
Обнаружение объектов — широко известная задача компьютерного зрения, по которой было проведено огромное число исследований. Методы же контролируемого обнаружения объектов стали в этой области эталоном. Однако в связи с неудобством сбора большого количества данных с точными аннотациями уровня объекта слабо контролируемое обнаружение в последнее время привлекло обширное внимание.
1. Вступление
В слабо контролируемом обнаружении объектовприсутствуютаннотации уровня изображений, определяющие присутствует объект или нет. Именно наличие таких аннотаций уровня экземпляров и отличает этот метод от стандартного контролируемого обнаружения.
Обычно такой подход состоит из двухэтапной процедуры обучения:
- детектора обучения с использованием нескольких экземпляров (MIL);
- детектора полностью контролируемого обучения с регрессией ограничительной рамки (подробнее в пункте 3).
Единая сквозная сеть спроектирована с применением как детектора многовариантного обучения, так и детектора управляемого обучения с целью устранения проблемы локального минимума (подробнее в пункте 2), возникающейпридвухфазовом подходе.
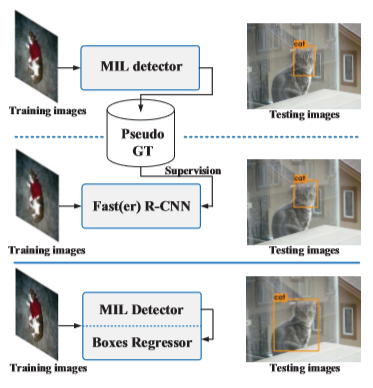
2. Обоснование
В первом двухфазовом подходе для обучения детектора MIL использующего CNN в качестве выделителя признаков, применяется обучение с использованием нескольких экземпляров.
Во второй фазе для дальнейшего уточнения (регрессии) местоположений объектов используется полностью контролируемый детектор Fast R-CNN. Для его контроля используются выходные данные предполагаемых областей (псевдо-предполагаемые области), полученные в первой фазе.
Этот двухфазовый подход может привести к объясняемой далее проблеме локального минимума.
2.1 Проблема локального минимума
Иногда детектор MIL в первой фазе начинает с неточных ограничительных рамок. Он фокусируется на отличительных частях объекта, например, на голове кошки.
Это, в свою очередь, может привести к созданию ошибочных предположений областей (псевдо-предполагаемых областей), которые в следующей фазе используются в качестве псевдо-контрольных данных (поскольку отсутствуют аннотации уровня экземпляров).
В итоге во второй фазе точное местоположение объекта не может быть изучено, так как входной сигнал уже переобучен не в той области.

Отсюда следует, что детектор MIL и регрессор ограничительной рамки обучаются совместно, из-за чего регрессор способен начать подстраивать прогнозируемые рамки прежде, чем детектор MIL полностью сфокусируется на отличительных частях и предоставит ошибочные результаты.
3. Основные составляющие
3.1 Обучение с использованием нескольких экземпляров (MIL)
MIL в своей основе является вариацией управляемого обучения, которая присваивает набору (мешку) экземпляров единую метку вместо того, чтобы помечать их по отдельности.
Если все экземпляры конкретного набора оказываются отрицательными, то и весь набор маркируется как отрицательный. Если присутствует хотя бы один положительный экземпляр, тогда набор маркируется как положительный.
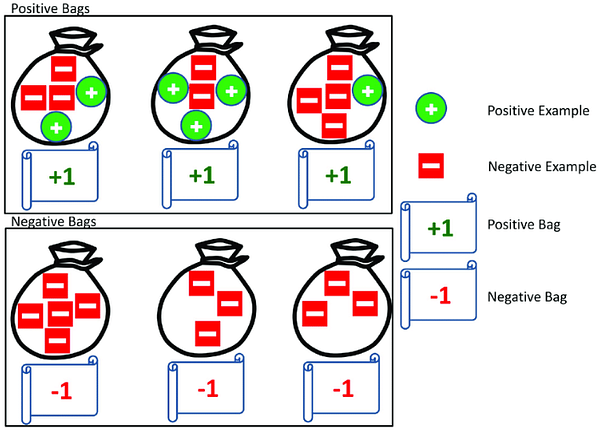
MIL — это слабо контролируемый процесс обучения, который отбирает прогнозы объекта из предполагаемых областей, сгенерированных некоторым методом, которым является метод Selective Search Windows (SSW) (окна избирательного поиска, подробнее в пункте 3.3).
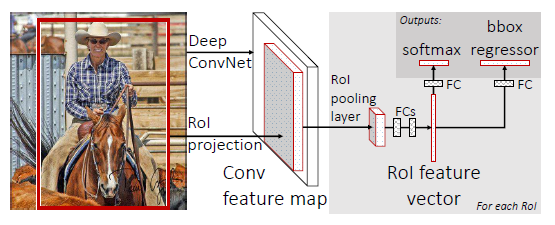
3.2 Детектор полностью контролируемого обучения (Fast R-CNN)
Архитектура Fast R-CNN состоит из CNN, предварительно обученной на весах ImageNet и используемой для извлечения признаков.
Заключительный суб дискретизирующий слой (pooling layer) замещается ROI pooling layer, который будет генерировать ограничительные рамки вокруг местоположений объектов. Последний полносвязный слой замещается двумя ветками:
- ветка классификации;
- ветка регрессии ограничительной рамки.
Ветка классификации будет прогнозировать класс, к которому принадлежит объект, а ветка регрессии будет уточнять координаты ограничительной рамки.
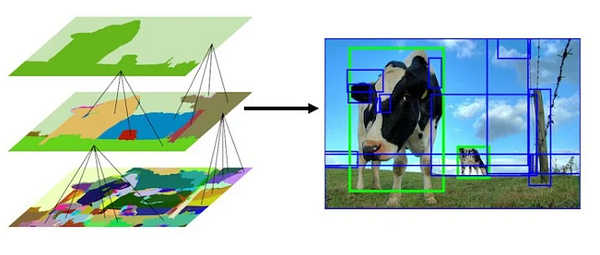
3.3 Окна избирательного поиска (SSW)
Избирательный поиск — это алгоритм предположения областей, используемый для обнаружения объектов. В этом методе применяется иерархическое группирование схожих областей на основе цвета, текстуры, размера и формы.
Он начинает с чрезмерной сегментации изображения, а затем добавляет все ограничительные рамки, соответствующие сегментированным частям, в список предполагаемых областей. После этого группирует смежные сегменты на основе сходства и повторяет процедуру.
4. Метод
Он состоит из трех основных компонентов: модуля управления вниманием (GAM), ветки MIL и ветки регрессии в предполагаемой слабо контролируемой сети обнаружения объектов (WSDDN).
Сначала при помощи GAM расширенная карта признаков извлекается из CNN из входного изображения. ROI pooling layer из CNN генерирует признаки областей, которые позже передаются в ветку регрессии и ветку MIL.
Затем ветка MIL предлагает местоположения объектов и категории, которые далее принимаются в качестве псевдо-предполагаемой области для ветки регрессии, которая уже выполняет регрессию местоположения и классификацию.
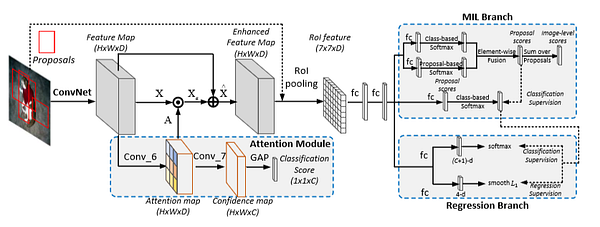
4.1 Модуль управления вниманием
Ниже приводится традиционная пространственная структура внимания.
- Модуль внимания получает на входе карту признаков X, извлечённую из ConvNet, и генерирует пространственно-нормализованную карту весов внимания на выходе.
- Выходная карта внимания перемножается с исходной картой признаков X для получения наблюдаемого признака.
- Затем наблюдаемый признак добавляется в X для получения расширенной карты признаков. Это поможет придать большую значимость соответствующим признакам и подавит неподходящие.
- Для отслеживания обучения весов внимания добавляется потеря классификации.
- Для получения вектора очков классификации карта внимания передаётся на другой свёрточный слой и слой Global Average Pooling (GAP).
4.2 Ветка MIL
Ветка MIL вводится для инициализации аннотаций псевдо-предполагаемой области.
Здесь используется сеть онлайн-отбора классификаторов экземпляров (Online Instance Classifier Refinement, OICR), основанная на слабо контролируемых сетях глубокого обнаружения, что повышает её эффективность и предоставляет возможность сквозного обучения.
Классификация и обнаружения являются двумя потоками, используемыми слабо контролируемыми сетями глубокого обнаружения. При совмещении этих двух потоков можно получить прогнозы уровня экземпляров.
У таких сетей есть собственные недостатки, поэтому для дальнейшего повышения качества генерации плотных ограничительных рамок используется сеть онлайн-отбора классификаторов экземпляров и ее усовершенствованная версия обучение кластеров предположений (Proposal Cluster Learning, PCL).
4.3 Ветка Multi-Task
Ветка multi-task используется для оперирования полностью контролируемой классификацией и регрессией после генерации аннотаций псевдо-предполагаемой области.
В ней находится ветка обнаружения, имеющая два ответвления. Первое ответвление прогнозирует дискретное распределение вероятностей, которое вычисляется функцией softmax через выходные данные полносвязного слоя. Второе ответвление выводит смещения регрессии ограничительной рамки для каждого из классов объектов.
Ветка multi-tusk работает аналогично архитектуре Fast R-CNN.
5. Эксперименты и результаты
5.1 Наборы данных и метрики вычислений
В вычислениях используются наборы данных PASCAL VOC 2007 и 2012. Они включают 9963 и 22531 изображений с 20 классами соответственно. Набор train-val используется для обучения 5011 изображений для PASCAL VOC 2007 и 11540 для PASCAL VOC 2012.
Метрики вычисления средней точности (Average Precision, AP) и средней AP (mAP) используются для проверки модели на тестовом наборе. В целях измерения точности локализации для вычисления модели также используется Correct Localization (CorLoc) — корректор локализации.
Критерий PASCAL: для вычисления используется IOU>0.5 между контрольными данными и прогнозируемыми рамками.
5.2 Сравнение с эталоном
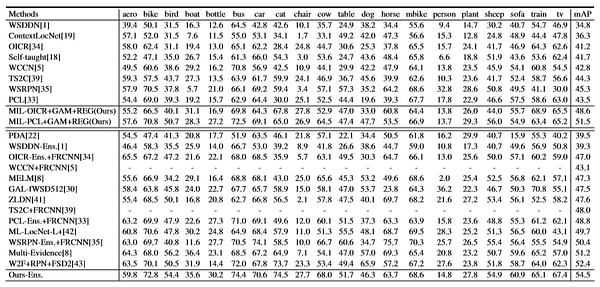
При помощи предлагаемого метода качество mAP улучшено на 48.6% по сравнению со всеми остальными методами в тестовом наборе PASCAL VOC 2007:
При помощи предлагаемого метода качество mAP улучшено на 46.8% по сравнению со всеми остальными методами в тестовом наборе PASCAL VOC 2012:
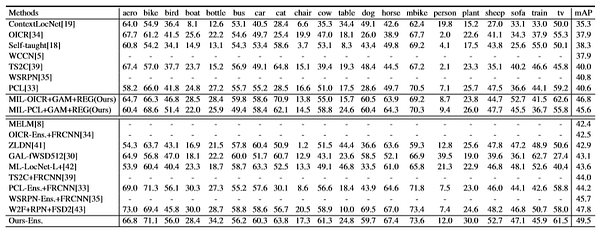
При помощи предлагаемого метода качество корректной локализации (CorLoc) улучшено на 66.8% по сравнению со всеми остальными методами в train-val наборе PASCAL VOC 2007:
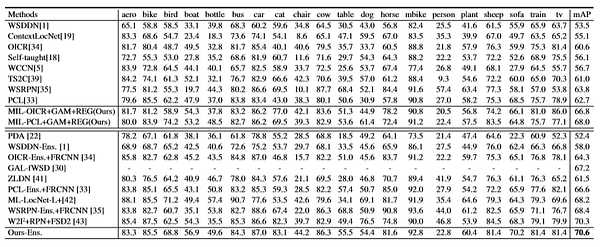
С помощью предлагаемого метода качество корректной локализации (CorLoc) улучшено на 69.5% по сравнению со всеми остальными методами в наборе train-val PASCAL VOC 2012:
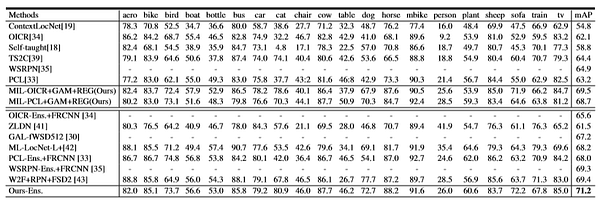
5.3 Улучшения при использовании предлагаемого метода

6. Заключение
- Представлен новейший фреймворк, предназначенный для решения задач слабо контролируемого обнаружения объектов, который показывает себя лучше, чем традиционные подходы в этой области.
- Предложенный метод совместной оптимизации обнаружения MIL и регрессии в сквозном исполнении достигает желаемых результатов с помощью устранения проблемы локального минимума и добивается более высокой точности в эталонных датасетах PASCAL VOC 2007 и 2012.
- Для лучшего обучения признаков вводится модуль управления поведением (GAM). Предлагаемый фреймворк также может доказать свою эффективность в решении дальнейших задач по визуальному обучению.
В статье использована ссылка на англоязычный материал: Ke Yang, Dongsheng Li, and Yong Dou. “Towards Precise End-to-end Weakly Supervised Object Detection Network”. ICCV, 2019.
Читайте также:
- Наглядное объяснение алгоритма Беллмана-Форда
- Как работает GPT3
- Гениально или глупо? Самая неоднозначная нейросеть
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Yesha R Shastri: Weakly Supervised Object Detection — An End to End Training Pipeline





