
“Люди часто восхваляют классические произведения, даже не читая их”, — Марк Твен.
Надеюсь, что ваш опыт опровергает это высказывание Марка Твена, а также верю, что вы всё-таки читали хотя бы одно из его классических произведений. Если нет, возможно, эта статья подтолкнёт вас к изучению его книг через призму текстовой аналитики.
Что такое анализ текста?
Анализ текста — это процесс изучения неструктурированных данных, которые представлены в форме текста. Ее задача — получить представление о паттернах и интересующих темах.
Почему она так важна?
Есть много причин для проведения текстового анализа. Самая главная из них — разобраться в настроениях и эмоциях, используемых в приложениях и сервисах, которые мы посещаем каждый день. Благодаря текстовой аналитике мы можем извлекать важную информацию из твитов, электронных писем, текстовых сообщений, рекламы, карт и многого другого.
В этом туториале я покажу вам, как начать с базовых возможностей в языке R, которые понадобятся для текстовой аналитики.
R является и языком, и средой для статистических вычислений и графики.
Поехали
Мы собираемся установить пакет gutenbergr, чтобы получить доступ в библиотеку общедоступных книг и публикаций.
Пакет gutenbergr поможет загрузить и обработать по областям открытые работы из коллекции Project Gutenberg. В него входят также инструменты для загрузки книг (и разбора заголовка/информации в нижнем колонтитуле), а ещё полный датасет метаданных Project Gutenberg, который можно использовать для поиска слов, предоставляющих интерес.
Давайте установим и загрузим библиотеку в R Studio.
install.packages("gutenbergr")library(gutenbergr)
Книги Марка Твена
Сейчас мы собираемся извлечь несколько книг авторства Марка Твена из библиотеки gutenbergr.
В библиотеке gutenbergr каждая книга маркирована идентификационным номером (ID). Нам он понадобится для установления их местонахождения.
- Приключения Геккельберри Финна — gutenbergr ID: 76
- Приключения Тома Сойера — gutenbergr ID: 74
- Простаки за границей — gutenbergr ID: 3176
- Жизнь на Миссисипи — gutenbergr ID: 245
mark_twain <- gutenberg_download(c(76, 74, 3176, 245))
При помощи функции gutenberg_download берём книги и сохраняем их в датафрейм mark_twain.
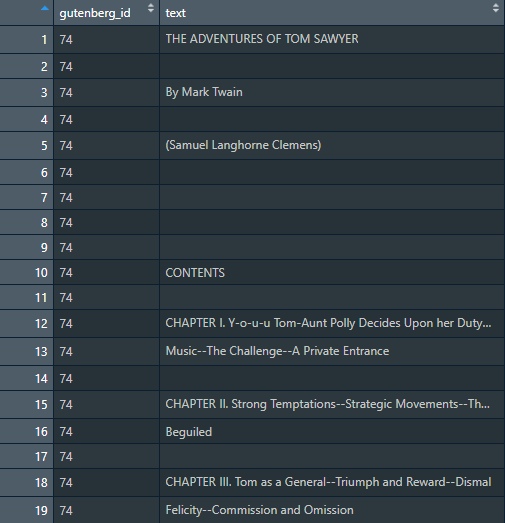
При помощи R книги помещаются в отдельные строчки и соотносятся со столбцом по релевантному ID-номеру. Очевидно, что данные достаточно беспорядочные и на этом этапе приносят не слишком много пользы анализу.
Идентификация стоп-слов
Когда вы проанализируете любой текст, то увидите, что всегда будут попадаться избыточные слова, которые могут изменить результат в зависимости от того, какие шаблоны или тенденции вы пытаетесь обнаружить. Их называют стоп-словами. Вам самим решать, хотите ли вы удалить их, а в моём примере мы определённо их уберем.
Для начала нам нужно загрузить библиотеку tidytext.
library(tidytext)
Дальше мы просмотрим stop_words во всей базе данных R (не в книгах Марка Твена).
data(stop_words)

Обратите внимание, что у нас получилось 1,139 строк.
Токенизация и удаление стоп-слов
Для удаления стоп-слов и токенизации нашего текста используем метод “трубопровода” из библиотеки dplyr.
Токенизация — это задача по разделению текста на кусочки.
Понимайте это так, что токенизация разрезает предложение на отдельные слова. В процессе анализа текста это даёт программе структуру данных для работы.

Мы совместим в одну цепочку (piping) несколько шагов, чтобы удалить стоп-слова, пока будет происходить токенизация датафрейма mark_twain.
library(dplyr)
tidy_mark_twain <- mark_twain %>%
unnest_tokens(word, text) %>% #tokenize
anti_join(stop_words) #remove stop words
print(tidy_mark_twain)Шаги:
- Формула unnest tokens и проходы по входным данным нужны, чтобы определить, что именно мы хотим подвергнуть токенизации и где получить доступ к тексту.
- При помощи anti_join мы в значительной степени исключаем все слова, которые находятся в базе данных stop_words.
- Сохраняем всю нашу работу в новую переменную tidy_mark_twain.
- Посмотрите:
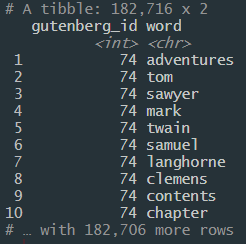
Обратите внимание, что с тех пор, как каждый объект подвергся токенизации, у нас стало 182,706 строчек! Это потому, что каждое слово теперь находится в отдельной строчке.
Частотное распределение слов
Наша задача — найти паттерны в данных. Частотное распределение слов — это отличный способ увидеть, какие слова нужно сортировать и искать.
tidy_mark_twain %>%
count(word, sort=TRUE)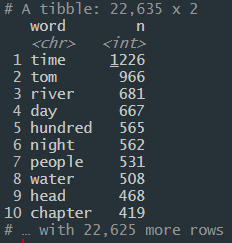
Если вы читали любую из книг Марка Твена, то не удивитесь, что Том — это второе по популярности слово. А еще интереснее, что самое популярное слово “время” встречается 1226 раз!
Визуализация данных
При помощи библиотеки ggplot2 мы можем добавить определенный визуальный контекст, чтобы увидеть, какие из слов чаще употребляются в тексте.
library(ggplot2)
freq_hist <-tidy_mark_twain %>%
count(word, sort=TRUE) %>%
filter(n > 400) %>%
mutate(word = reorder(word,n )) %>%
ggplot(aes(word, n))+
geom_col(fill= 'lightgreen')+
xlab(NULL)+
coord_flip()
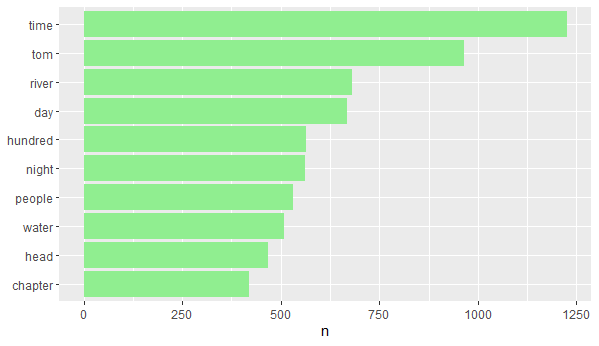
print(freq_hist)Некоторые ключевые шаги, которые нужно пройти, чтобы получить точный граф:
- filter() нужен, чтобы убедиться, что мы не выведем количество для каждого слова, которое встречается в тексте. Это было бы слишком много. Так мы устанавливаем границу слов, которые встречаются чаще, чем 400 раз.
- mutate() нужен, чтобы организовать представление слов в лучшем виде.
- coord_flip() нужен, чтобы развернуть граф и сделать его привлекательнее визуально.
Заключение
Текст повсюду, а значит, есть бессчетное количество возможностей анализировать и придавать смысл неструктурированным данным. Теперь у вас есть база, которая должна пригодится вам в начале путешествия по анализу текста.
Читайте также:
- Значение Data Science в современном мире
- Шесть рекомендаций для начинающих специалистов по Data Science
- Почему за способностью объяснения модели стоит будущее Data Science
Перевод статьи Jason Lee: Text Analytics in R





