
В течение последних двух лет популярность интерпретируемого языка Python, который был написан на C, резко возросла. Хоть он и является полезным языком, который стал достаточно распространён с момента своего появления, такой резкий скачок интереса обычно связывают с его фантастическими возможностями в машинном обучении и статистическом анализе. Тем не менее время не стоит на месте, и были разработаны новые языки с целью потеснить Python на этом поприще, предлагая более скоростной опыт всесторонней работы с машинным обучением. Один из наиболее многообещающих и популярных конкурентов в этом смысле — Julia.
Julia является мультипарадигмальным, статически типизированным языком общего назначения, созданным с уклоном на машинное обучение и статистику. Главным мотивирующим фактором в использовании Julia обозначена его скорость, но стоит помнить, сколькими переменными определяется одна только скорость. При этом речь не идёт о других возможностях или недостатках, присущих этому языку.
Обзор
Несмотря на то, что скорость очень важна, причём особенно важна в контексте машинного обучения, я считаю, что наряду с производительностью также важно обсудить и другие факторы. Главный вопрос, который стоит задать прежде, чем решаться покинуть Python, звучит так:
Какие недостатки есть у Julia?
Нет смысла изучать новый язык, если его недостатки перевесят единственное преимущество в производительности. У Julia есть ряд проблем, из-за которых переход на него для определённых разработчиков может показаться нецелесообразным.
Первая и, возможно, серьёзнейшая утрата при переходе с Python на Julia —
пакеты.
Несмотря на то, что у Julia есть отличные пакеты, равно как и хороший пакетный менеджер для работы с ними, их область применения далеко не такая широкая, как у Python. Многим из них существенно недостаёт документации, у других есть сложности с зависимостями, третьи запутанны и настолько фрагментированы, что вам придётся добавлять пятьдесят таких пакетов для достижения одной цели. Хоть это и очевидный недостаток, стоит отметить, что у Julia ещё нет настолько развитой династии модулей, как у Python, потому что последний существенно более взрослый язык. С течением времени эта проблема скорее всего будет решена. А если учесть, что над Julia работают отличные разработчики, и у этого языка уже есть многогранное и быстрорастущее сообщество, то долго эта проблема не просуществует. Я понимаю, почему некоторые приверженцы Julia могут указывать на “PyCall.jl” как на потенциальное её решение, но не соглашусь с такой позицией, потому что использование PyCall для всех целей будет ещё медленнее, чем использование Python. Почему бы тогда просто не остановиться на нём?
Ещё один существенный недостаток заключается в парадигме Julia. Хотя этот язык и является мультипарадигмальным и поддерживает множество обобщений, синтаксис Julia по сути статичен, т.е. по большей части код Julia будет подпадать под функциональную парадигму. Я уверен, что поклонники Lisp, R и Haskell обрадовались бы такой новости, но, глядя на список наиболее популярных языков программирования, понимаешь, почему переход на эту парадигму может оказаться серьёзным вызовом даже для опытных программистов. Так что, хоть этот факт может и не показаться недостатком для меня или некоторых других разработчиков, он может отпугнуть тех, кто не имеет к подобному языку существенного интереса.
Предполагается, что мы знакомы с Python, поэтому я не стану тратить время на разъяснения того, почему вы можете захотеть переключиться с Python на Julia. Тем не менее есть ряд недостатков Python, которые всё же стоит рассмотреть объективно, чтобы определить плюсы и минусы потенциального перехода с этого языка на Julia.
Во-первых, мы все наверняка слышали, что Python является интерпретируемым языком. И хотя для обхода этого недостатка определённо есть решения, вроде различных инструментов для получения скомпилированного исполняемого файла и повышенной скорости, ничто из этого не является гарантированным способом сделать пакет быстрее или распространить ПО. Хоть я и не большой приверженец лозунга “Python == ‘slow’”, но недостаток скорости этого языка отрицать невозможно. К счастью, интерпретация Python через C ставит его в уникальное положение, в котором он может использоваться для управления C-кодом и его вызова из интерфейса высокого уровня.
Это, конечно, большой плюс Python, но не вся работа в области науки о данных выполняется в модулях, уже написанных на C, и иногда добавочный слой заголовка Python.h может также понизить скорость вычислений, загубив высокую производительность C.
Вам решать
Ещё раз повторюсь, что несмотря на важность скорости, она не определяет всё. Есть много существенных преимуществ использования как Python, так и Julia, некоторые из которых субъективны. Например, я не терплю синтаксис отступов в Python, поэтому работа в Julia, где функции оканчиваются знаками ограничения, будет для меня субъективным преимуществом.
def func:
print("function body")
function func
println("I can put syntax here")
println("Here")
println("Or here, without any errors.")
endЯ бы также хотел отметить полиморфную диспетчеризацию Julia и более простой синтаксис у Python. Все эти замечания призваны обратить ваше внимание на то, что хоть производительность и важна, множество других возможностей могут послужить перевешивающим фактором при выборе предпочтительного языка. Кроме того, вам следует подбирать конкретный язык для текущего сценария, поскольку есть задачи для которых отдельные языки подойдут лучше.
Ещё один интересный момент при работе с Julia — это идея использовать Python в качестве интерфейса Julia, а не C. Это даст нам возможность ускорить написание быстрого кода, сохраняя при этом производительность. По этому случаю я даже создал пакет, дающий такую возможность, который вы можете установить через PyPi.
sudo pip3 install TopLoader
Ваш выбор языка не обязательно должен быть двоичным. Что хорошо в Julia, так это возможность продолжать использовать Python и применять при этом Julia, как в случае со Scala, учитывая преимущества Julia в работе с большими данными и точность в числах с плавающей точкой. В этом языке даже есть типы BigInt и BigFloat для обработки достаточно крупных чисел.
Тесты скорости
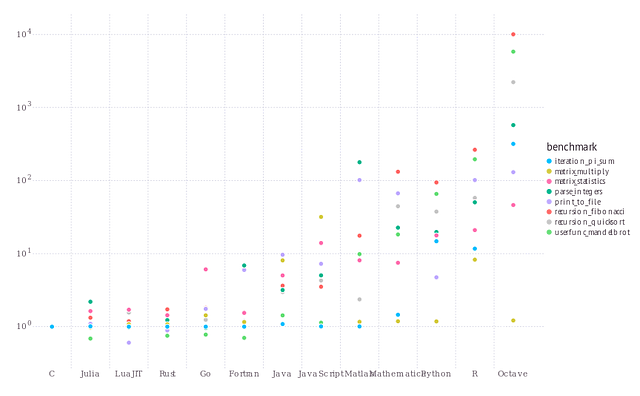
Для демонстрации фактической скорости я привёл бенчмарки Julia. Как можно видеть из данного простого примера, время задержки Julia близко к Go, но при этом он остаётся более последовательным. Также очень интересно, что в очень редких случаях Julia опережает по производительности даже C и Rust. Это, конечно, отличные показатели, но главное здесь не в сравнении Julia с C, а в сравнении его именно с Python.
Настройка теста
Для поддержания последовательности между двумя сравнениями я буду использовать синтаксические выражения Julia, чтобы приблизить выполнение типизации к Python.
Для моего теста итерирования я создал в Julia следующую функцию:
function LinearRegression(x,y)
# a = ((∑y)(∑x^2)-(∑x)(∑xy)) / (n(∑x^2) - (∑x)^2)
# b = (x(∑xy) - (∑x)(∑y)) / n(∑x^2) - (∑x)^2
if length(x) != length(y)
throw(ArgumentError("The array shape does not match!"))
end
# Получаем суммы:
Σx = sum(x)
Σy = sum(y)
# Скалярное произведение x и y
xy = x .* y
# ∑скалярного произведения x и y
Σxy = sum(xy)
# Скалярный квадрат x
x2 = x .^ 2
# ∑скалярного квадрата x
Σx2 = sum(x2)
# n = размер выборки
n = length(x)
# Вычисление a
a = (((Σy) * (Σx2)) - ((Σx * (Σxy)))) / ((n * (Σx2))-(Σx^2))
# Вычисление b
b = ((n*(Σxy)) - (Σx * Σy)) / ((n * (Σx2)) - (Σx ^ 2))
# Часть, являющаяся суперструктурной:
predict(xt) = (xt = [i = a + (b * i) for i in xt])
(test)->(a;b;predict)
endАналогичным образом для достижения той же цели я создал класс в Python:
class LinearRegression:
def __init__(self,x,y):
# a = ((∑y)(∑x^2)-(∑x)(∑xy)) / (n(∑x^2) - (∑x)^2)
# b = (x(∑xy) - (∑x)(∑y)) / n(∑x^2) - (∑x)^2
if len(x) != len(y):
pass
# Получение сумм:
Σx = sum(x)
Σy = sum(y)
# Скалярное произведение x и y
xy = dot(x,y)
# ∑скалярного произведения x и y
Σxy = sum(xy)
# Скалярный квадрат x
x2 = sq(x)
# ∑скалярного квадрата x
Σx2 = sum(x2)
# n = размер выборки
n = len(x)
# Вычисление a
self.a = (((Σy) * (Σx2)) - ((Σx * (Σxy)))) / ((n * (Σx2))-(Σx**2))
# Вычисление b
self.b = ((n*(Σxy)) - (Σx * Σy)) / ((n * (Σx2)) - (Σx ** 2))
# Часть, являющаяся суперструктурной:
def predict(self,xt):
xt = [self.a + (self.b * i) for i in xt]
return(xt)Вы можете заметить, что я использовал dot() и sq(), чтобы заменить .* для поэлементного умножения и .^ для поэлементного возведения в квадрат. Вот эти функции:
def dot(x,y):
lst = []
for i,w in zip(x,y):
lst.append(i * w)
return(lst)
def sq(x):
x = [c ** 2 for c in x]
return(x)Данные
Для своих данных я сгенерировал в Julia DataFrame размерностью 500 000 следующим образом:

Я также сделал тестовый DataFrame размерностью 600 000:
Затем я сохранил эти DataFrame и прочитал их в Python с помощью Pandas:

Тайминги
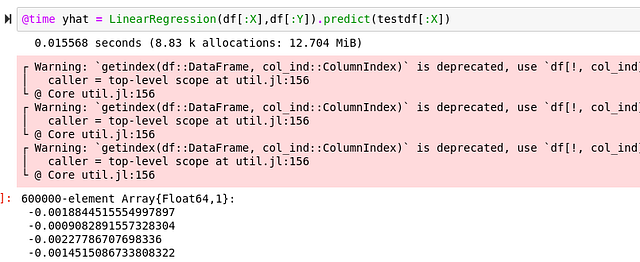
Для получения таймингов результатов Python я, конечно же, буду использовать магическую команду IPython%timeit. А для Julia, как вы могли ожидать, я буду использовать макрос @time. Вот результаты:
Julia
Python

Хоть это и отличное сравнение, при котором Julia определённо справилась с вычислением на 30 процентов быстрее, я хочу
провести испытание при высокой нагрузке.
Давайте попробуем размерность 10 000 000.
Julia
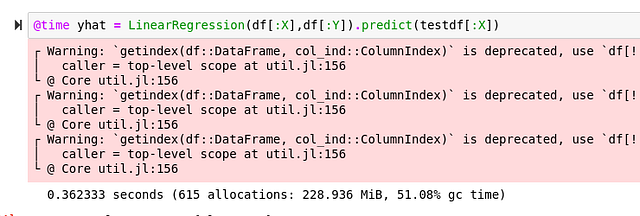
Python

Прощай, Python.
Заключение
Несмотря на то, что изначально Python выглядел достаточно впечатляюще на фоне Julia, становится немного грустно от того, насколько Julia опередил его в реальном примере машинного обучения. Я думаю, это также отлично подтверждает сказанное ранее о том, что Julia невероятно полезна в обработке именно больших данных. Лично для меня этот тест по меньшей мере доказал одну вещь, а именно то, что Julia вполне имеет право на место в мире машинного обучения. Даже если этот язык и не заменит Python, он определённо сможет занять место Scala и многих других аналогичных языков.
Julia имеет свои недостатки и всё ещё развивается, но его производительность уже при нём. Возможно, в мире машинного обучения никогда и не настанет время избавляться от Python , но при этом я не вижу серьёзных поводов не начать изучать Julia. К счастью, если вы уже знакомы с Python, то изучение Julia будет относительно простым, поскольку их синтаксис во многом схож. Возможно, вы откроете для себя и другие его преимущества. Как бы то ни было, Julia в мире машинного обучения ждёт удивительное будущее. Думаю, что любой аналитик данных, заинтересованный в расширении горизонтов знаний, должен ознакомиться с этим языком, а может даже принять участие в его развитии.
Читайте также:
- Сможет ли Julia занять место рядом с Python
- 4 ситуации из жизни лямбда-функций в Python
- Учимся писать строки документации в Python
Перевод статьи Emmett Boudreau: Should You Jump Python’s Ship And Move To Julia?





