
Обученная языковая модель генерирует текст. В качестве входных данных при желании ей можно также передать некоторый текст, влияющий на выходные данные. Выходные данные генерируются из того, что модель выучила, когда сканировала огромные объёмы текста.
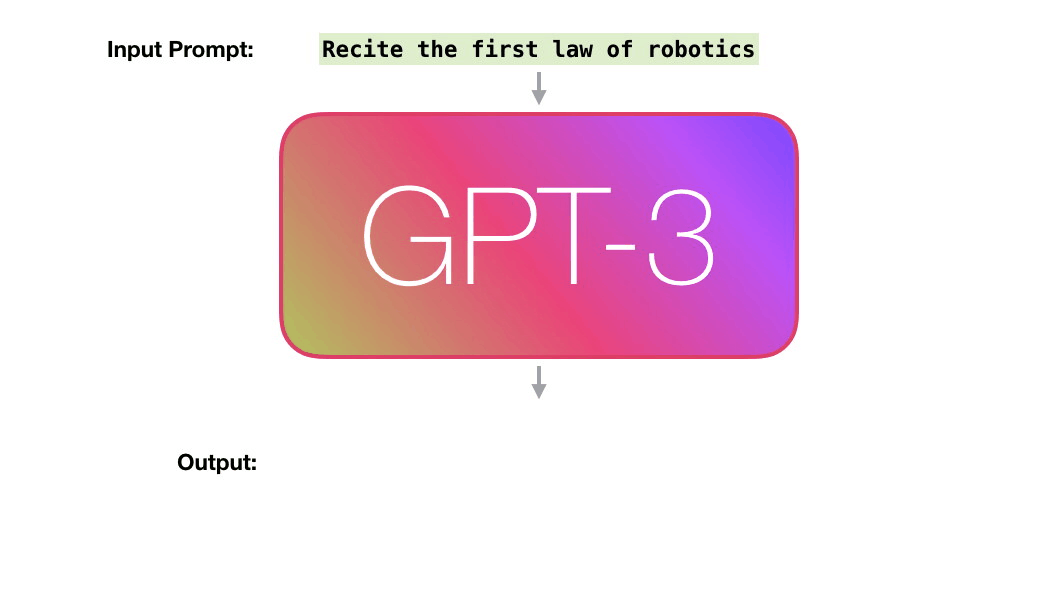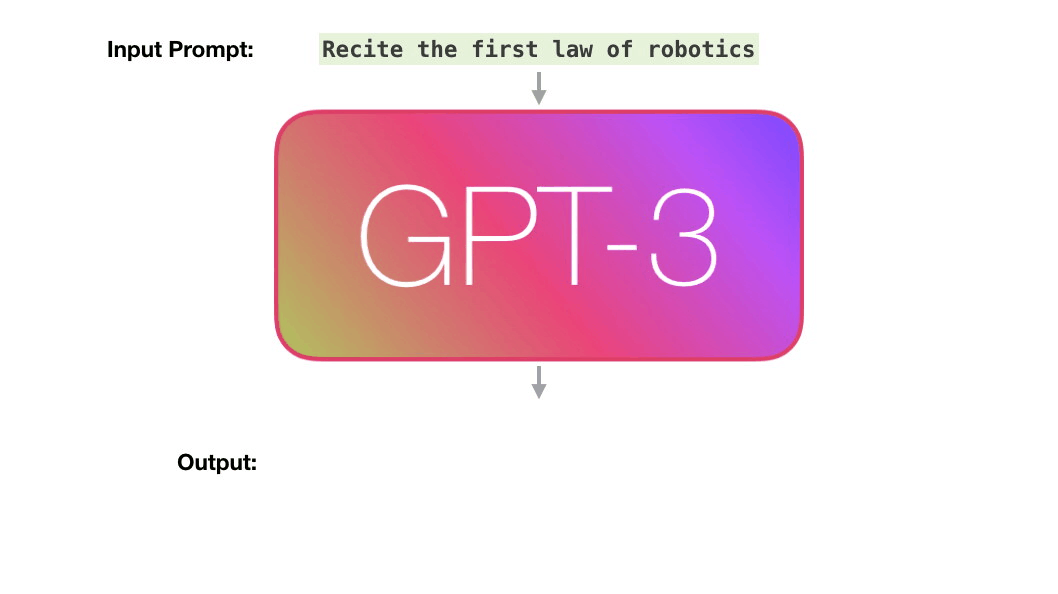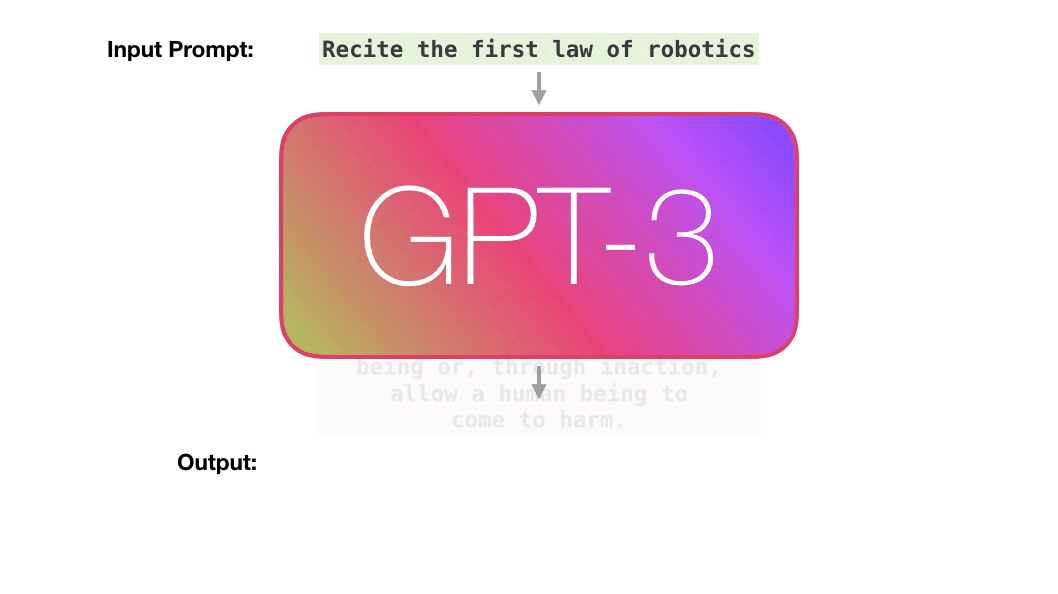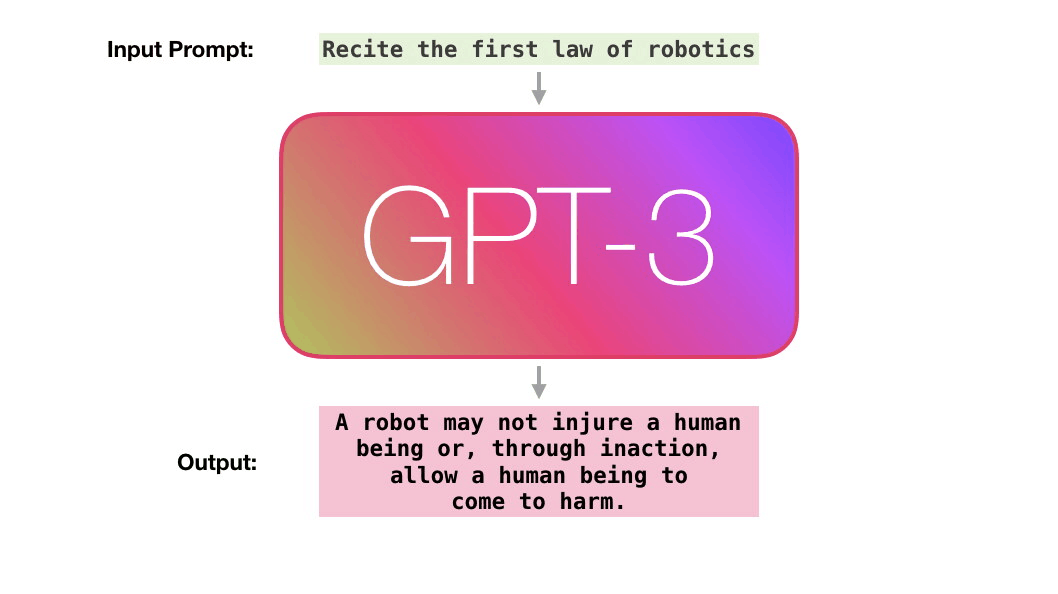
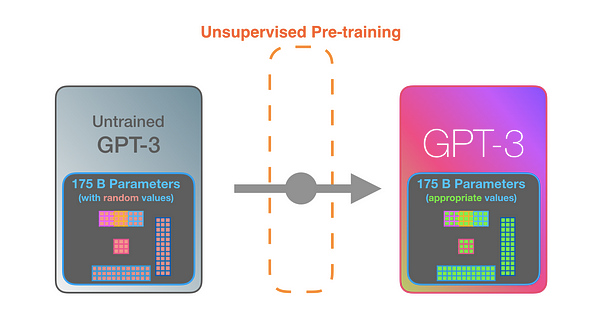
Обучение — это процесс ознакомления модели с большим количеством текста. Этот процесс был завершён. Все эксперименты, которые вы видите сейчас, проводятся на одной обученной модели. Предполагалось, что на это уйдёт 355 GPU-лет и 4,6 миллиона долларов.
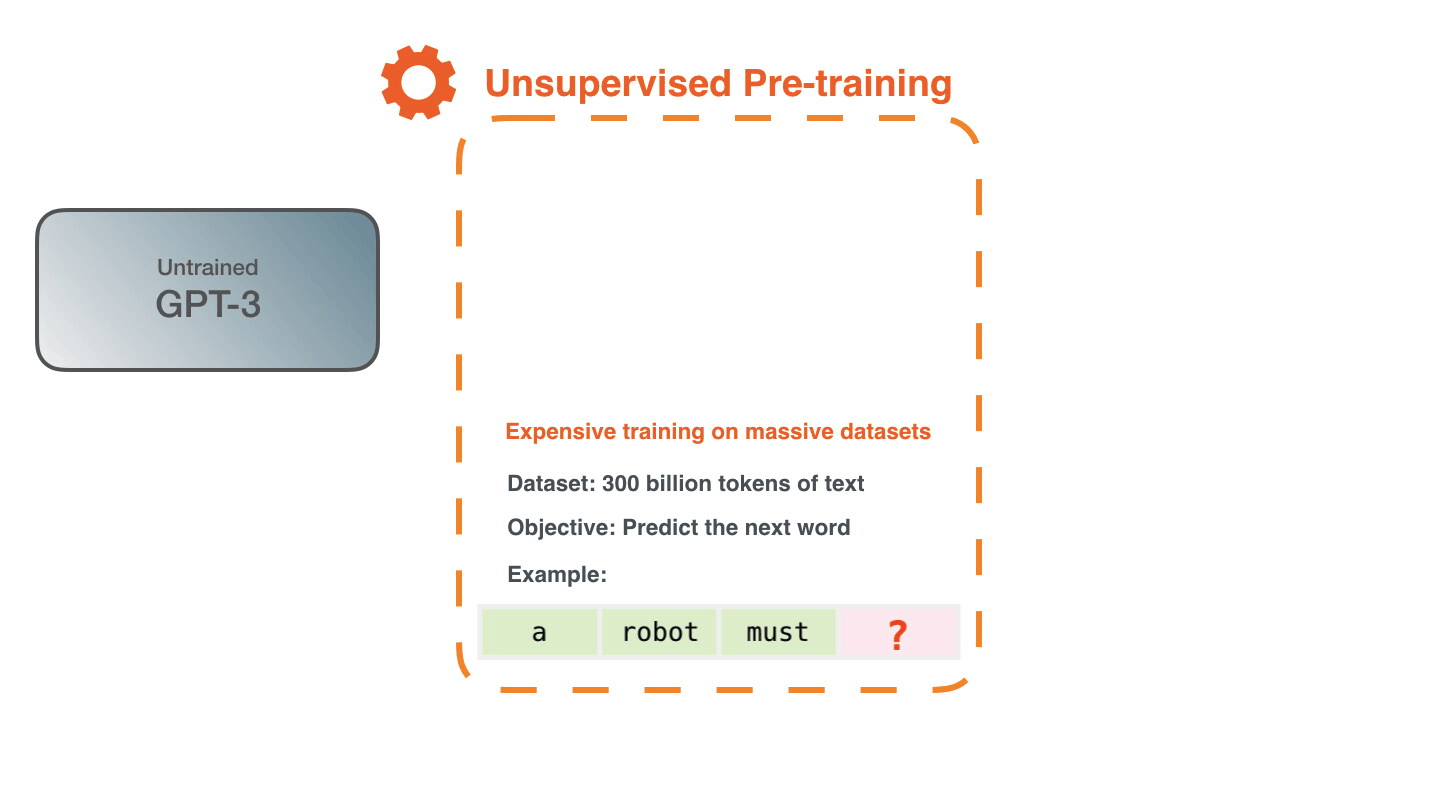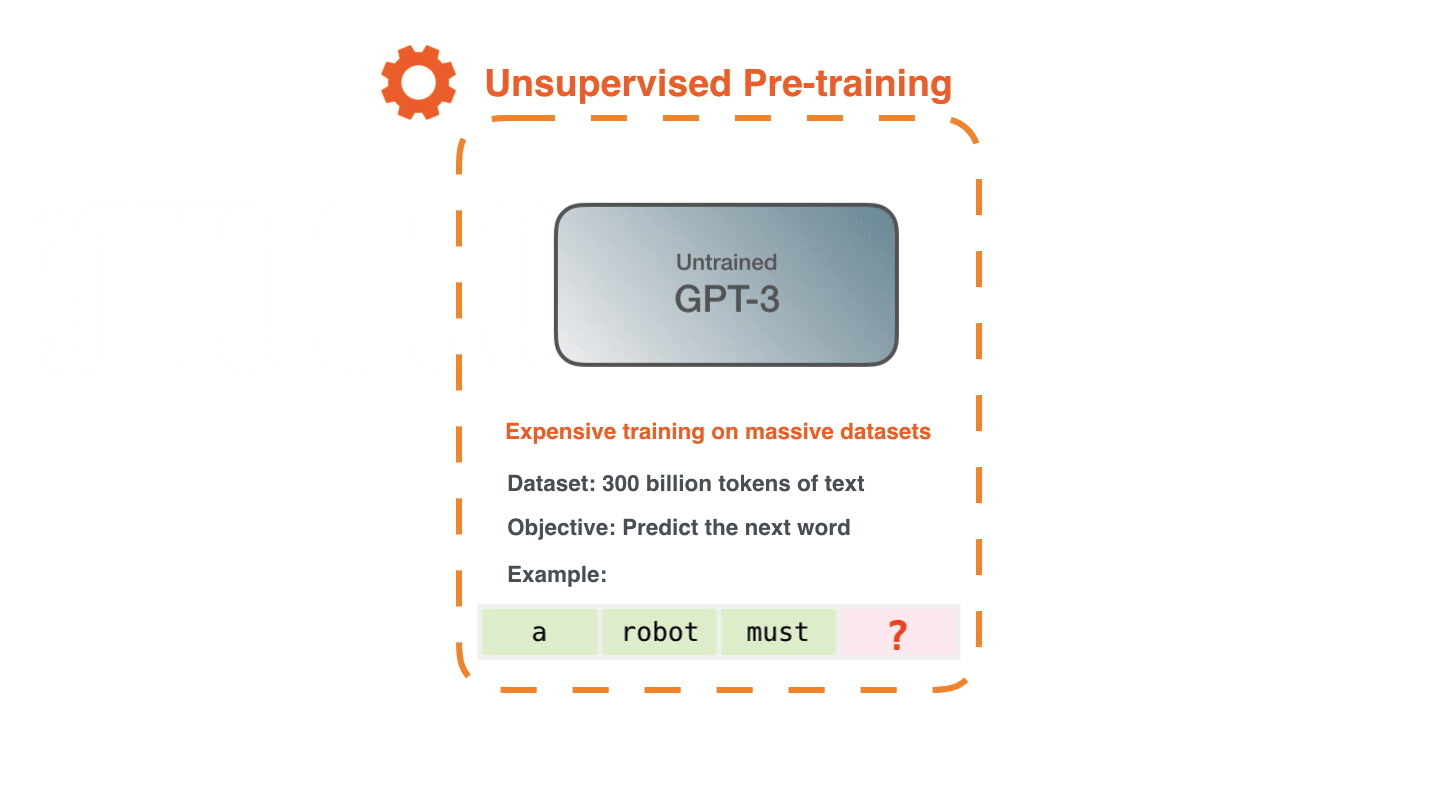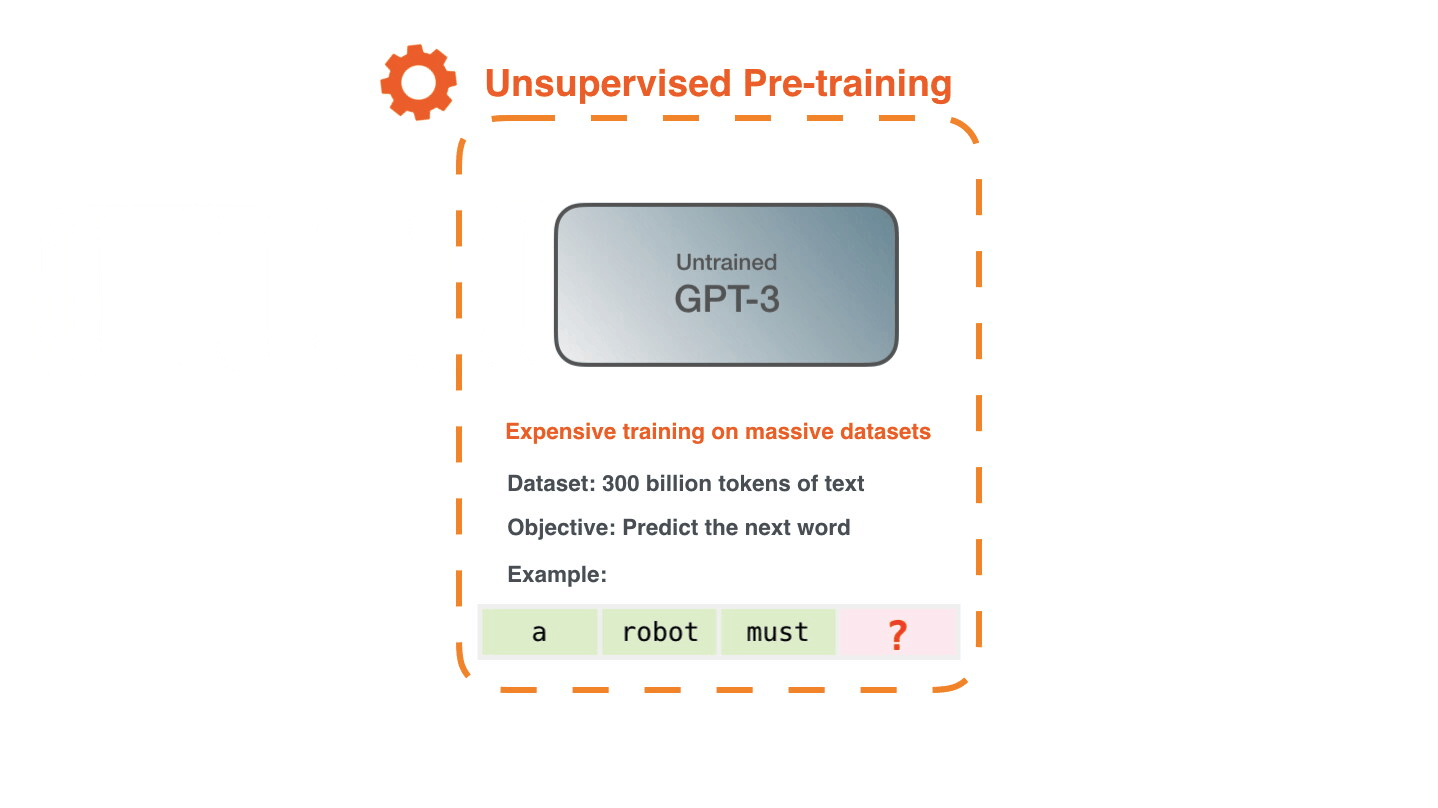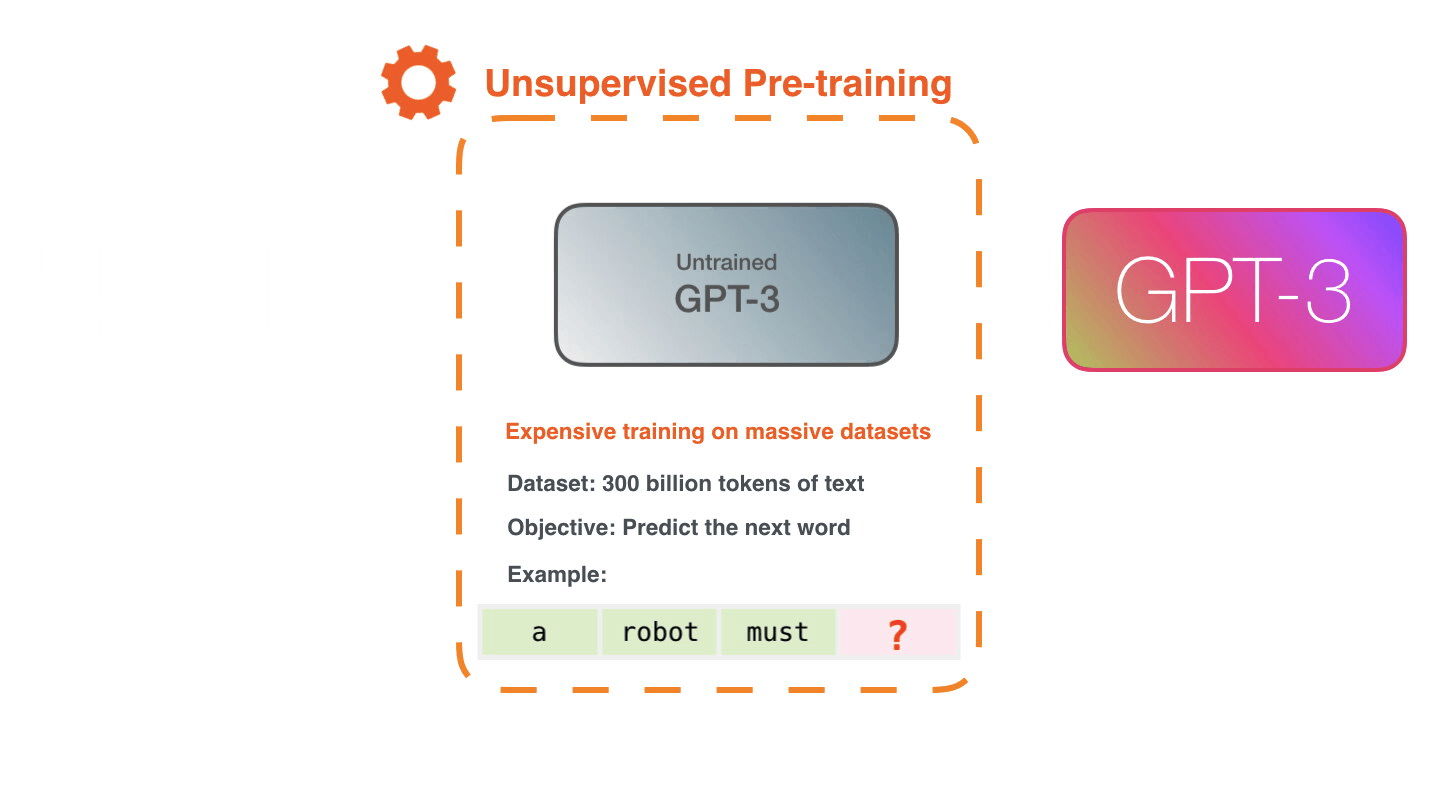
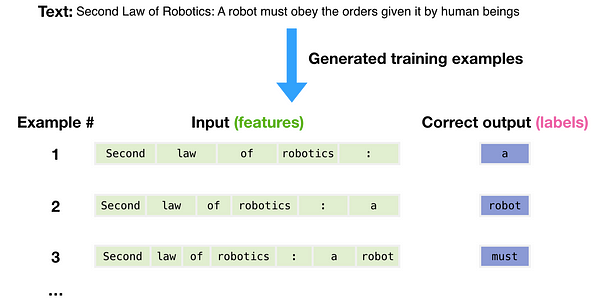
Для создания обучающих примеров для модели использовался набор данных из 300 миллиардов токенов текста. Эти три примера обучения собраны из предложения выше. Как видите, перемещаться по тексту и создавать множество примеров очень легко.
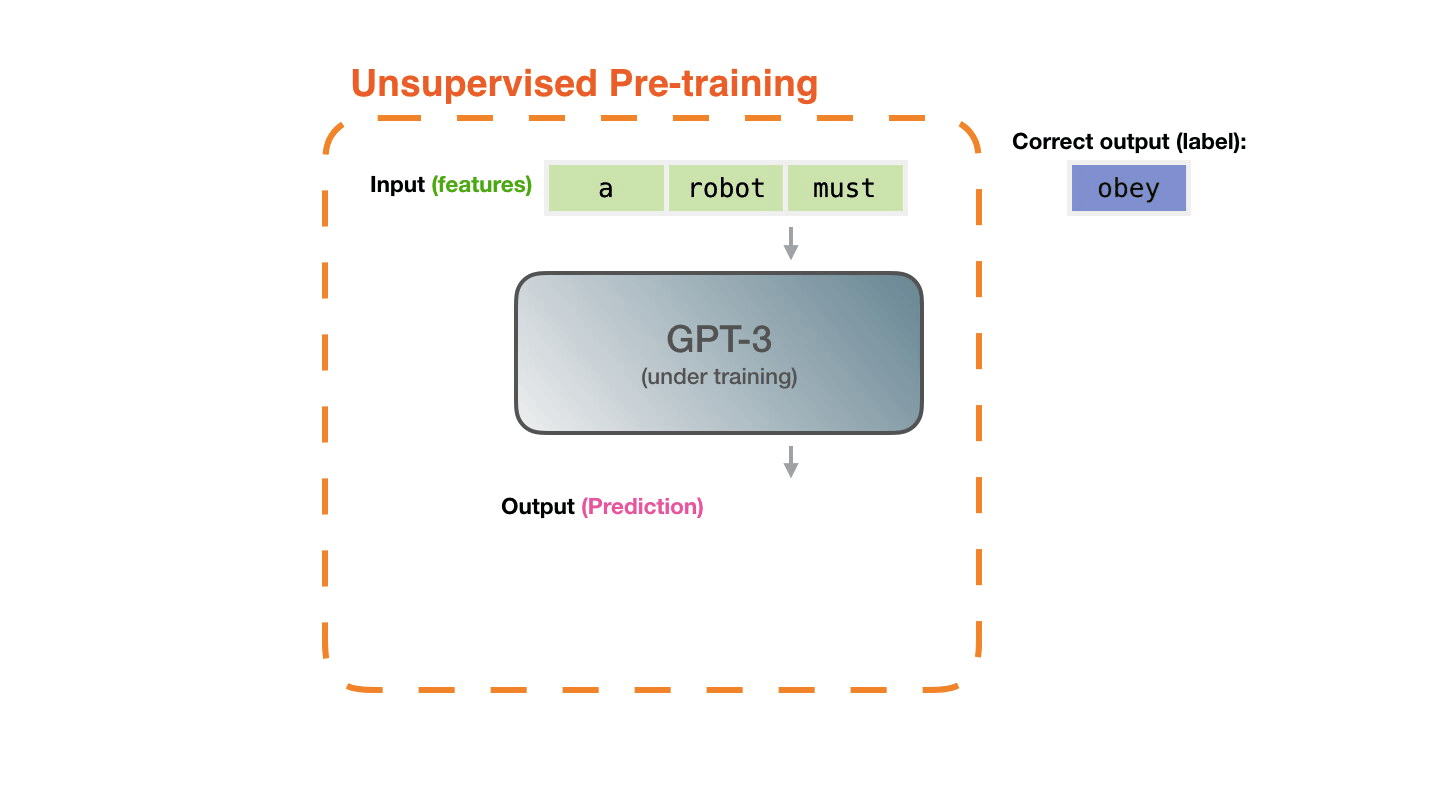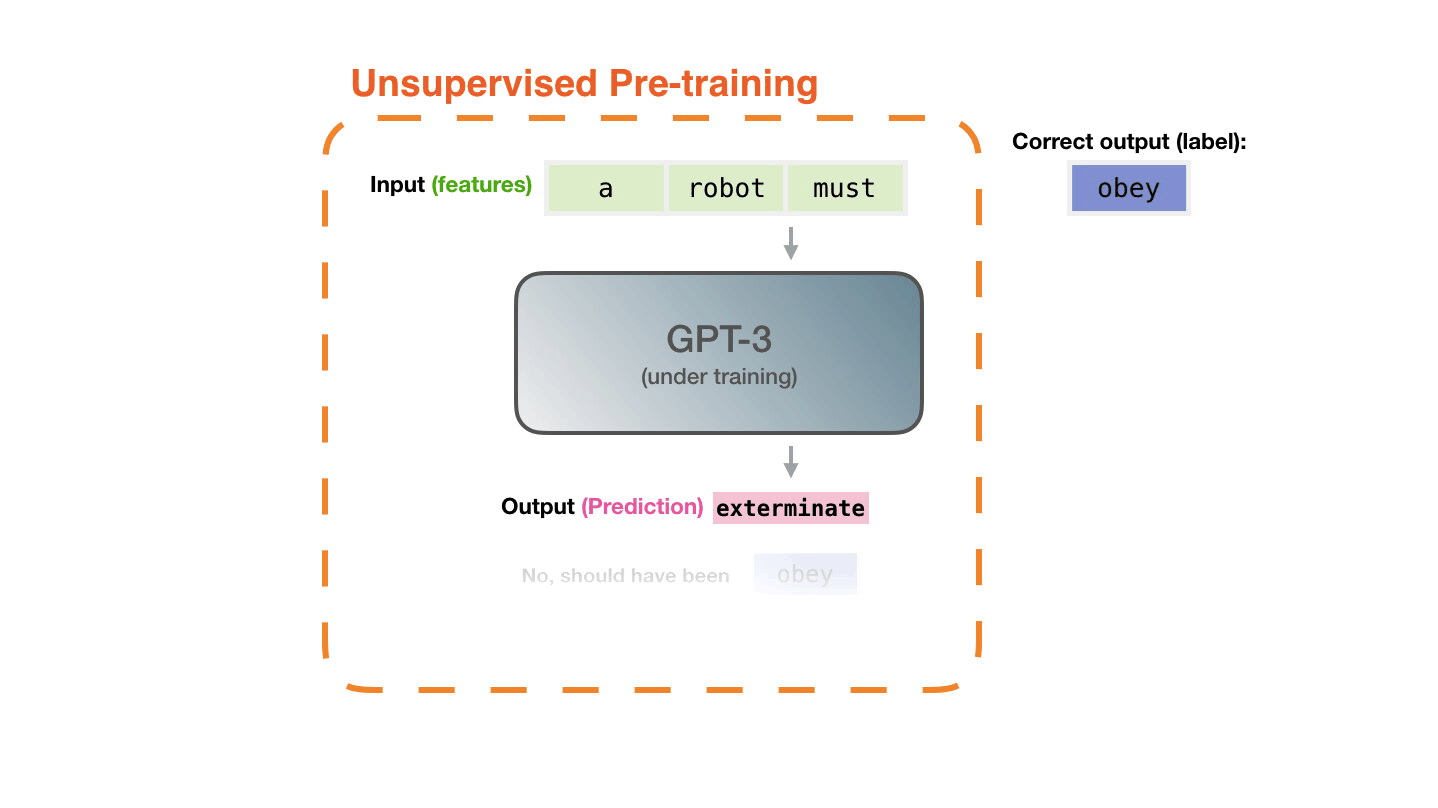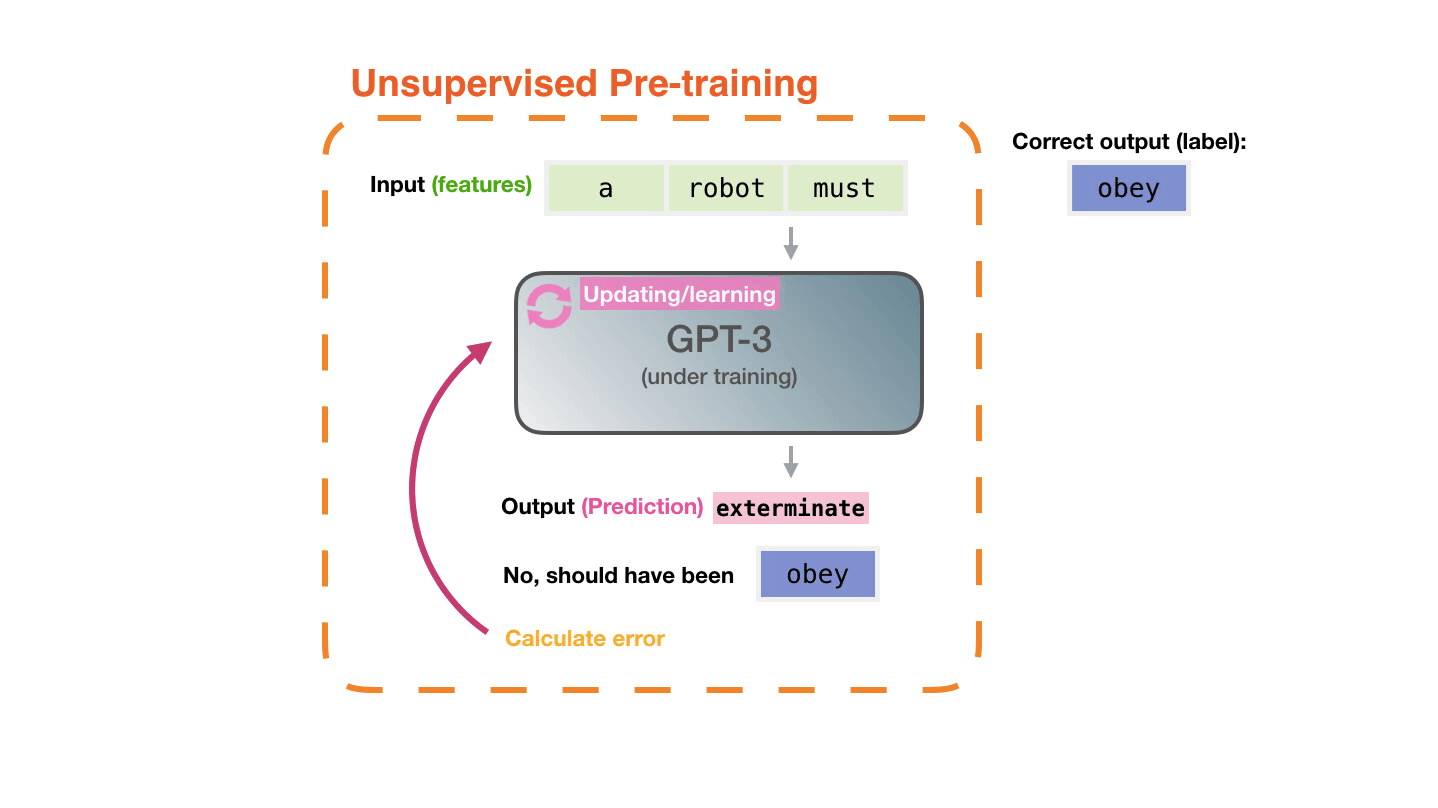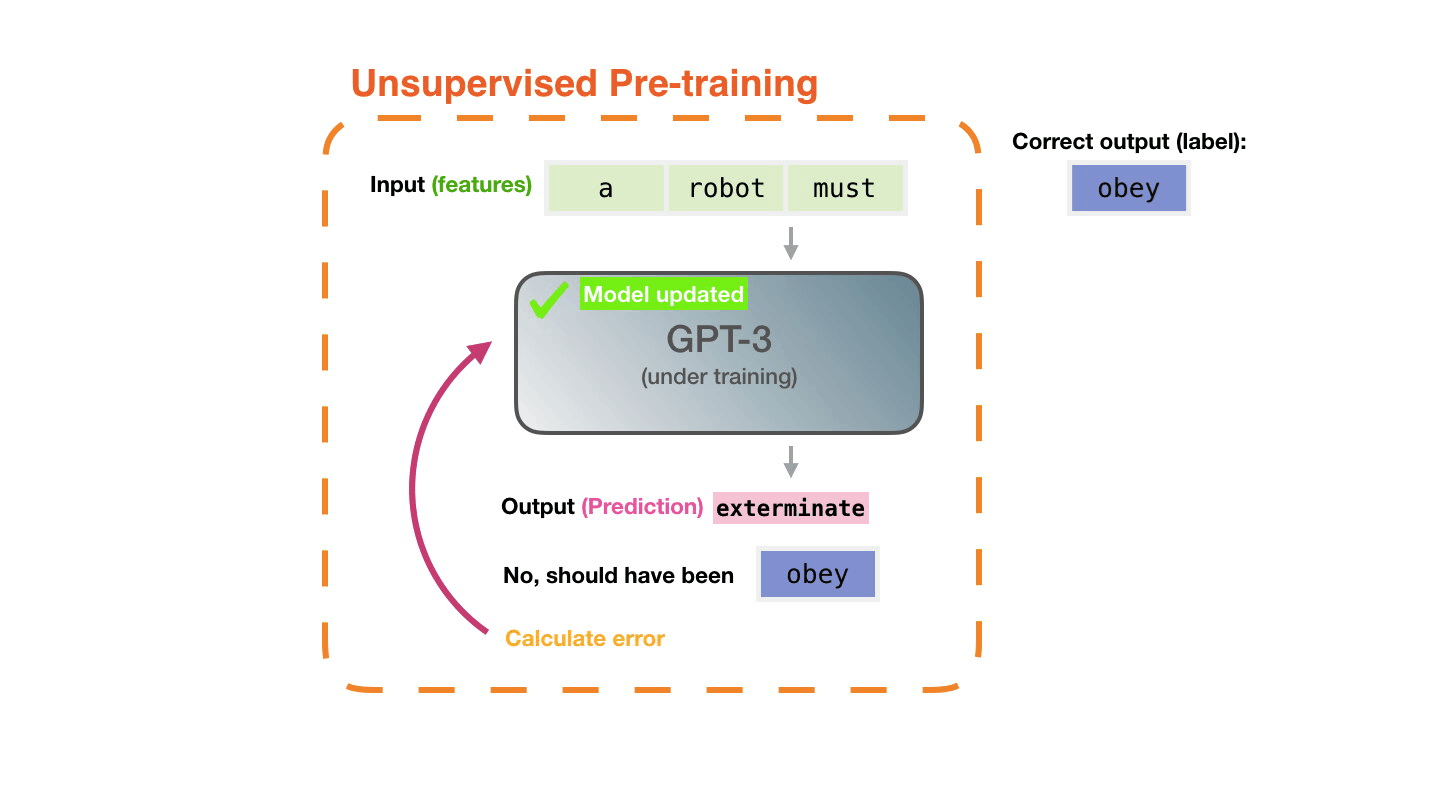
Модели представлен пример. Мы показываем ей только свойства и просим предсказать следующее слово. Предсказание модели может быть ошибочным. Мы вычисляем ошибку в предсказании и обновляем модель, чтобы в следующий раз прогноз был точнее. Это повторяется миллионы раз.
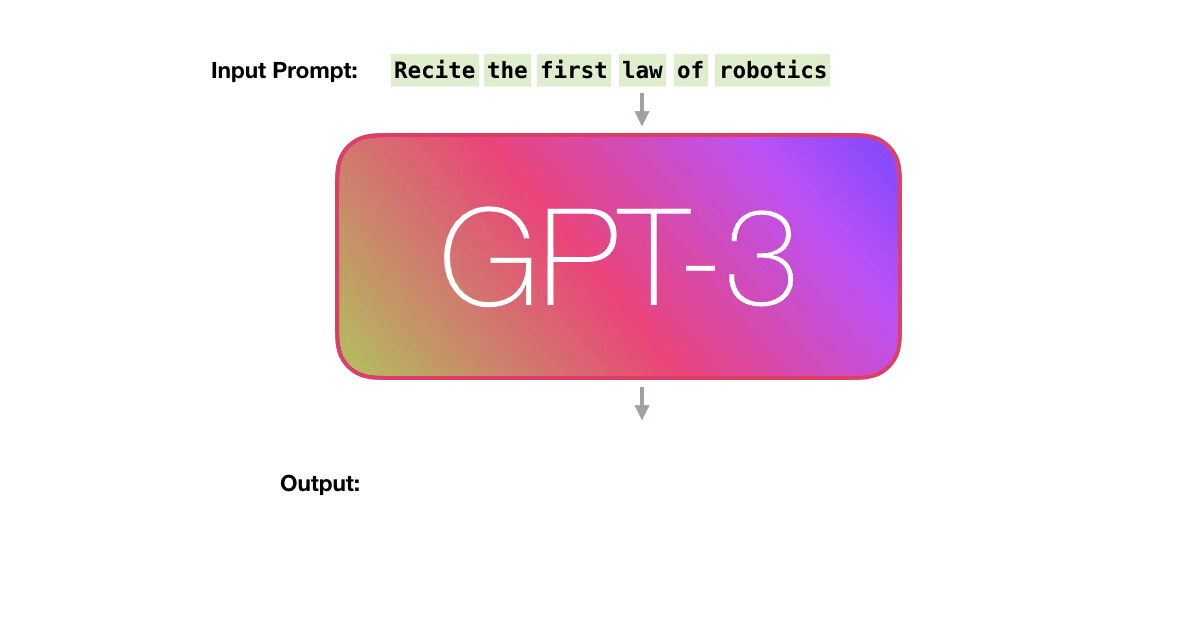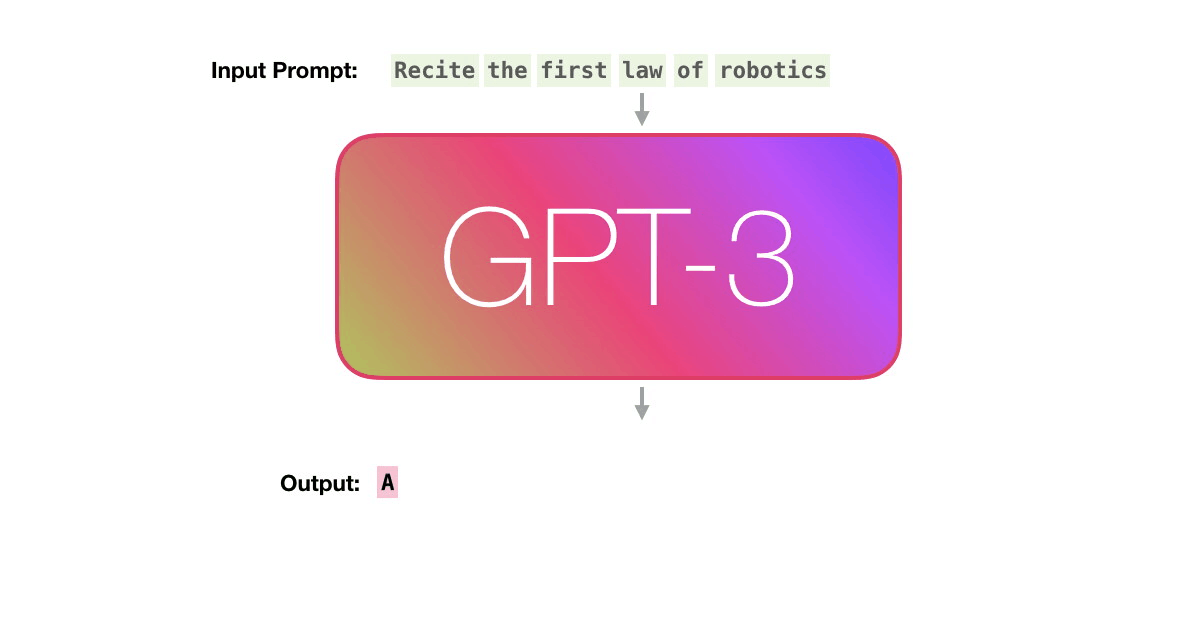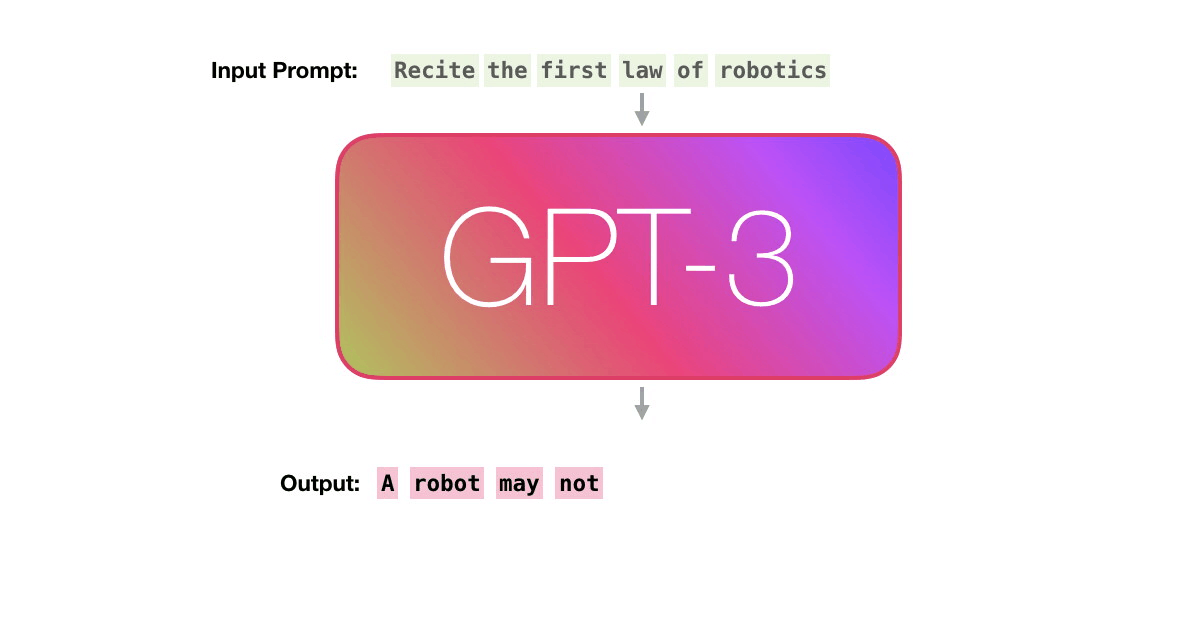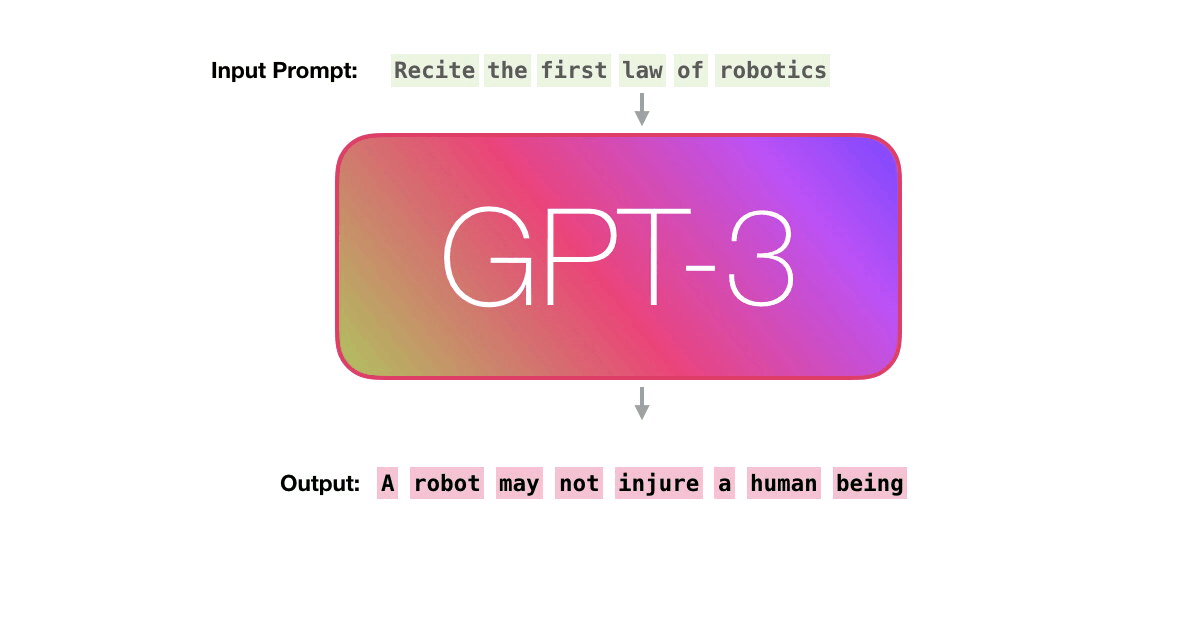
Теперь рассмотрим эти шаги более детально. GPT3 фактически генерирует выходные данные по одному токену за раз (здесь предположим, что токен — это слово).
Обратите внимание: эта статья описывает то, как работает GPT-3, а не рассказывает о нововведениях, которых пугающе много. Архитектура представляет собой модель декодера Transformer, описанную в этой статье (eng).
GPT3 внушительна. Она кодирует то, что узнаёт при обучении, в 175 миллиардов чисел, называемых параметрами. Эти числа обычно используются для расчёта того, какой токен генерировать при каждом запуске. Необученная модель начинает со случайных параметров. Обученная находит значения, приводящие к лучшим предсказаниям.
Эти числа являются частью сотен матриц внутри модели. Прогнозирование — это перемножение множества матриц. Заглянем внутрь модели, чтобы пролить свет на то, как эти параметры распределяются и используются. GPT3 имеет разрядность в 2048 токенов, это её “контекстное окно”, то есть у неё есть 2048 дорожек, обрабатывающих токены.
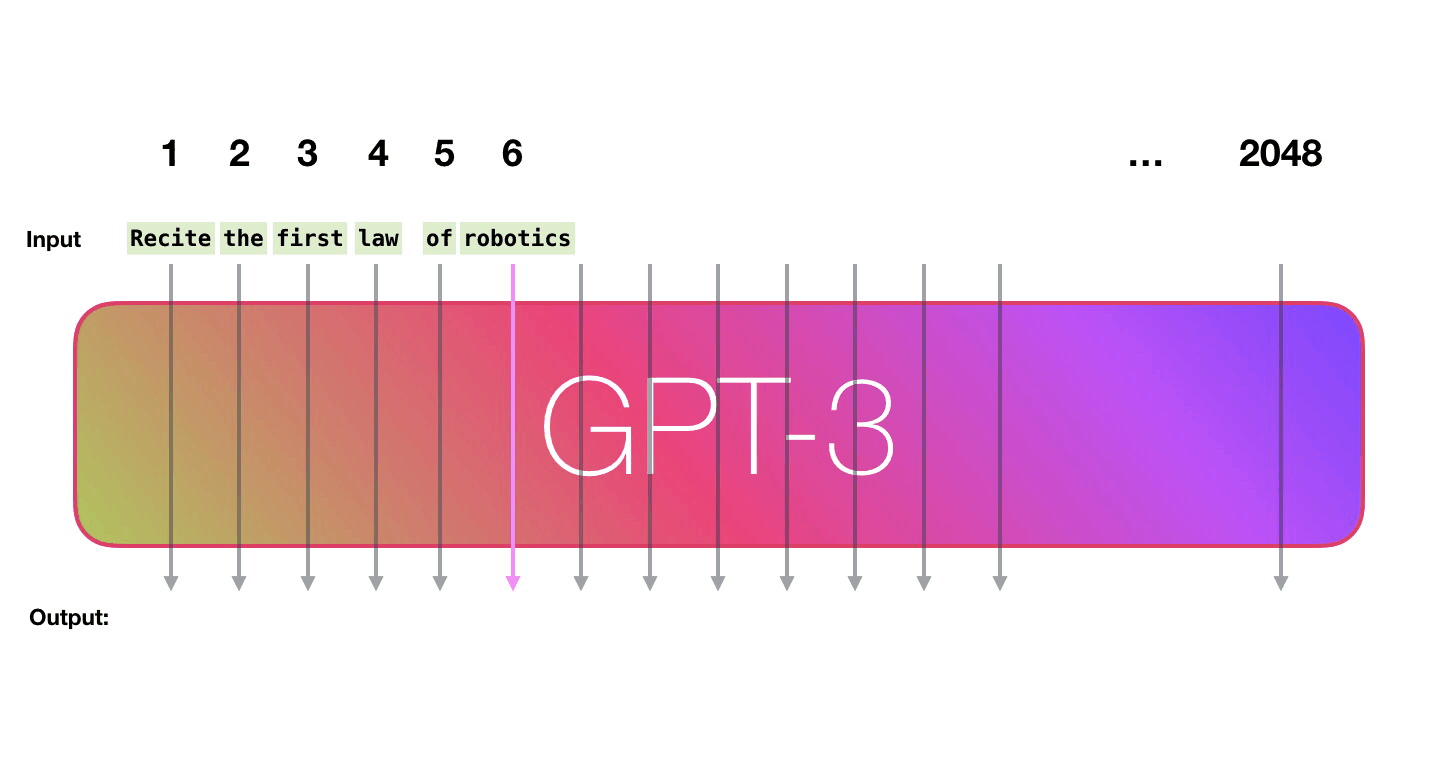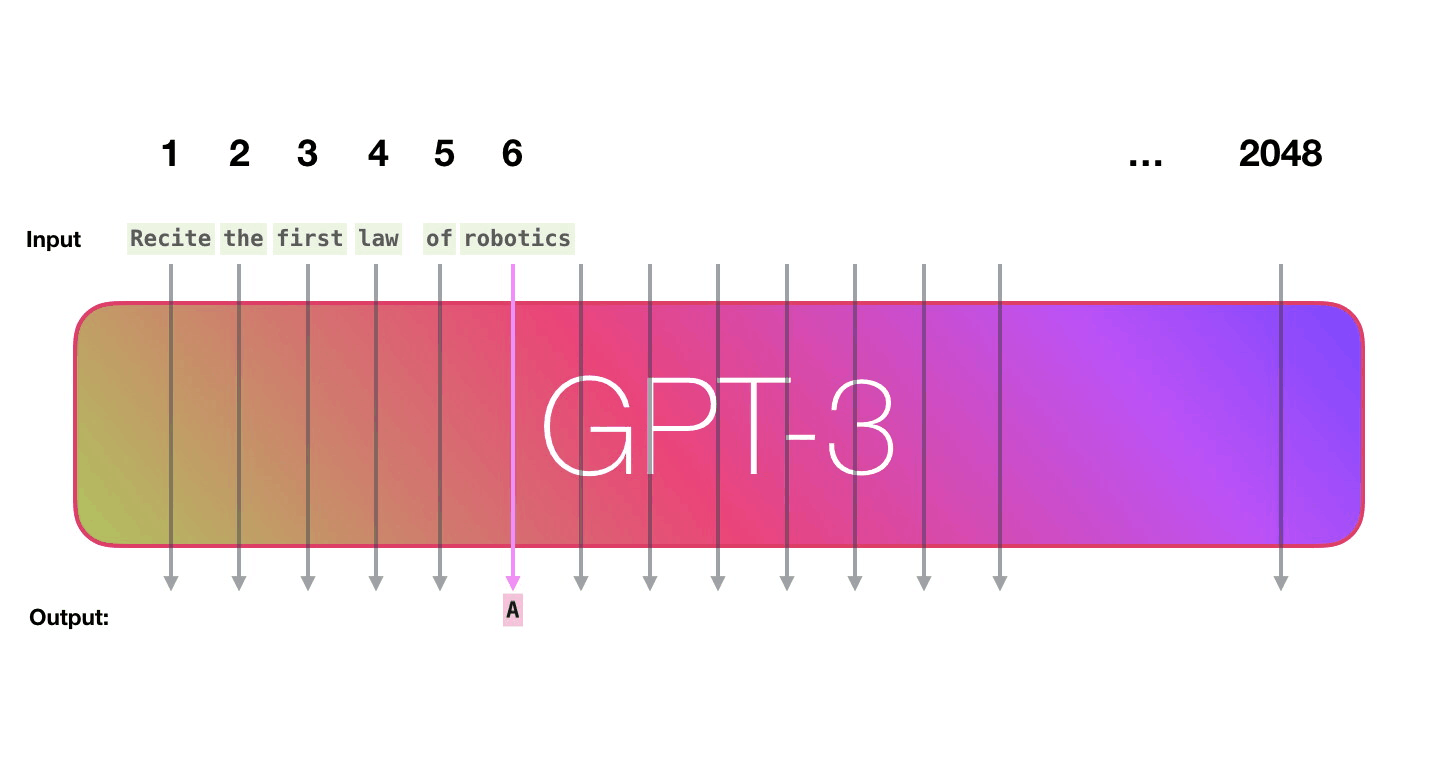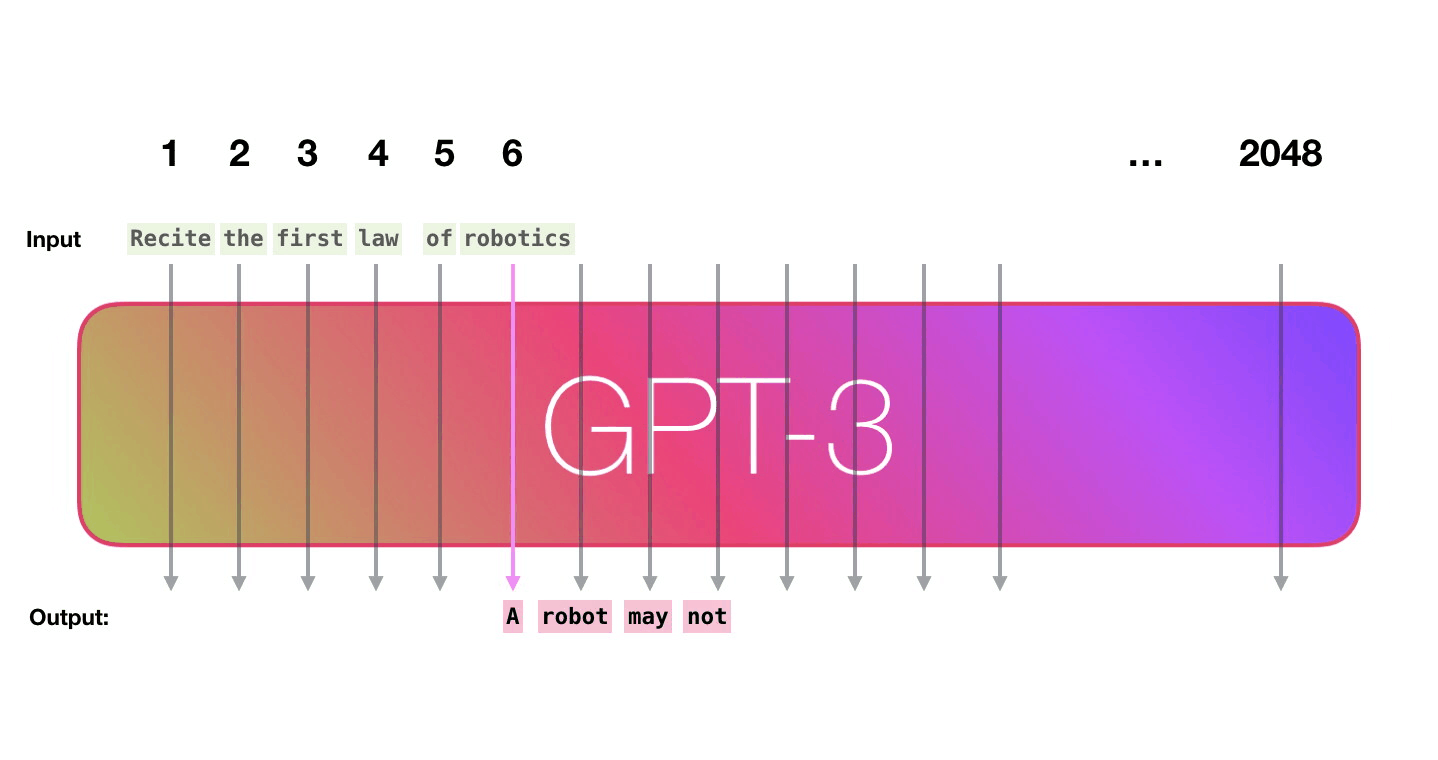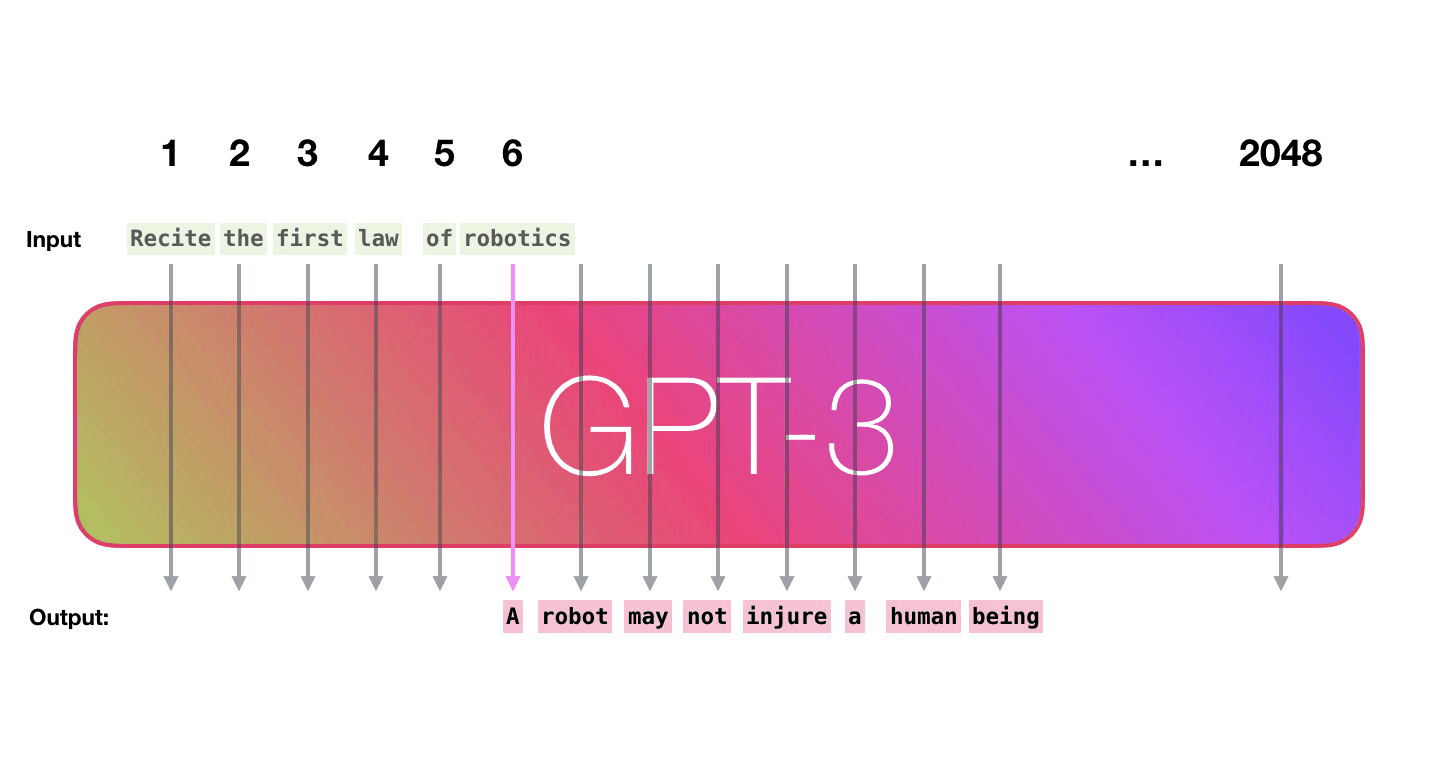
Пойдём по лиловой дорожке. Как система обрабатывает слово robotics и синтезирует A?
Общее описание шагов:
- Преобразовать слово в вектор (список чисел), представляющих слово.
- Вычислить прогноз.
- Преобразовать полученный вектор в слово.
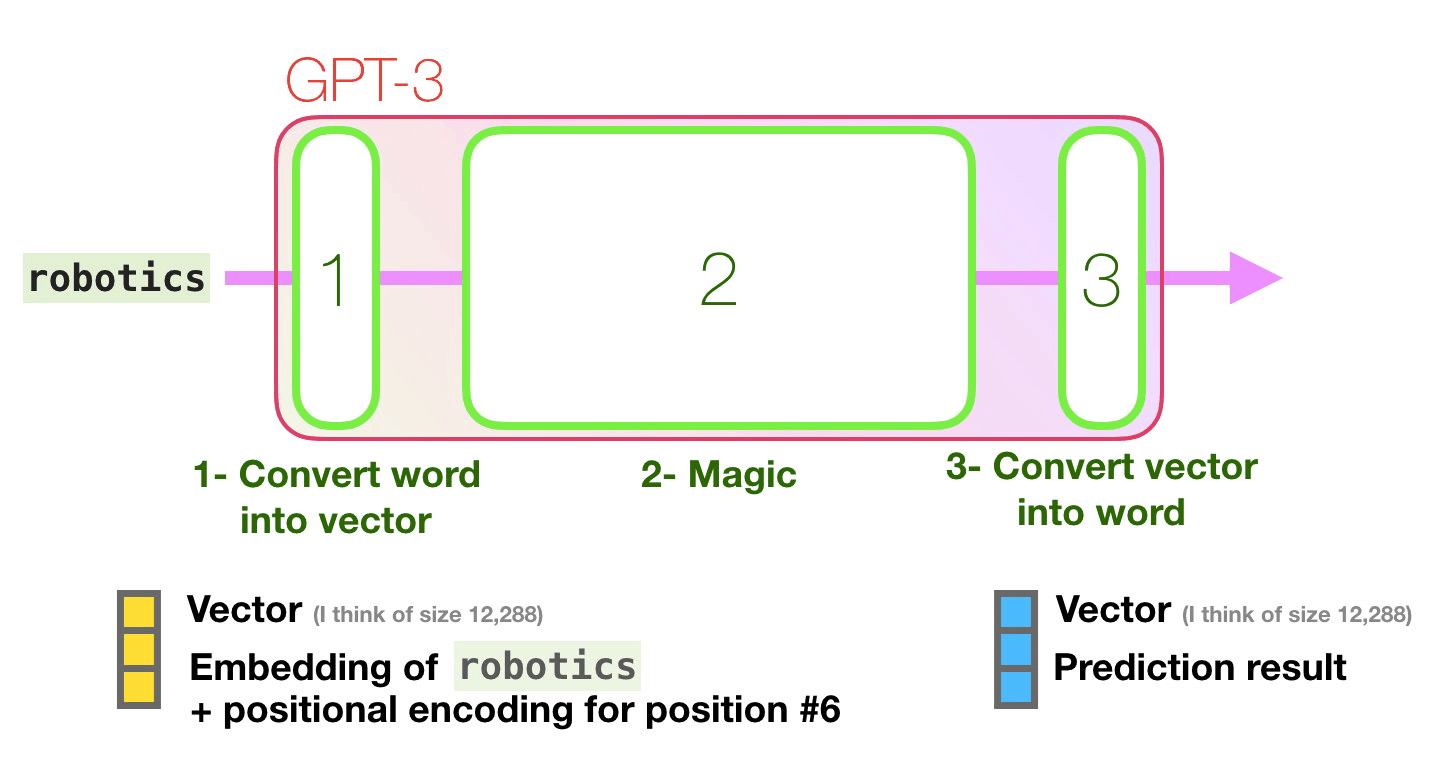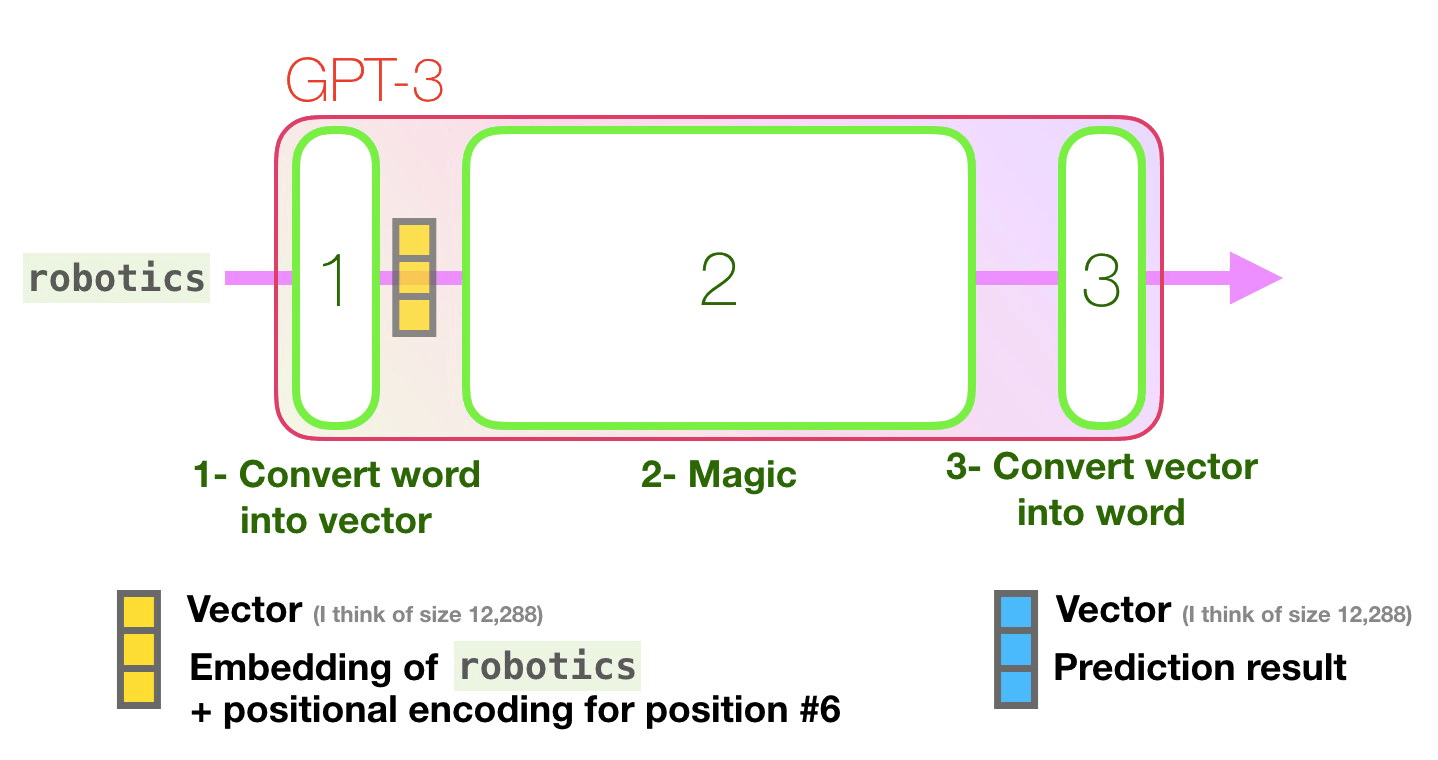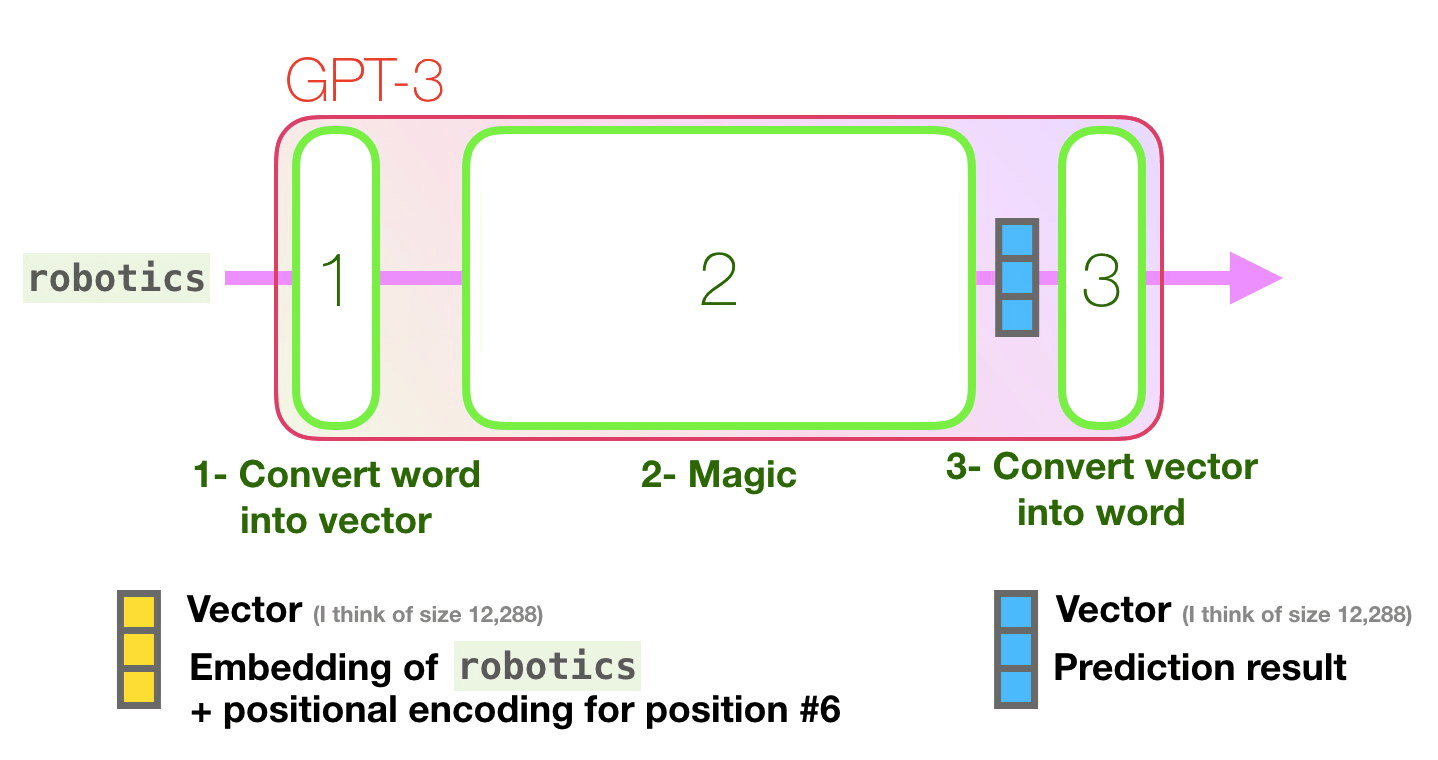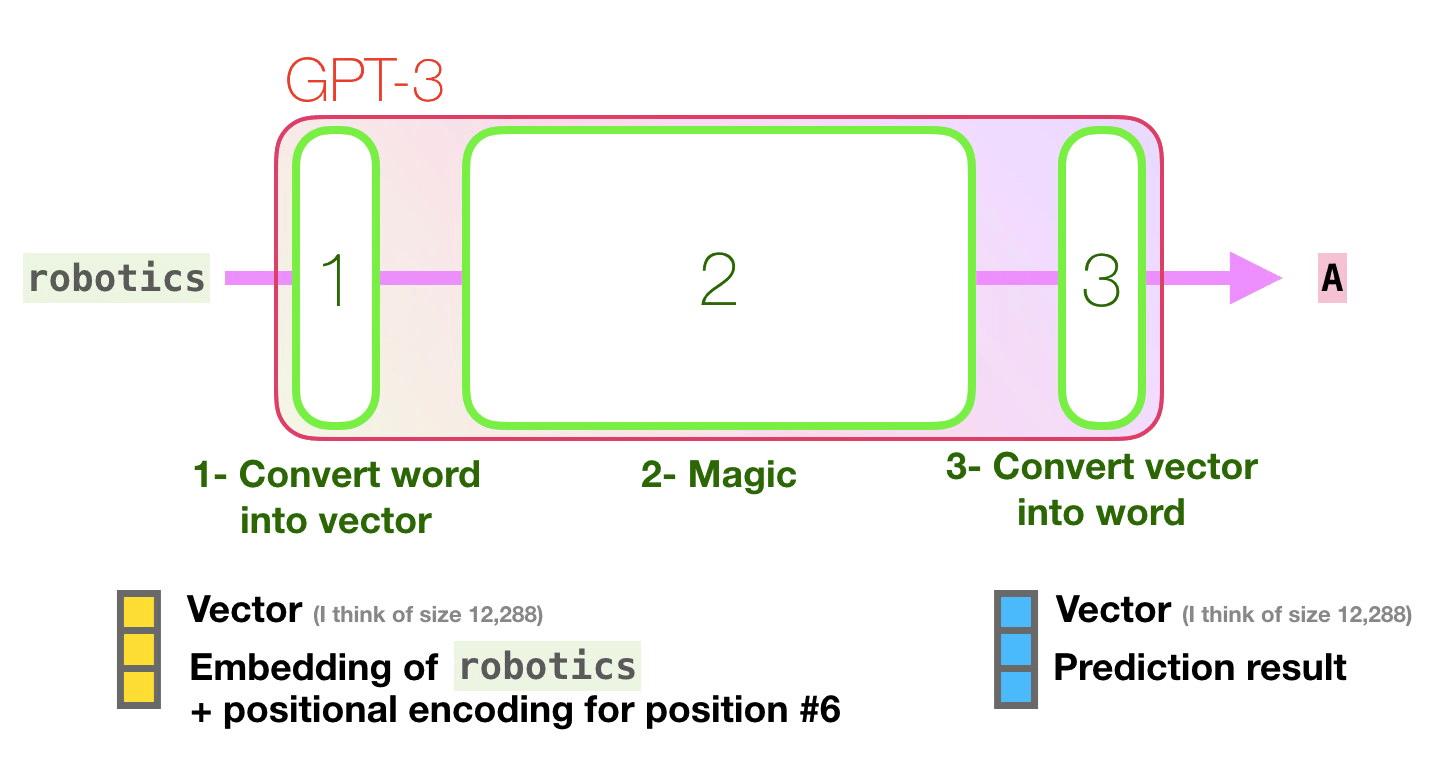
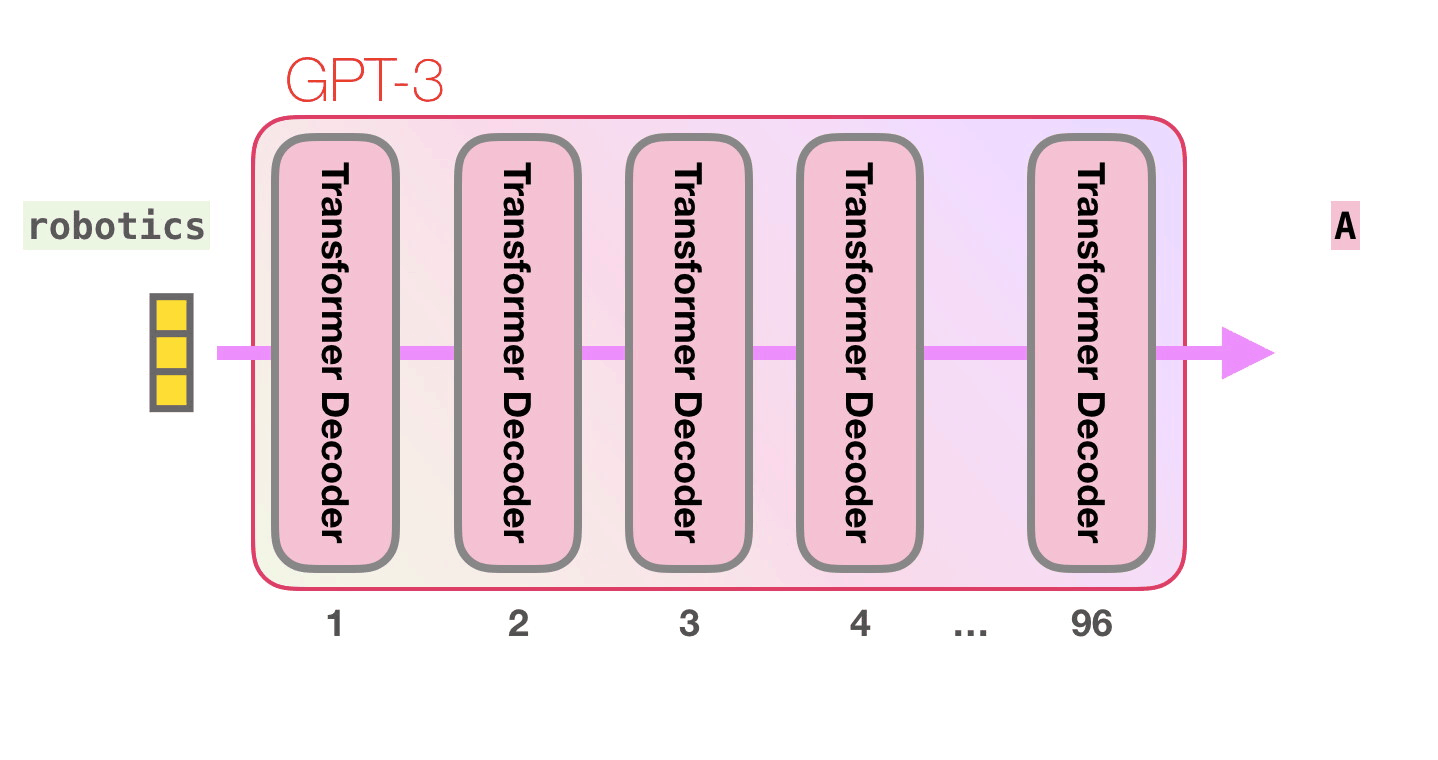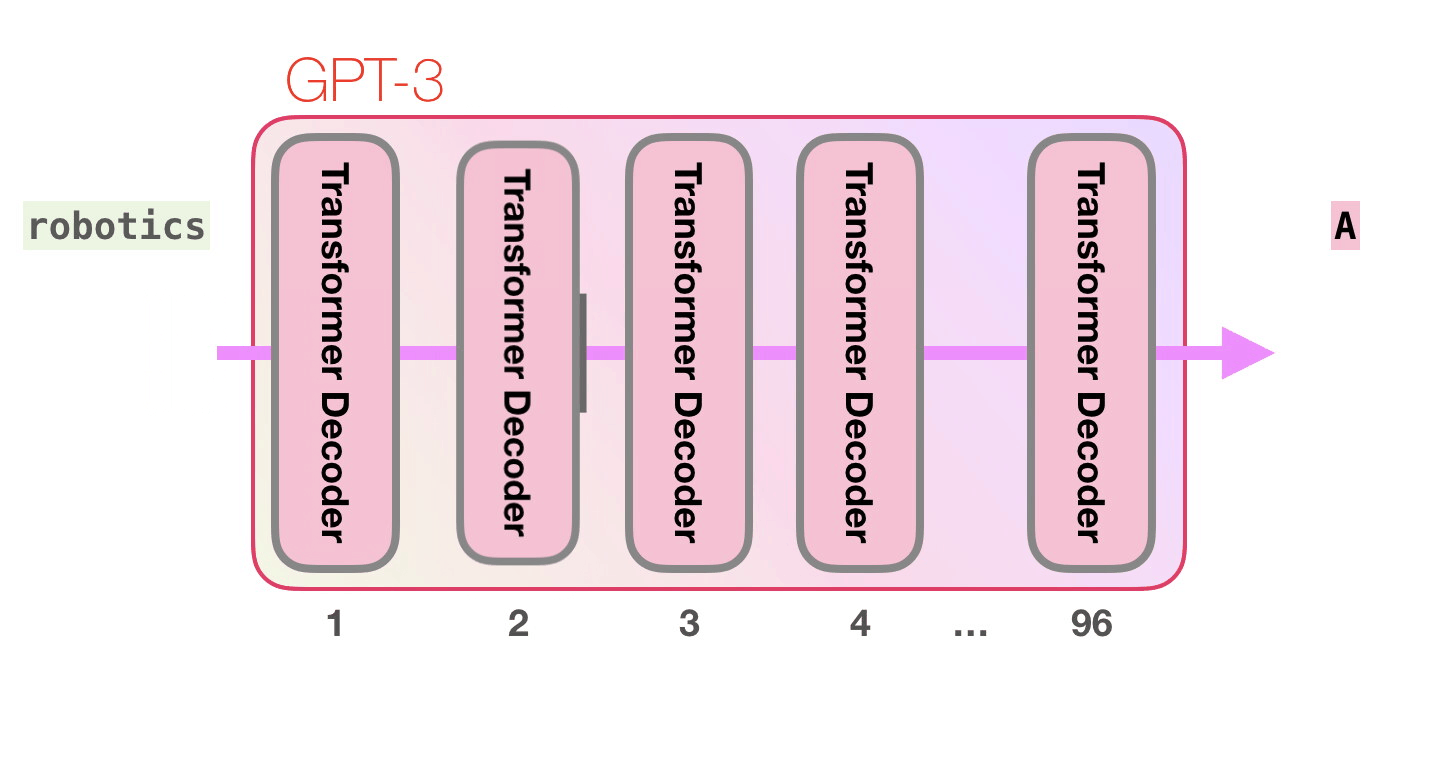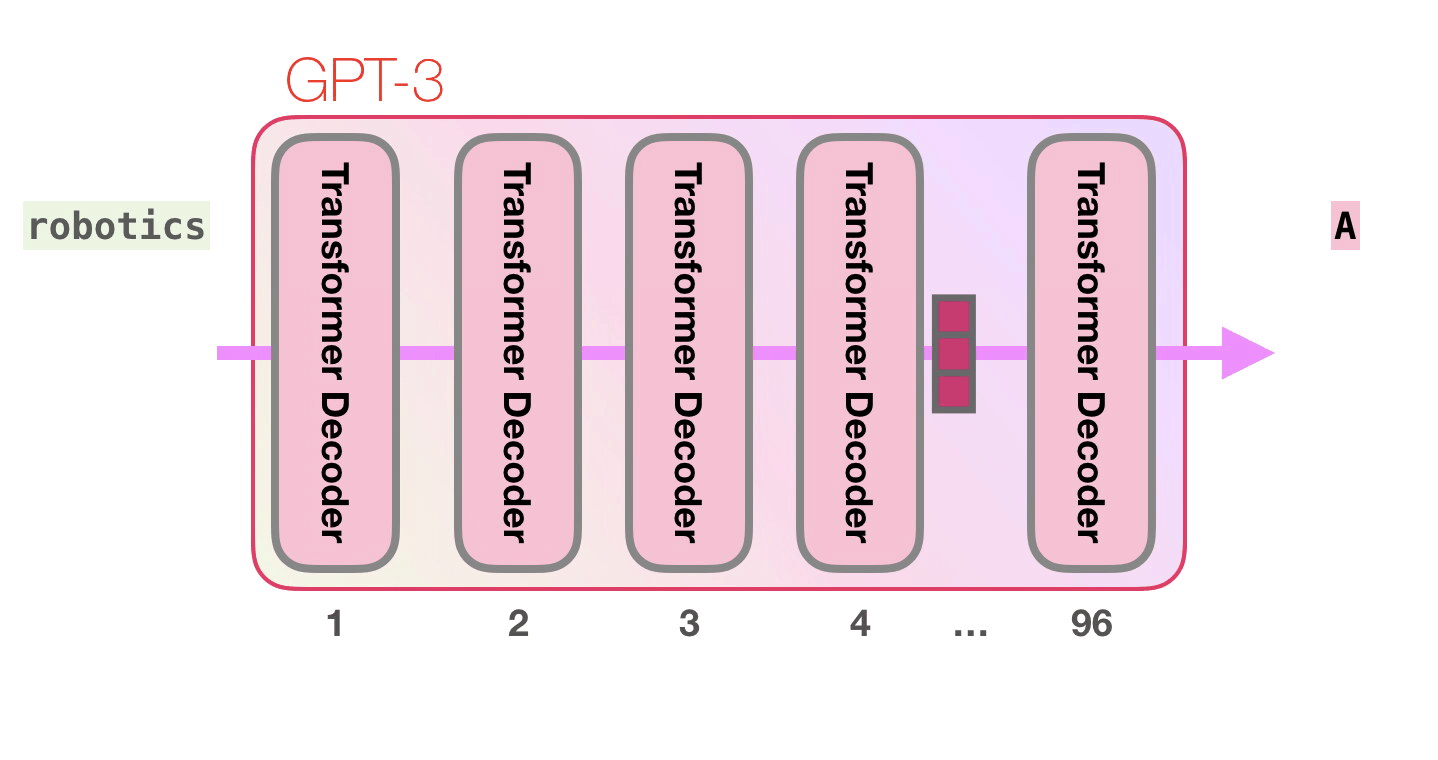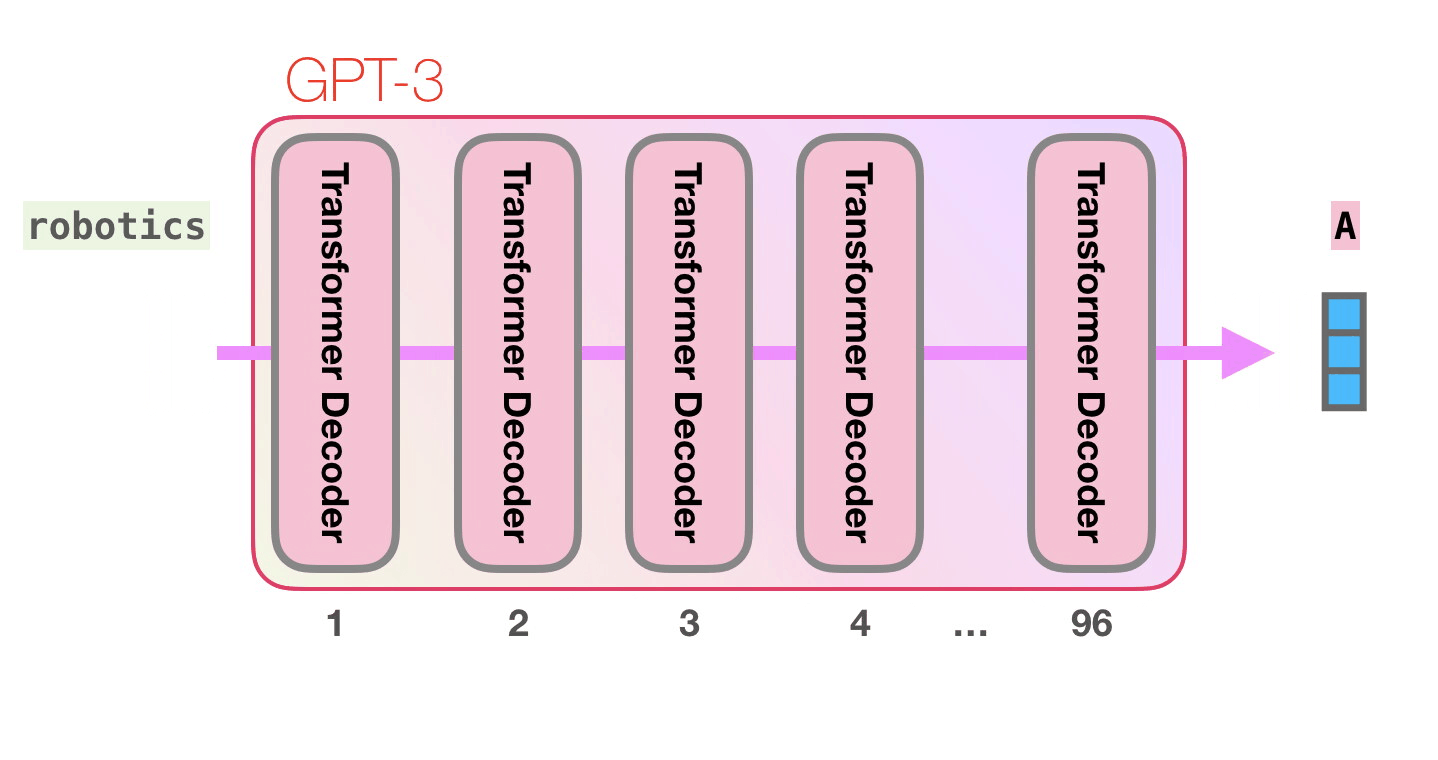
Важные вычисления GPT3 происходят внутри её стека из 96 слоёв декодера Transormer. Видите все эти слои? Это — та самая глубина в глубоком обучении.
У каждого слоя есть 1,8 миллиарда собственных параметров для вычислений, где и происходит вся магия. Высокоуровневый взгляд на процесс:
Разница с GPT2 состоит в чередовании плотных и разреженных слоёв внутреннего внимания.
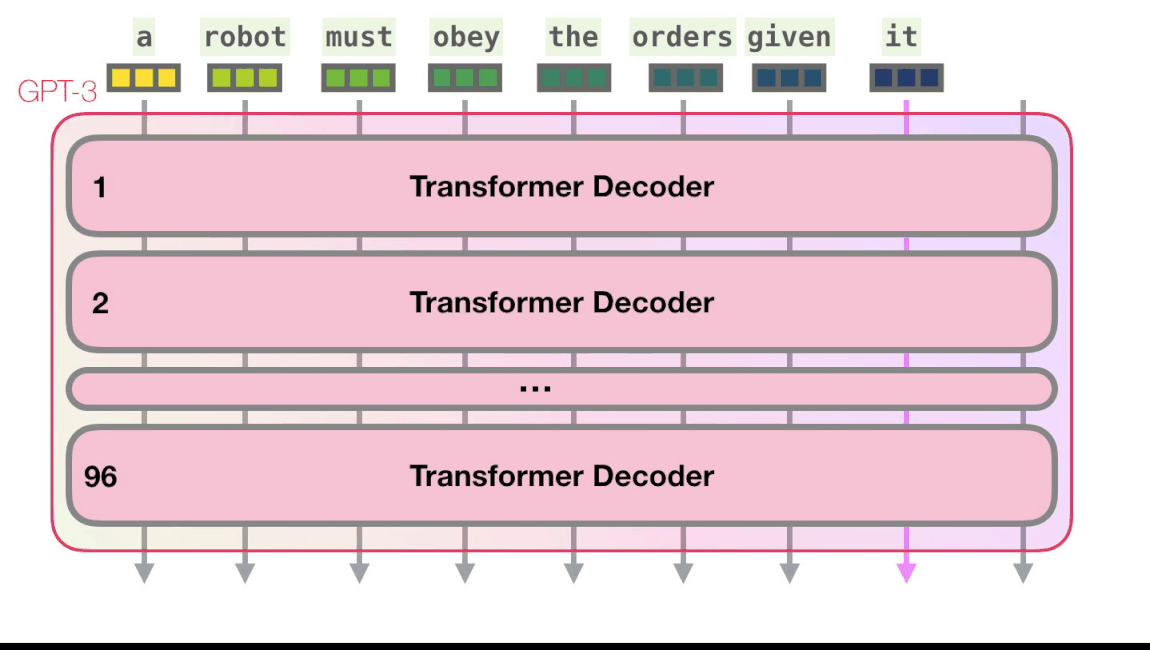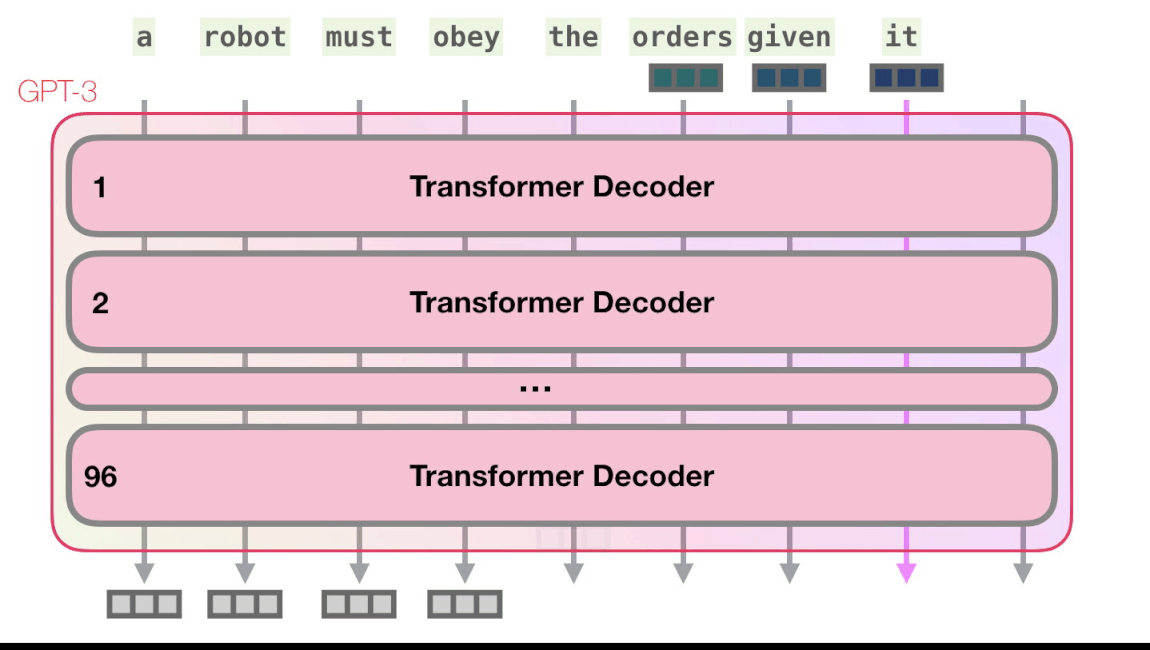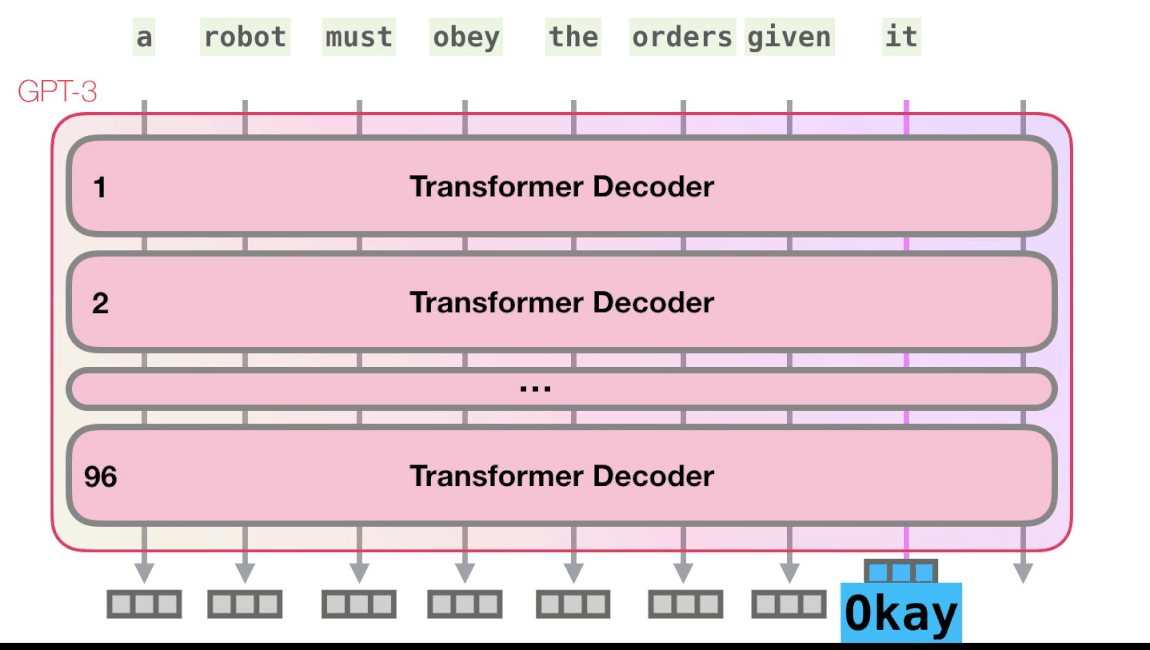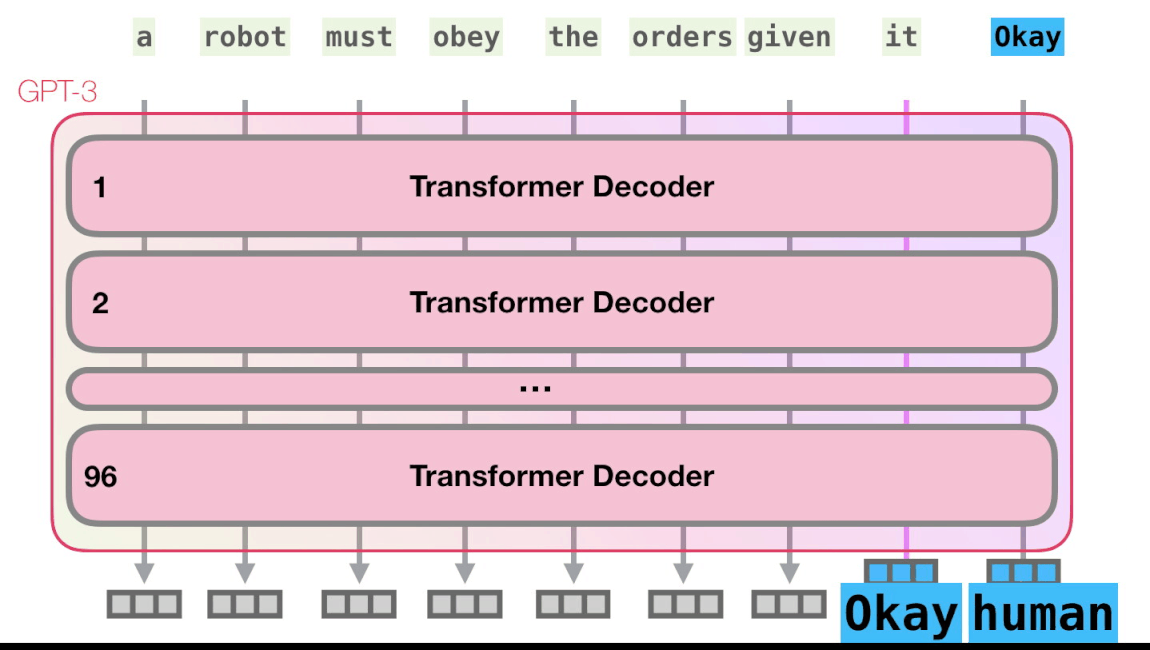
Вот рентгеновский снимок входных данных и ответа Okay human в GPT3. Обратите внимание, как каждый токен проходит через весь стек. Нас не интересуют выходные данные первых слов, но интересует вывод после ввода всех данных. Мы возвращаем каждое слово обратно в модель.
В примере генерации React, описанием будет приглашение ввода (оно отмечено зелёным), в дополнение к паре примеров описание => код. Код react сгенерирован здесь в виде розовых токенов один за другим.
Основные примеры прайминга и описания добавляются в качестве входных данных с конкретными токенами, разделяющими примеры и результаты. Затем они загружаются в модель.

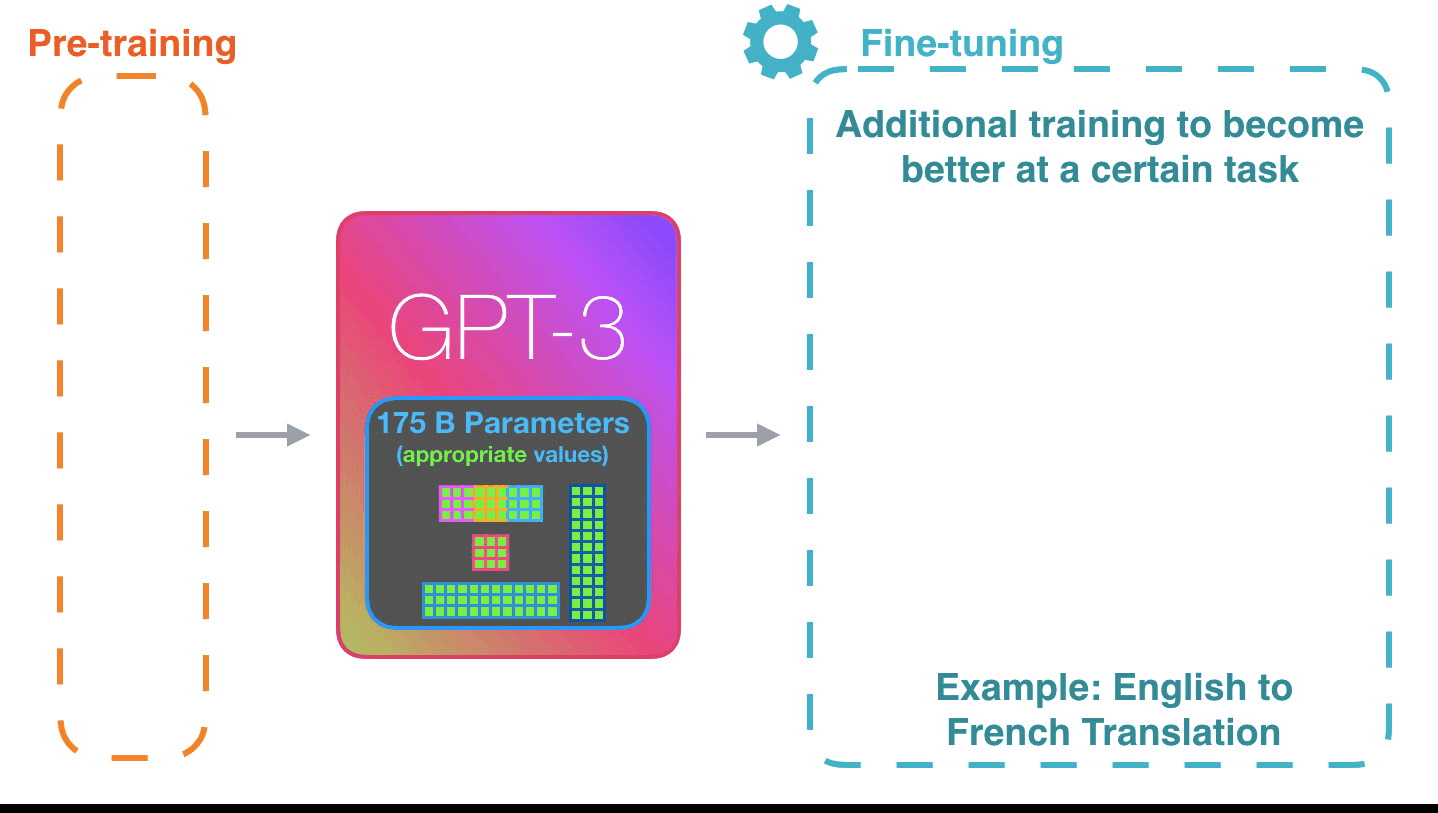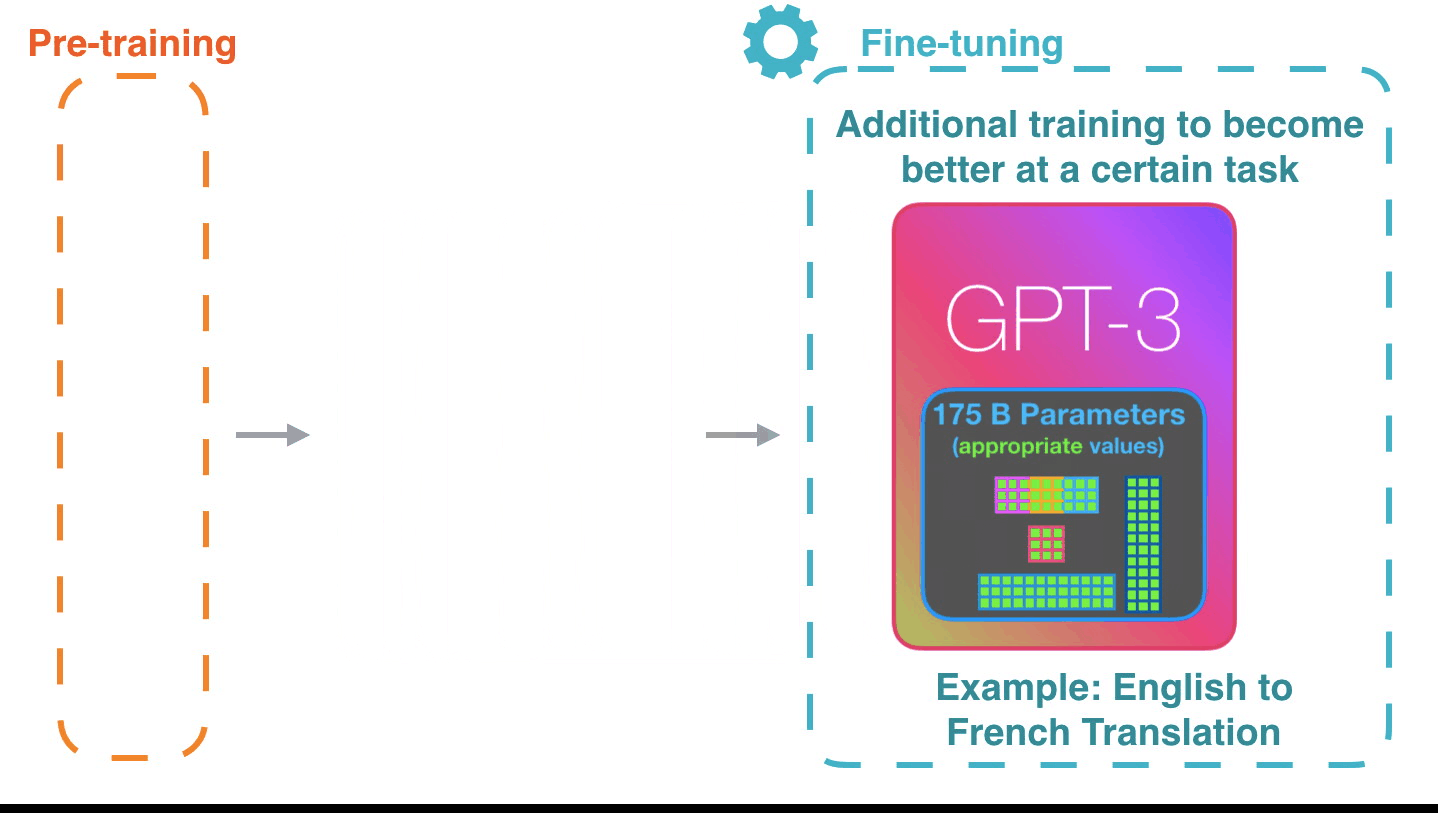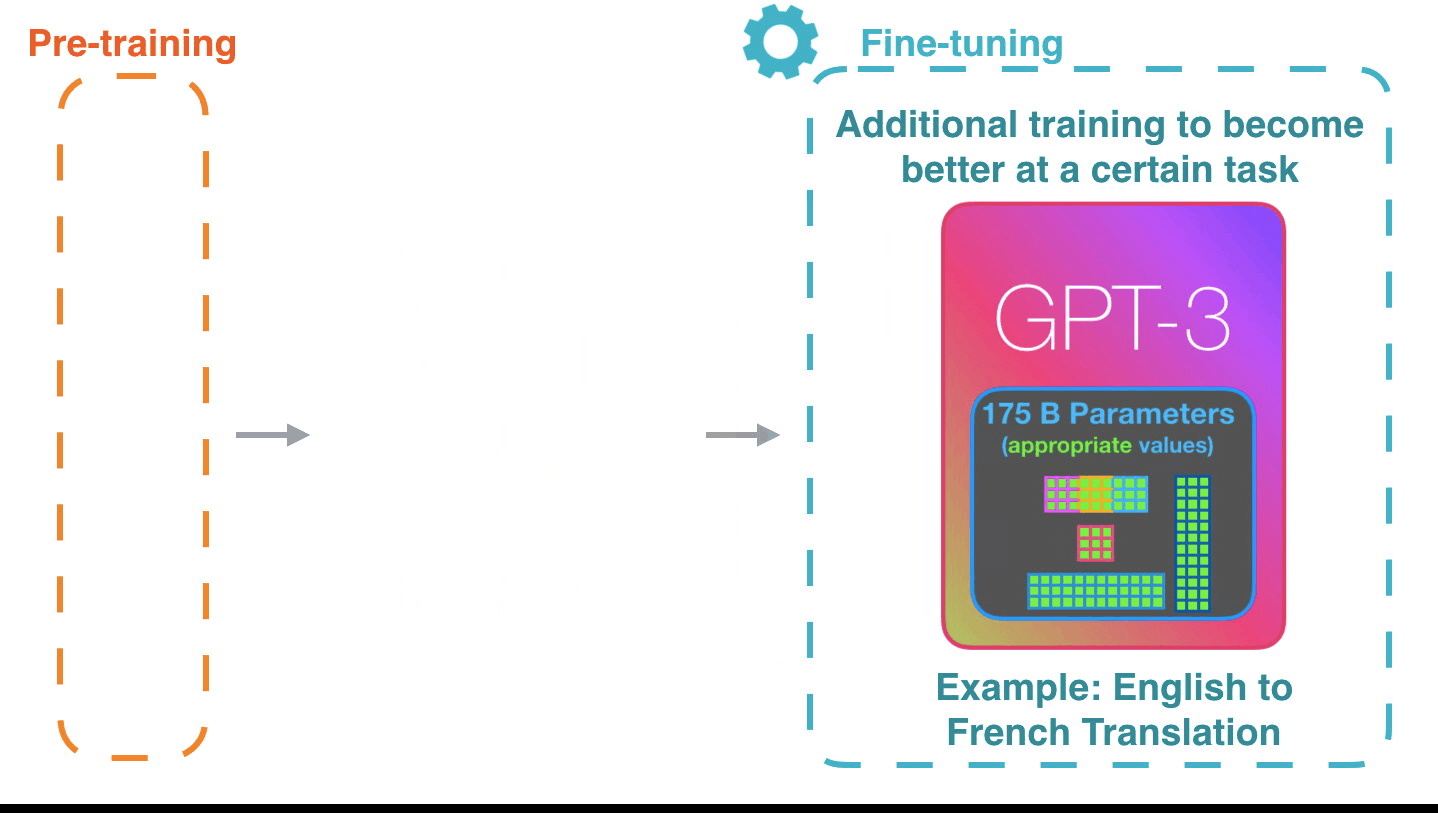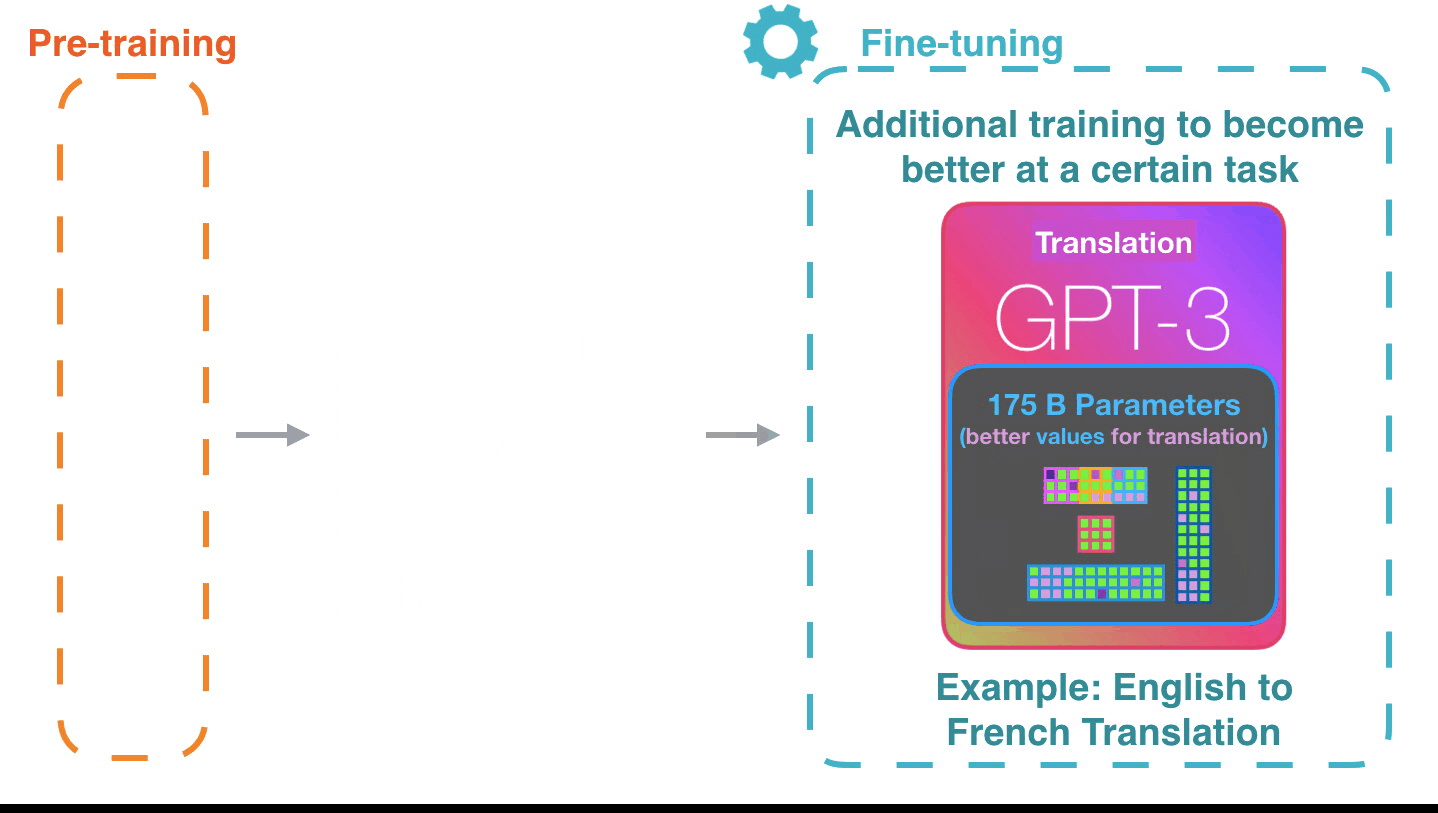
Работает действительно впечатляюще: вы просто ждёте, пока точная настройка для GPT3 развернется. Возможности обещают быть ещё более удивительными. Точная настройка фактически обновляет вес модели, делая её более подходящей для выполнения определённой задачи.
Читайте также:
- Гениально или глупо? Самая неоднозначная нейросеть
- Не используйте ID, сгенерированные базой данных для доменных сущностей
- Метод подсчёта количества решений
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Jay Alammar: How GPT3 Works — Visualizations and Animations





