
Отладка кода на Rust — дело непростое. Может быть, она и возможна, но здесь и близко нет таких инструментов, которые позволяют осуществлять её в Java или C# отчасти потому, что внутри последних есть виртуальные машины.
Трассировка тесно связана с отладкой, но знак равенства между ними ставить всё-таки нельзя. Она позволяет программисту увидеть, как программа реагирует на внешние раздражители (например, сетевые сообщения), и изучить жизненный цикл программы. Трассировка помогает выявлять ситуации, где необходимо проведение полноценной отладки.
Для трассировки кода разработчики зачастую прибегают к старому доброму println!. В любой достаточно большой программе этот метод приведёт к заполонению программы трудноуправляемым набором инструкций println!, которые скорее запутывают, чем вносят какую-то ясность. Этот вариант не подходит, согласитесь. Давайте разберёмся, что ещё может предложить экосистема Rust.
Метод log
Следующий по сложности метод — крейт log. Этот крейт является абстрактным уровнем логирования, в нём, в свою очередь, выделяются 5 уровней важности (в порядке убывания): error!, warn!, info!, debug! и trace! . Крейт требует конкретной реализации логгера, в роли которой часто выступает env_logger как подходящая для log. env_logger проста и понятна, её приятно использовать, а для ее инициализации нужна 1 строчка:
env_logger::init();
Эта реализация позволяет быстро настроить уровень диагностических сообщений с помощью переменной окружения:
RUST_LOG=trace cargo run
Такая конфигурация отличается большой гибкостью и даёт возможность настраивать отдельные уровни для каждого модуля. Например:
RUST_LOG=module1=trace,module2=info cargo run
обеспечит вывод логгером только сообщений более высокой или равной важности в сравнении с тем, что указано в соответствующих модулях.
Этого метода достаточно во многих случаях. Например в крупных проектах, таких как Hyperledger Indy, он используется по полной: вход в функцию и выход из неё сопровождаются лог-инструкциями, выводящими входные параметры и результат функции.
Асинхронный код
Прежде чем идти дальше, позволим себе небольшое отступление. Многие (если не все) сетевые приложения позволяют принимать внешние сообщения/запросы до того, как будет обработано ранее принятое сообщение/запрос. В таких случаях на помощь приходит асинхронный код. Писать асинхронный код в Rust стало легче после выхода версии Rust 1.39, а самое главное — после того, как многоцелевая платформа tokio, использующая компоненты futures, и HTTP-библиотека hyper стали поддерживать вновь появившуюся функциональность. Вся эта работа в совокупности оказала огромное влияние на то, как пишется асинхронный код Rust. Важно отметить, что в tokio появилось понятие задачи, т.е. части работы, которая выполняется параллельно в многопоточном контексте, причём задача может приостанавливаться и передаваться между потоками. Задачи приостанавливаются на вызовах await до тех пор, пока вызов не будет завершен, например пока не произойдёт какое-то событие или не будут получены необходимые данные.
Метод tracing
Если крейт log работает, зачем искать другой вариант? Для этого есть свои причины:
- Размер. Хотя лог трассировки растёт линейно по отношению к размеру кодовой базы, он всё же может стать слишком громоздким для ручного контроля.
- Замусоривание кода. Лог-инструкции, несмотря на их пользу, часто ухудшают читаемость кода, особенно при выводе аргументов функций и результатов вычислений.
- Асинхронный код. Параллельное выполнение вносит сумятицу в трассировку.
log-трассировки из разных задач часто перемешиваются друг с другом, что затрудняет их обработку.
Поэтому возникает вопрос: какова альтернатива? Такой альтернативой выступает крейт tracing. Этот крейт обеспечивает инструментальную функциональность для сбора структурированной информации при проведении диагностики приложения. В основе этой функциональности лежит предпосылка о том, что всё логирование происходит внутри так называемых спанов. Спан — это непрерывный отрезок времени с определённым началом и концом. В спаны осуществляется вход и выход. Кроме того, в спаны может осуществляться вход и выход внутри другого спана. Это свойство определяет отношение включения на множестве всех спанов. Отношение включения позволяет структурировать диагностические сообщения во временной области, а главное — определяет причинно-следственную связь в спанах. Последнее очень важно в асинхронном коде, когда задачи можно приостановить и продолжить.
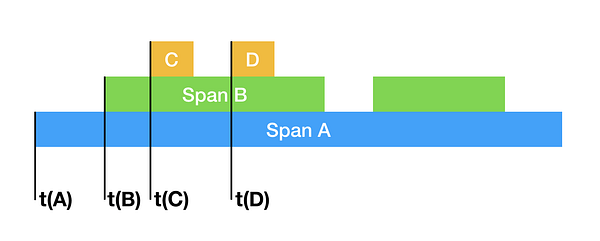
На приведённой выше диаграмме задача А связана со спаном А, задача В — со спаном В и т. д. Обозначим соответствующее время начала задач через t(·). Во временной области эти задачи располагаются строго в соответствии с порядком очерёдности времени их начала, т. е. t(A) < t(B) < t(C) < t(D). В причинно-следственной области такой порядок очерёдности сохраняется уже частично. Это можно представить, использовав знак включения множества (так A ⊆ B, B ⊆ C, B ⊆ D, B обусловлена задачей A, C — задачей B и т. д.).
Крейт tracing имеет открытый, расширяемый интерфейс, позволяющий подключать различных подписчиков или устройства для сбора сообщений трассировки. Простейший подписчик выдаёт эти сообщения прямо на стандартный вывод. Едва ли это лучший вариант. К счастью, он не единственный. Чтобы быть лучшими, такие трассировки:
- Должны быть перманентными, т. е. доступными и тогда, когда приложение не выполняется.
- Должны иметь лёгкий доступ с разных хостов, а не только с хоста, выполняющего приложение.
tracing-opentelemetry — один из подписчиков, удовлетворяющих этим требованиям.
Давайте попробуем его!
Создадим асинхронную функцию, выполняющую какую-то тяжелую работу:
struct Dummy;
#[tracing::instrument(skip(_dummy))]
async fn heavy_work(id: String, units: u64,
_dummy: Dummy) -> String {
for i in 1..=units {
tokio::time::delay_for(Duration::from_secs(1)).await;
tracing::info!("{} has been working for {} units", id, i);
}
id
}Разберёмся, что тут происходит.
- Инструментирование. Макрос
#[tracing::instrument]фактически создаёт спан для этой функции и входит в него. Он использует имя функции и её параметры для своих метаданных. Таким образом создаётся требование для реализации этими параметрами типажаDebug. Для исключения параметра из метаданных применяемskipв команде инструментирования. Дополнительные атрибуты можно найти здесь. tracing::info!выполняет саму трассировку.
Давайте повторно используем функцию инициализации трассировщика init_tracer — она достаточно хороша для начала разработки, и мы сможем внести в неё изменения, когда потребуется дополнительная настройка.
И, наконец, функция main:
#[tokio::main]
async fn main() {
init_tracer().expect("Tracer setup failed");
let root = tracing::span!(tracing::Level::TRACE, "lifecycle");
let _enter = root.enter();
let rng = rand::thread_rng();
let normal = rand_distr::Normal::new(5.0, 1.0).unwrap();
let mut finished_work = normal
.sample_iter(rng)
.take(10)
.map(|t| heavy_work(t.to_string(), t.to_u64().expect("Must convert"), Dummy))
.collect::<FuturesUnordered<_>>();
while let Some(id) = finished_work.next().await {
tracing::info!("{} has completed", id);
}
}Нас здесь интересует то, что эта функция инициализирует трассировщик и входит в корневой спан. Всё остальное — просто оболочка, которая вызывает функцию, выполняющую тяжелую работу и получающую результаты.
Компилятор Rust удаляет синтаксический сахар асинхронных функций в конечный автомат, который опрашивается во время выполнения. То, что кажется единственным функциональным вызовом, для программиста — это фактически акт повторного обращения к функции. Для трассировки же это означает, что в соответствующий спан будет осуществлён многократный вход и выход, прежде чем завершится конечный автомат. Такое поведение представляет проблему для трассировки, ведь оно усложняет обработку включений спанов. Вместо одного большого спана, соответствующего асинхронному фрагменту кода, будет множество маленьких спанов.
Одним из вариантов для парсинга логов трассировки (с соблюдением требований opentelemetry) является Jaeger. Этот инструмент специально предназначен для повышения наблюдаемости выполняемых приложений.
Для сбора и анализа трассировок необходимо установить Docker. Запускаем Jaeger:
docker run -d -p6831:6831/udp -p6832:6832/udp -p16686:16686 jaegertracing/all-in-one:latest
Теперь приложение.
Откройте браузер и перейдите на http://localhost:16686/. То, что вы увидите, не может не впечатлить. Это набор инструментальных средств, полный чётких визуализаций и аналитических инструментов:
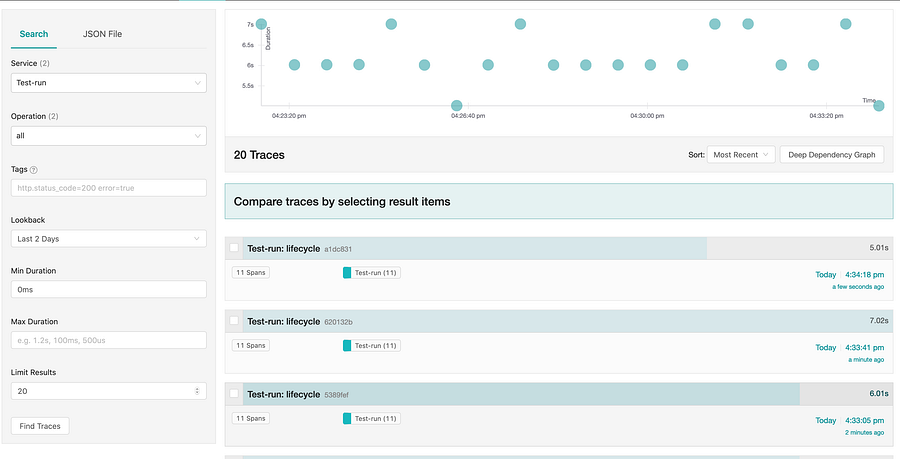
Я создал небольшой скрипт, непрерывно запускающий приложение для имитации нагрузки, благодаря которой наверху заполняется диаграмма времени выполнения.
Каждую трассировку можно изучить структурно и по времени.
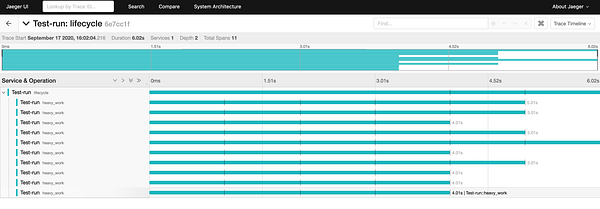
Каждый спан соответствует вызову функции. Обратите внимание, как аккуратно сгруппированы сообщения от нескольких асинхронных подвызовов, создавая впечатление непрерывного выполнения.
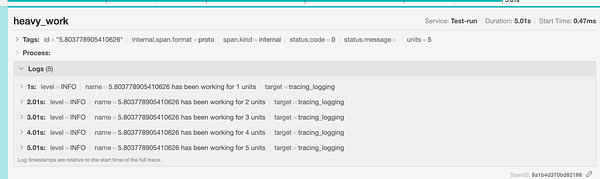
Метаинформация спана облегчает просмотр аргументов функций, например units = 5.
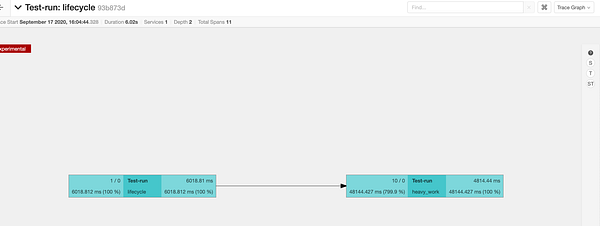
Следующий уровень (экспериментальной) сложности — это диаграмма, представляющая причинно-следственную связь, которую мы рассматривали чуть выше. Её можно найти в выпадающем списке Trace Timeline, временной шкале трассировки.
Заключение
Крейты tracing и tracing-opentelemetry позволяют выполнять простую и понятную трассировку приложений Rust. А Jaeger делает такие трассировки удобными для восприятия, дополняя их аналитическими данными. В статье мы лишь упомянули о возможностях, предоставляемых этими инструментами, но это хорошая отправная точка для дальнейшего изучения!
Исходный код можно найти на Github.
Читайте также:
- Rust: работа с потоками
- Как спроектировать REST API для выполнения системных команд с помощью Actix Rust
- Кросс-компиляция программ Rust для запуска на маршрутизаторе
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Victor Ermolaev: Enabling Diagnostics for Rust Code





