслеживать процесс по инструкциям на экране. Подключитесь к машине по ssh, выполните команду minikf в терминале и подождите полной готовности конечной точки и учетных данных:
Самое время открыть информационную панель Kubeflow. Для этого кликните по URL и введите учетные данные — вот теперь мы в полной боевой готовности.
Запуск сервера Jupyter
Что еще необходимо сделать? Нам нужен экземпляр Jupyter Notebook, который мы без особого труда создадим в MiniFK, используя имеющееся веб-приложение Jupyter:
- Выберите Notebooks в левой панели.
- Выберите кнопку
New Server. - Введите имя сервера и укажите требуемый объем CPU и RAM, после чего кликните по
LAUNCH.
Чтобы следовать этому руководству, в пункте Image оставьте Jupyter Notebooк как jupyter-kale:v0.5.0-47-g2427cc9, но имейте в виду, что тэг Image может меняться.
Завершив выполнение этих 4 этапов, дождитесь готовности сервера Notebook и подключайтесь. Вот вы и оказались в родной рабочей среде JupyterLab.
Почувствуй себя волшебником
На следующем этапе требуется преобразовать Jupyter Notebook в конвейер Kubeflow. С этой целью откройте терминал в среде JupyterLab и скопируйте репозиторий:
git clone https://github.com/dpoulopoulos/medium.git
Смените директорию на medium > minikf и запустите блокнот titanic.ipynb. Раскомментируйте первую ячейку кода и выполните ее для установки необходимых зависимостей в вашу среду. После этого предоставьте всю работу Kale, инструменту для развертывания Jupyter Notebook как компонента конвейера Kubeflow!
Если вы посмотрите на левую панель блокнота, то увидите фиолетовый значок. Именно он открывает доступ к интересным возможностям. Нажмите на него, чтобы активировать расширение Kale. И на ваших глазах каждая ячейка будет автоматически аннотироваться.
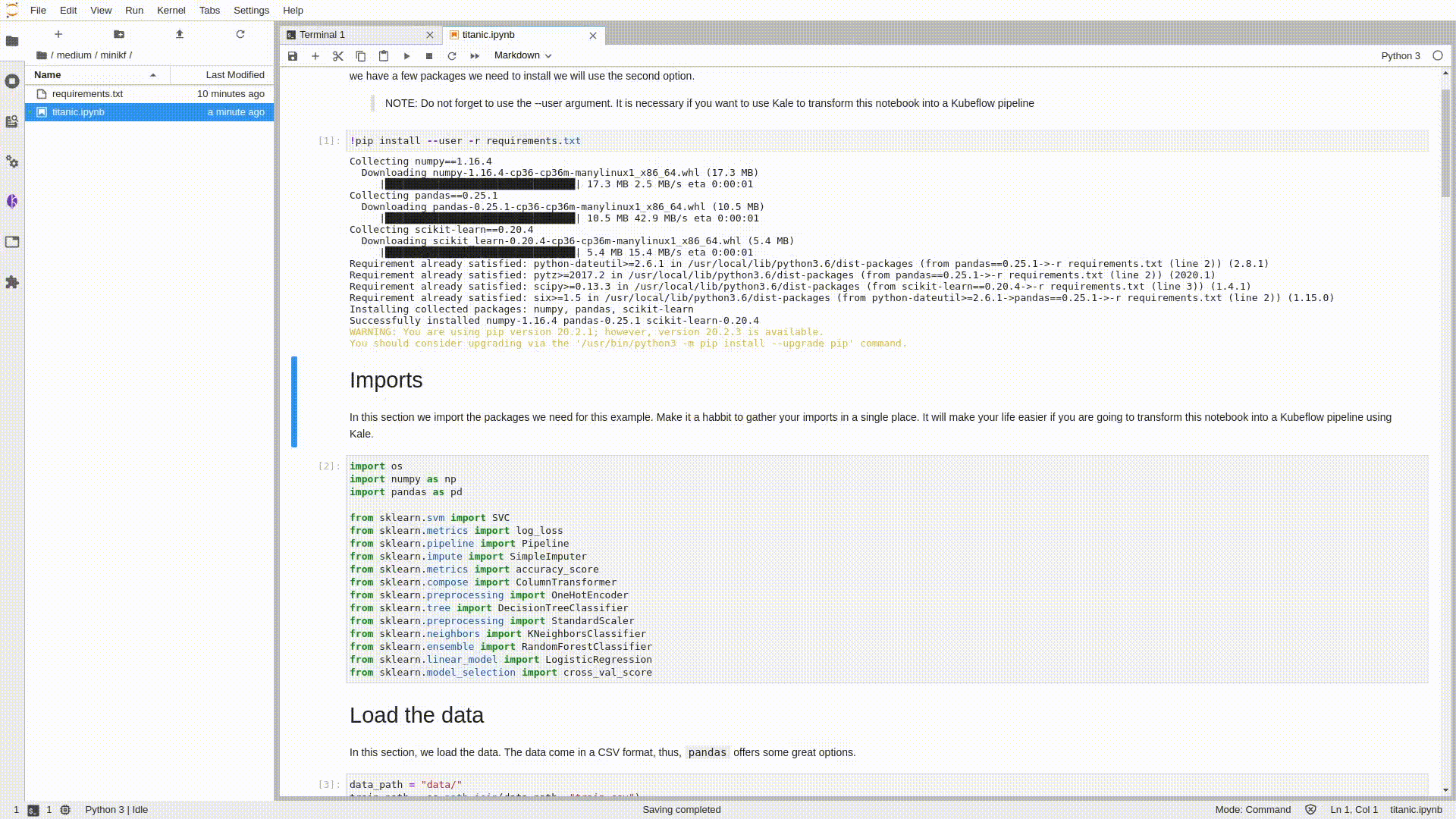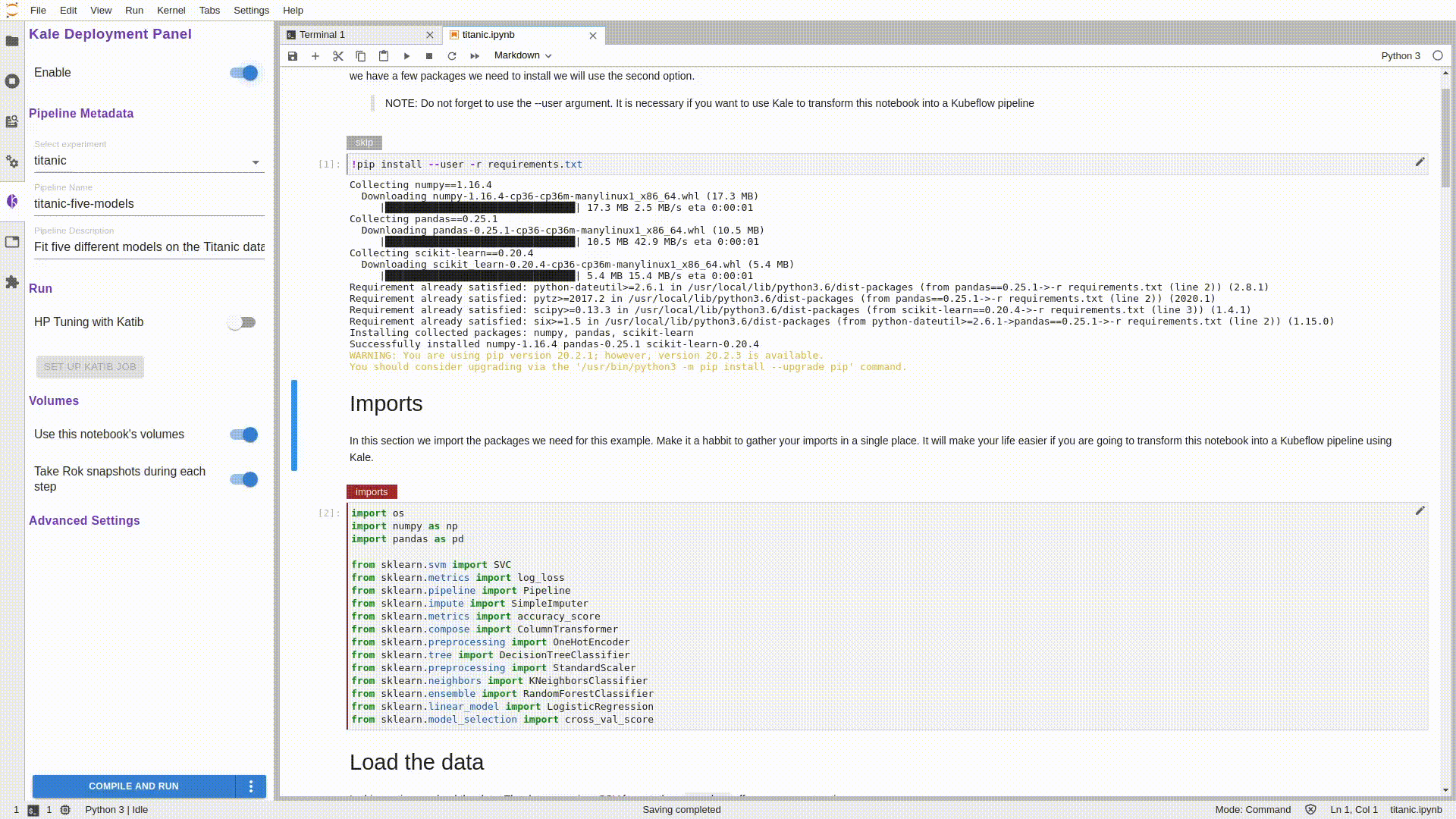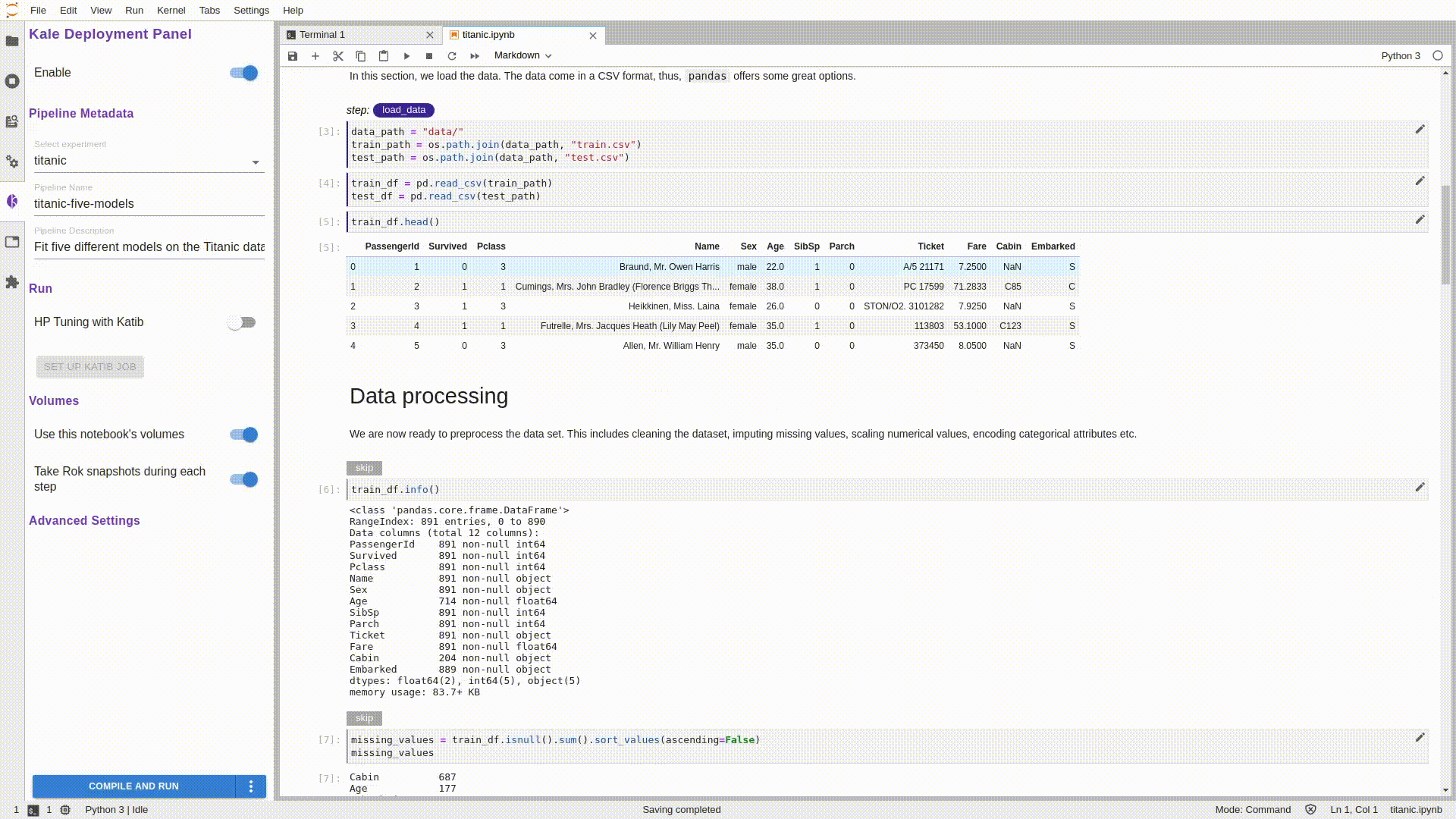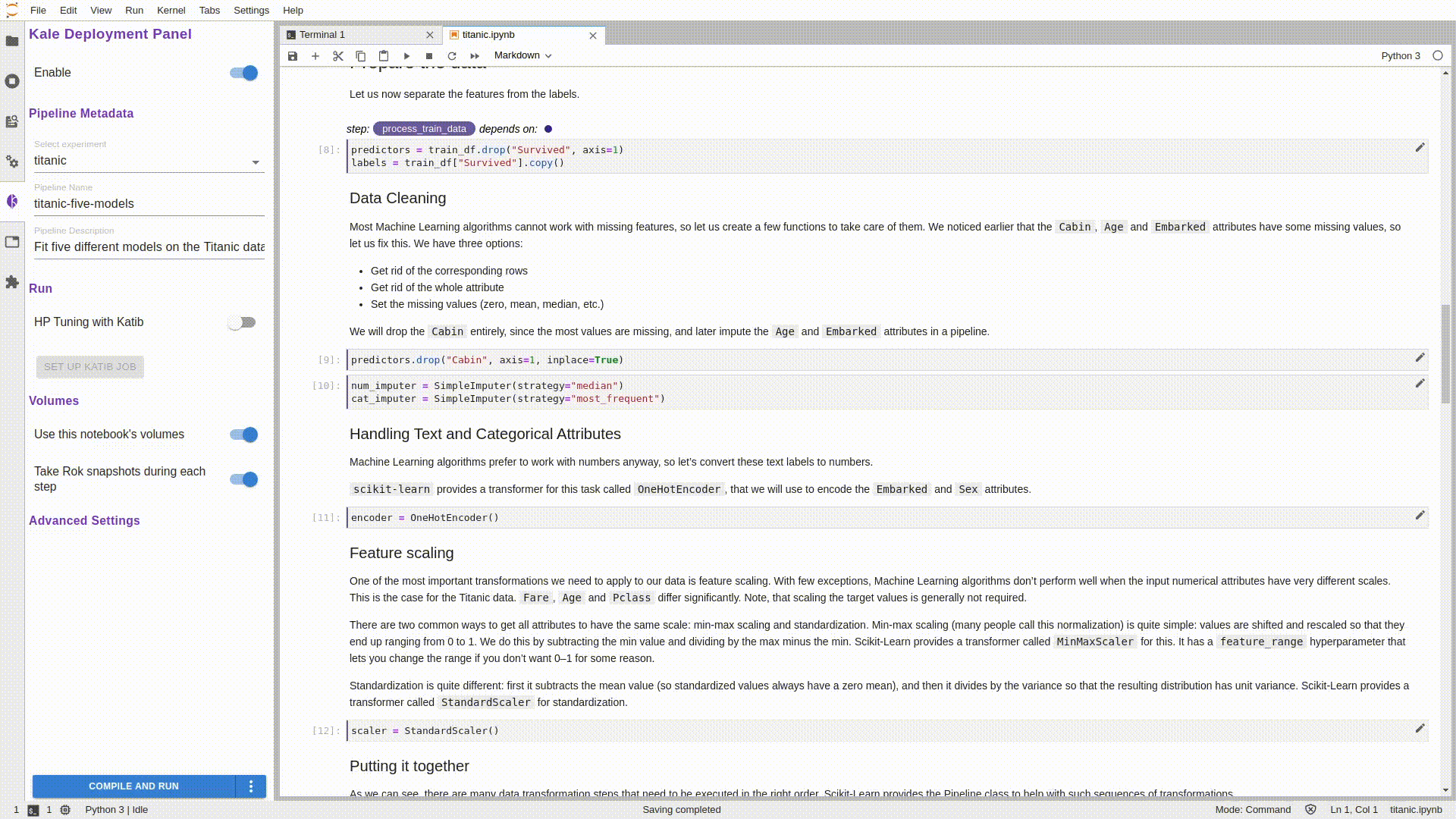
Как вы могли заметить, блокнот представлен в виде разделов: импорты, загрузка/обработка данных, обучение/оценка модели и т. д. Именно их мы снабдили аннотациями с помощью Kale. На данном этапе блокнот содержит все необходимые описания, но вы можете поэкспериментировать, создав новые этапы конвейера, но при этом не забывайте добавлять соответствующие зависимости.
В любом случае вы можете просто нажать на кнопку COMPILE AND RUN в нижней части Kale Deployment Panel. Без единой строчки кода ваш блокнот превратится в конвейер Kubeflow Pipeline, выполняемый как часть нового эксперимента.
Перейдите по ссылке, предлагаемой Kale, для наблюдения за выполнением эксперимента. Через несколько минут конвейер успешно справится с поставленной задачей. Перед вами итоговый вид графа (не забудьте включить опцию Simplify Graph в верхнем левом углу).
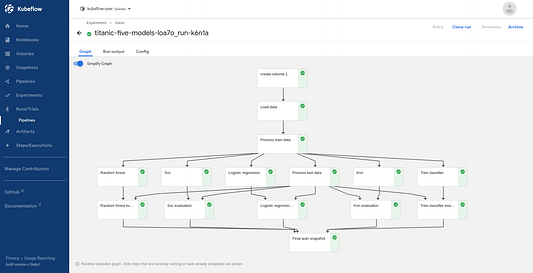
Вы могли заметить, что помимо выполнения эксперимента Kale делает еще и снимок состояния блокнота, используя Rok. Эта процедура осуществляется до начала и по завершении каждого этапа конвейера. Из этого следует, что мы в любой момент можем вернуться к определенному состоянию нашей среды разработки. Как же такое возможно?
Снимки состояний Rok
Rok — это инструмент управления данными, позволяющий делать снимки состояний, сохранять историю изменений, упаковывать, распространять, а также копировать всю среду вместе с ее данными. Он изначально интегрирован с Kubernetes в качестве одной из его поддерживаемых платформ и быстро развертывается в имеющемся кластере локально или в облаке.
Rok уже предустановлен в MiniKF, так что приступим к его применению! Предположим, нужно вернуться к состоянию среды до выполнения SVM Classifier (классификатора метода опорных векторов).
- Кликните на этап smv и выберите вкладку Visualizations.
2. Перейдите по ссылке в карточке Rok autosnapshot.
3. Скопируйте Rok URL в верхней части страницы.
4. Создайте новый сервер блокнота и вставьте вверху скопированный URL.
5. Настройте конфигурацию ресурсов VM и укажите правильное имя рабочей среды.
6. Кликните по кнопке LAUNCH.
По мере готовности сервера блокнота подключитесь к нему, и новая среда JupyterLab откроется в точно запрашиваемом месте. До этого момента все ячейки выполняются без вашего участия. Вы можете продолжить работу из этой ячейки, изучая состояние переменной и датасетов, а также обучая модели. А вот еще кое-что!
Заключение
В данной статье был рассмотрен способ автоматического сохранения версий рабочего процесса в Jupyter Notebook. Каждый эксперимент, выполняемый на MiniKF, разделен на этапы, и мы можем вернуться к любому его состоянию с помощью Rok.
Самое время приступать к экспериментам на Kubeflow, используя MiniKF. Суть рабочего процесса останется неизменной, но его возможности многократно расширятся, не требуя при этом стандартного кода.
Читайте также:
- Как ИИ меняет сферу финансов
- Глубокие нейросети: руководство для начинающих
- Как искусственный интеллект меняет финансовый сектор?
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Dimitris Poulopoulos: The Way You Version Control Your ML Projects is Wrong





