
Есть три типа шаблонов данных:
- Шаблоны/факты, которые существуют в наборе данных и за его пределами.
- Шаблоны/факты, которые существуют только в наборе данных.
- Шаблоны/факты, которые существуют только в воображении (апофении).

Какой из этих шаблонов наиболее полезен? Зависит от поставленных целей.
Вдохновение
Если вами движет вдохновение, то подойдут все типы шаблонов. Даже апофений — склонность человека ошибочно воспринимать связи и значения между несвязанными вещами — может стать объектом для творчества.
Факты
Когда правительство собирает налоги, его не интересуют шаблоны за пределами финансовых данных за год. Ему необходимо принять решение на основе фактов о сумме долга гражданина, а для этого нужно проанализировать данные за прошлый год. Другими словами, просмотреть данные и применить формулу. Для этого нужна чисто описательная аналитика, которая привязана к имеющимся данным, поэтому любой из первых двух типов шаблонов подойдет для этих целей.
Решения в условиях неопределенности
Иногда имеющиеся факты не совпадают с желаемыми фактами. При отсутствии полной информации, необходимой для принятия желаемого решения, необходимо ориентироваться в неопределенности, пытаясь выбрать разумный курс действий.
Этим занимается статистика — наука об изменении мнения в условиях неопределенности.
Однако, прежде чем начать, убедитесь, что найденные в частичном представлении реальности шаблоны действительно работают за ее пределами. Другими словами, шаблоны должны приводить к общим выводам.
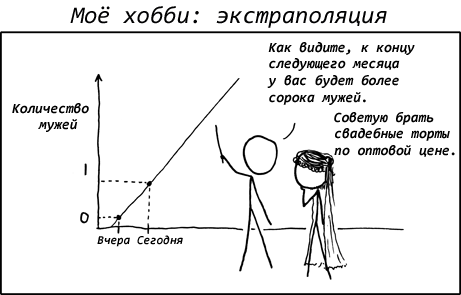
Из трех вариантов только первый (обобщенный) тип шаблона безопасен при принятии решений в условиях неопределенности. К сожалению, в используемых данных можно найти и другие типы шаблонов. И здесь возникает проблема: как же получить максимально точную информацию из данных?
Обобщение
Если вы думаете, что вытаскивать бесполезные шаблоны из данных — это только человеческая привилегия, то вы ошибаетесь!
Машинное обучение — это подход к принятию множества аналогичных решений, который включает алгоритмический поиск шаблонов в данных и их использование для правильного воздействия на новые данные. На языке МО/ИИ обобщение обозначает способность модели к правильной работе с данными, которые не встречались ранее. Что хорошего в шаблонах, которые успешно работают только со старыми данными? Для этого ведь можно использовать таблицу поиска. Смысл МО/ИИ заключается в правильном обобщении под новые ситуации.

По этой причине первый тип шаблонов — единственный тип, который подходит для машинного обучения. Эта часть является сигналом, а остальное — просто шум (существует только в старых данных и отвлекает от создания обобщаемой модели).
Сигнал: шаблоны, которые существуют в наборе данных и за его пределами.
Шум: шаблоны, которые существуют только в наборе данных.
Получение решения, которое обрабатывает старый шум вместо новых данных, в машинном обучении называется переобучением. Почти все действия, выполняемые в машинном обучении, служат для того, чтобы избежать переобучения.
Какой же шаблон является «тем самым»?
Предположим, что шаблон, который вы (или машина) извлекли из данных, существует вне вашего воображения, какой это тип? Является ли он реальным явлением, которое существует в совокупности, представляющей интерес («сигнал»), или особенностью текущего набора данных («шум»)? Как определить, какой тип шаблона был найден в результате исследования набора данных?
При просмотре всех имеющихся данных определить это будет невозможно. Нет никакого способа узнать, существует ли шаблон в другом месте. Вся риторика статистической проверки гипотезы зависит от неожиданности, поэтому не стоит удивляться появлению уже известного шаблона в данных. (По сути, это слепое прочесывание данных — p-hacking.)

Эту ситуацию можно сравнить с той, когда, увидев облако в форме кролика, вы начинаете проверять, все ли облака похожи на кроликов…, используя одно и то же облако. Для проверки этой теории понадобятся и другие облака.
Любая точка данных, используемая для вдохновения теории или вопроса, не может быть использована для проверки этой же теории.
Это приводит к самому печальному выводу. Используя набор данных в поисках вдохновения, вы не сможете применить его снова для проверки теории, которую он вдохновил (математика никогда не противоречит простому здравому смыслу).
Необычный трюк
Чтобы выиграть в науке о данных, просто превратите один набор данных в (как минимум) два с помощью разделения данных. Затем используйте один для вдохновения, а другой для тщательного тестирования. Если шаблон, используемый для вдохновения, так же существует в данных, которые не влияют на ваше мнение, то у вас будет более многообещающий голос в пользу того, что этот шаблон — обычное явление в горе мусора, из которой были собраны данные.
Если одно и то же явление существует в обоих наборах данных, возможно, это общее явление, которое также существует независимо от того, откуда взялись эти наборы данных.
Разделите свои данные!
Мир был бы лучше, если бы все разделяли данные. У нас были бы лучшие ответы (из статистики) на лучшие вопросы (аналитики). Единственная причина, по которой люди не рассматривают разделение данных как что-то обязательное, заключается в том, что в прошлом веке это была роскошь, которую мало кто мог себе позволить. Наборы данных были настолько малы, что при попытке их разделить ничего бы не осталось.

Если вы не привыкли разделять данные, вы застряли в 20-м веке.
Идея очень проста. Используйте один набор данных для формирования теории, а затем выполните магический трюк, доказав свои выводы с помощью тестового набора данных.
Разделение данных — это простое и быстрое решение для более здоровой культуры данных.
Читайте также:
- Сумасшедший способ проверить, является ли число простым, используя регулярное выражение
- Машинное обучение. С чего начать? Часть 1
Перевод статьи Cassie Kozyrkov: The most powerful idea in data science





