
В последнее время, когда я работал с OpenCV, мне пришла в голову идея написать фреймворк для преобразования изображений. Такое приложение будет полезно каждый день и с ним будет просто работать. Потом как-то меня попросили оцифровать чек за топливо как основание для оформления претензии. Я делал такое и раньше, брал для этого одно из множества приложений, которые можно скачать с Playstore, но в этот раз у меня в голове поселился вопрос “почему я не делаю это своими силами?”. Ведь в целом, это всего лишь захват области документа с фотографии или изображения. Ну и ну!
Я сразу же увидел идею для нового проекта: сделать свой собственный сканер документов. И раз в OpenCV есть все эти функции по обработке изображений, то я решил взять его в качестве инструмента. Так я и приступил к созданию своего собственного сканера документов при помощи машинного зрения, OpenCV и Python.
Давайте перейдём к делу без долгих предисловий. Для начала я составил список основных этапов обработки. Вот они:
- “Прочитать” фотографию или изображение: если размеры изображения большие, вы можете выбрать уменьшить его в масштабе, чтобы обработать быстро или же изменить размер прямо в текущем окне.
- Идентифицировать границы: чтобы сделать это, нам может понадобиться конвертировать изображение в серое для уменьшения цветового шума. Чтобы убрать любой высокочастотный шум, мы слегка размоем изображение. Это поможет дальше определить контуры.
- Найти границы документа в изображении: это выявит нужную нам область в изображении. На этом этапе мы сможем увидеть контур своего документа.
- Идентифицировать и получить границы документа: в этой части больше всего программирования, а мы будем соотносить каждую пару координат с ближайшим углом и рассчитаем размеры документа.
- Применить перспективное преобразование: чтобы получить полную картинку сверху донизу, так сказать, обзор документа “с высоты птичьего полёта”, мы будем переводить полученную интересующую нас область в нужную перспективу.
- Финальные шаги: мы подготовим изображение к итоговому выводу для пользователя. Этого шага может и не быть, вам решать, как вы хотите видеть свой документ. А может вы выберете применить любое преобразование, как, например, черно-белое или увеличение контраста.
Давайте перейдём к практике по каждому пункту. Я добавил куски кода и снэпшоты изображений в ходе обработки, чтобы проиллюстрировать то, что происходит с документом в процессе. Программирую в этом случае на Python.
Шаг 1: чтение фотографии или изображения
# импортирование необходимых библиотек
import numpy as np
import cv2
import imutils
# параметр для сканируемого изображения
args_image = “fuel_bill_to_scan.jpg”
# прочитать изображение
image = cv2.imread(args_image)
orig = image.copy()
# показать исходное изображение
cv2.imshow(“Original Image”, image)
cv2.waitKey(0) # press 0 to close all cv2 windows
cv2.destroyAllWindows()
Первый шаг. В нём мы импортируем необходимые библиотеки и определяем аргумент исходного изображения со ссылкой на место, где оно лежит, чтобы отсканировать его и обработать. После этого мы читаем изображение при помощи функции imread OpenCV и делаем бэкап-копию на случай, если оно понадобится позже.
Мы отображаем обработанное изображение при помощи команды imshow. Если вы не знакомы с ней, imshow открывает всплывающее окно, которое показывает превью изображения, а функция waitKey будет держать его в таком положении, пока вы не нажмёте ключевую клавишу (в примере это 0). Как только вы закроете превью, нажмите кнопку 0 на клавиатуре и открывшийся попап исчезнет, а ваша сессия Python станет активной.
Шаг 2: идентификация краёв
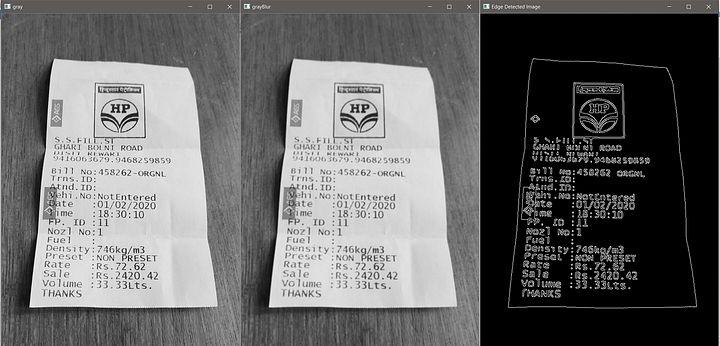
# конвертация изображения в градации серого. Это уберёт цветовой шум
grayImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# размытие картинки, чтобы убрать высокочастотный шум
# это помогает определить контур в сером изображении
grayImageBlur = cv2.blur(grayImage,(3,3))
# теперь производим определение границы по методу Canny
edgedImage = cv2.Canny(grayImageBlur, 100, 300, 3)
# показать серое изображение с определенными границами
cv2.imshow("gray", grayImage)
cv2.imshow("grayBlur", grayImageBlur)
cv2.imshow("Edge Detected Image", edgedImage)
cv2.waitKey(0) # нажать 0, чтобы закрыть все окна cv2
cv2.destroyAllWindows()Мы конвертировали цветное изображение в серое, чтобы уменьшить любой цветовой шум. Чтобы освежить знания: у цветного изображения глубина 3 (по единице на каждый цвет из RGB), в то время как у серого цвета глубина 1. Затем мы применяем функцию blur, чтобы размыть изображение с фильтром (3,3). Размытие уменьшает любой высокочастотный шум и упрощает определение контуров.
Теперь применим алгоритм определения границ Canny, чтобы найти контуры на размытом изображении. Это один из самых популярных алгоритмов для определения широкого диапазона границ в изображениях. John F. Canny разработал его в 1986-м и этот метод еще называют оптимальным детектором.
Помните, что в коде выше я использовал настройки, которые подходят только для моего случая. Если эти значения не сработают на вашем изображении, то поиграйте с настройками и оставьте те из них, которые приводят к наилучшему результату в вашем примере.
Шаг 3: определение границ области на изображении
# найти контуры на обрезанном изображении, рационально организовать область
# оставить только большие варианты
allContours = cv2.findContours(edgedImage.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
allContours = imutils.grab_contours(allContours)
# сортировка контуров области по уменьшению и сохранение топ-1
allContours = sorted(allContours, key=cv2.contourArea, reverse=True)[:1]
# aппроксимация контура
perimeter = cv2.arcLength(allContours[0], True)
ROIdimensions = cv2.approxPolyDP(allContours[0], 0.02*perimeter, True)
# показать контуры на изображении
cv2.drawContours(image, [ROIdimensions], -1, (0,255,0), 2)
cv2.imshow(“Contour Outline”, image)
cv2.waitKey(0)
cv2.destroyAllWindows()
Теперь мы займёмся поиском контуров в нашем обрезанном изображении. Оставляем контур с максимальной областью и отбрасываем остальные варианты. Рассматривая изображение с границами, отображенными в предыдущем шаге, мы можем чётко увидеть, что границы документа очерчивают максимальную целостную область. Вместо множества итераций по каждому контуру и сохранению экстремумов, мы просто проверяем область и сохраняем ту, у которой максимальная площадь. Это экономит нам много ресурсов. Если мы заранее знаем количество углов в нашем документе, тогда мы можем использовать такой метод проверки и рассчитывать на хорошие результаты.
Тут мы использовали парочку функций CV2, таких как findContours — для получения всех контуров в обрезанном изображении, contourArea — для получения области, замкнутой контуром координат и arcLength. Мы сохранили координаты контуров, чтобы пользоваться ими дальше для обрезки необходимой нам области документа с изображения.
Шаг 4: идентификация и получение границ документа
# изменение массива координат
ROIdimensions = ROIdimensions.reshape(4,2)
# список удержания координат ROI
rect = np.zeros((4,2), dtype=”float32")
# наименьшая сумма будет у верхнего левого угла,
# наибольшая — у нижнего правого угла
s = np.sum(ROIdimensions, axis=1)
rect[0] = ROIdimensions[np.argmin(s)]
rect[2] = ROIdimensions[np.argmax(s)]
# верх-право будет с минимальной разницей
# низ-лево будет иметь максимальную разницу
diff = np.diff(ROIdimensions, axis=1)
rect[1] = ROIdimensions[np.argmin(diff)]
rect[3] = ROIdimensions[np.argmax(diff)]
# верх-лево, верх-право, низ-право, низ-лево
(tl, tr, br, bl) = rect
# вычислить ширину ROI
widthA = np.sqrt((tl[0] — tr[0])**2 + (tl[1] — tr[1])**2 )
widthB = np.sqrt((bl[0] — br[0])**2 + (bl[1] — br[1])**2 )
maxWidth = max(int(widthA), int(widthB))
# вычислить высоту ROI
heightA = np.sqrt((tl[0] — bl[0])**2 + (tl[1] — bl[1])**2 )
heightB = np.sqrt((tr[0] — br[0])**2 + (tr[1] — br[1])**2 )
maxHeight = max(int(heightA), int(heightB))Из всего процесса сканирования эта часть больше всего насыщена программированием. И теперь у нас есть координаты 4 углов документа, мы будем соотносить координаты с углами, а затем расположим их в определённом порядке.
Поясню основы: изображение состоит из пикселей разного значения (интенсивность цвета). Для цветных изображений у нас будет 3 пикселя значения для точки, а для серого изображения у нас будет один пиксель. Итак, размер изображения — это матрица с первым элементом высоты, вторым — ширины и третьим — глубины цвета, которая обычно равна 3 для цветного изображения и 1 для серого. Итак, мы можем сказать, что для серого изображения у нас будет только два измерения — высота и ширина.
Теперь, с этой базой, каждый из 4-х углов изображения может быть идентифицирован с его пиксельными координатами как точка на плоскости X-Y. Пиксели изображения начинаются сверху слева. Принимая, что h представляет высоту, а w — ширину, форма изображения будет определяться (h, w, d), где d — это глубина, на которую можно не обращать внимания в случае с серым изображением (h,w).
- Верхний левый угол изображения будет иметь координаты (0,0), значит, мы можем сказать, что высота и ширина будут наименьшими среди данных 4-х пар координат.
- Верхний правый угол изображения будет иметь минимальное значение высоты, но максимальное по ширине. В идеале это будет (0,w).
- Нижний левый угловой пиксель изображения будет находиться по диагонали напротив верхнего правого. Он должен быть (h,0), т.е. иметь максимальное значение высоты, но минимальное по ширине.
- Нижний правый угол изображения будет иметь максимальное значение по высоте и ширине одновременно.
Применяя описанные параметры 4 углов, мы можем сделать вывод, что верхний левый угол будет иметь наименьшую сумму, в то время как нижняя правая точка будет иметь максимальную сумму среди 4-х точек с координатами. Верхняя правая точка будет иметь минимальную разницу, в то время как нижний левый угол будет иметь наибольшую разницу среди 4 точек с координатами.
Применяя это рассуждение, мы можем определить, какие координаты к какому из углов ближе. Мы создали список и захватили контур, т.е. координаты ROI (Region of Interest — области интереса) для того, чтобы первая запись в списке была о верхней левой точке, вторая — о правой верхней, третья — о правой нижней и 4-я — о нижней слева. В принципе, направление по часовой стрелке и начинается с левого верхнего угла.
Мы рассчитали ширину и высоту изображения во многом так, как мы вычисляем расстояние между 2 точками на плоскости X-Y. Тут нужна базовая статистика. Для остального вы можете найти идеи решения в приведённом фрагменте кода и том, как он имплементирован.
Шаг 5: применить перспективное преобразование
# набор итоговых точек для обзора всего документа
# размер нового изображения
dst = np.array([
[0,0],
[maxWidth-1, 0],
[maxWidth-1, maxHeight-1],
[0, maxHeight-1]], dtype="float32")
# вычислить матрицу перспективного преобразования и применить её
transformMatrix = cv2.getPerspectiveTransform(rect, dst)
# преобразовать ROI
scan = cv2.warpPerspective(orig, transformMatrix, (maxWidth, maxHeight))
# давайте посмотрим на свёрнутый документ
cv2.imshow("Scaned",scan)
cv2.waitKey(0)
cv2.destroyAllWindows()
Ну а теперь у нас есть размеры нашей ROI, и мы собираем набор итоговых точек, чтобы получить обзор с высоты птичьего-полёта, т.е. вид всего изображения сверху. Снова, давайте определим точки в том же порядке, что и раньше, т.е. верх-лево, верх-право, низ-право, низ-лево. Здесь важен порядок, и он должен быть совместим с порядком того, в каких координатах ROI сохранена наша область. Причина в том, что мы будем извлекать ROI из изображения и преобразовывать её по новым размерам.
Применив функцию getPerspectiveTransform, мы рассчитали матрицу, которая будет преобразовывать нашу ROI в итоговые размеры, т.е. целостное изображение нашего документа и ничего больше. Для этого нам нужны координаты ROI и итоговой матрицы. Далее мы извлекли площадь ROI из изображения и применили эту трансформацию на полученной области, чтобы получить вид всего нашего документа целиком. Тут мы применили функцию warpPerspective. Вывод: это и есть изображение всего документа.
Шаг 6: финальные шаги
Мы получили наш документ, фактически отсканированным и вырезанным из исходного изображения. И даже несмотря на то, что документ был сфотографирован под углом, мы смогли получить правильную перспективу, применив матрицу преобразования на выделенной области. Итоговый результат на самом деле выглядит хорошо.
И в конце мы можем подготовить изображение для отображения результата. Обратите внимание, цвет документа такой же, как на исходной картинке. В этом шаге мы применим некоторые действия по пост-обработке, чтобы улучшить внешний вид нашего отсканированного документа. Многие люди могут захотеть, чтобы их скан был черно-белым или предпочтут увеличить итоговый контраст в случае с документом. Мы можем также усилить цвет в финальном отсканированном изображении. В финале мы и делаем всё это.
# конвертация в серый
scanGray = cv2.cvtColor(scan, cv2.COLOR_BGR2GRAY)
# показать финальное серое изображение
cv2.imshow("scanGray", scanGray)
cv2.waitKey(0)
cv2.destroyAllWindows()
# ------------------------------
# конвертация в черно-белое с высоким контрастом для документов
from skimage.filters import threshold_local
# увеличить контраст в случае с документом
T = threshold_local(scanGray, 9, offset=8, method="gaussian")
scanBW = (scanGray > T).astype("uint8") * 255
# показать финальное изображение с высоким контрастом
cv2.imshow("scanBW", scanBW)
cv2.waitKey(0)
cv2.destroyAllWindows()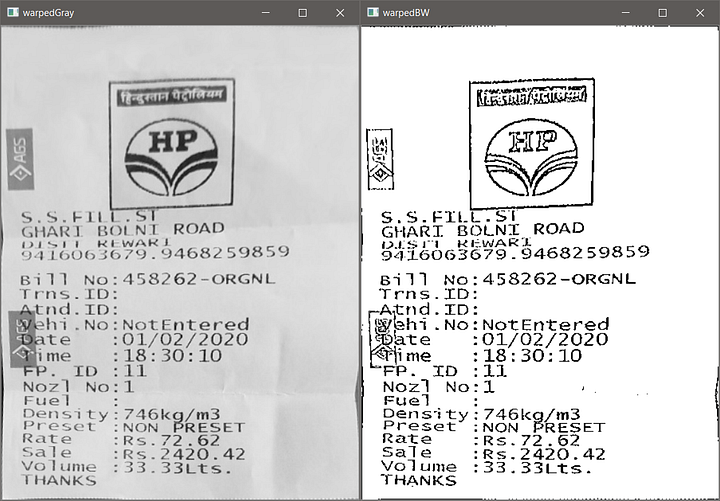
Заключение
И наконец, мы закончили со сканированием документа и преобразованием для оптимизации его внешнего вида. Этот код можно поместить в веб-интерфейс с помощью flask. Flask — это один из часто используемых и лучших фреймворков для веб-приложений, написанных на Python. Мы можем дальше запускать наш код “на лету” или “по требованию” при помощи docker. Такая программа всего лишь основа для создания приложения. Например, этот код можно генерализировать и создать из него мобильное или веб-приложение. Я очень хочу вдохновить вас на создание своего собственного приложения сканирования вместо использования тех, что доступны в интернете.
Одна важная вещь, которую я хотел бы подчеркнуть ещё раз, что для разных параметров функций, я пользовался теми значениями, что подходили лучше всего в моём случае. Я пришёл к этим значениям после того, как испробовал различные комбинации. В случае, если вы будете переиспользовать мой подход и саму программу, вам следует проверить, какая комбинация работает лучше именно для вас. Более того, если мы планируем всё это действительно запускать, т.е. зарелизим приложение или сканер документов, тогда постарайтесь сфотографировать документ ровно (держите телефон параллельно поверхности) вместо того, чтобы снимать под углом. Так вы получите лучшие результаты.
Я надеюсь, вам понравилась моя статья, а знания пригодятся для вашей собственной разработки приложения по сканированию изображений.
Читайте также:
- Распознавание лиц с помощью OpenCV
- Все модели машинного обучения за 6 минут
- Анализ аудиоданных с помощью глубокого обучения и Python (часть 1)
Перевод статьи Dinesh Yadav: Document Scanner using Computer Vision


")


