
Вы когда-нибудь пробовали решать задачи с помощью визуализации? Предлагаем решить занимательную задачу на языке R.

Нобелевские премии (до 1969 года всего их было пять, а затем добавилась шестая) присуждаются ежегодно фондом, учрежденным шведским изобретателем и промышленным магнатом Альфредом Нобелем. Во всем мире Нобелевская премия считается самой престижной наградой за интеллектуальные достижения.
Подбираем данные
Нужный нам набор данных можно скачать с kaggle.
Мы постараемся визуализировать изменение возраста лауреатов премии во времени.
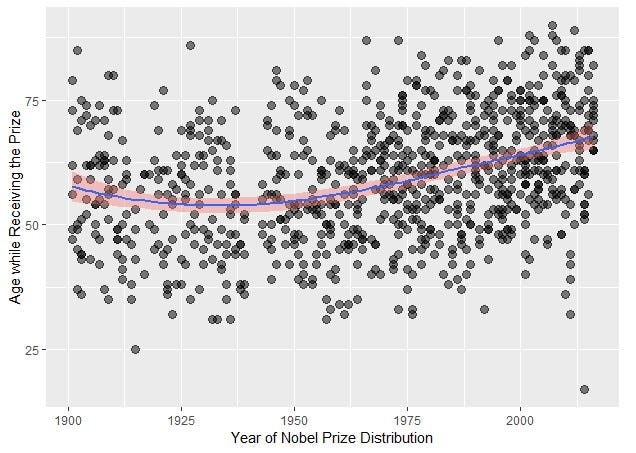
Мы видим, что до 1950 года средний возраст лауреатов держался почти на одной отметке. Затем он стал стабильно увеличиваться почти на 8 лет.
Для выполнения операций мы воспользуемся библиотекой tidyverse. Tidyverse — это очень полезная библиотека для загрузки таких важных пакетов, как dplyr, ggplot2, dbplyr, lubridate, readxl, readr, tidyr и др.
tidyverse — это набор пакетов, слаженная работа которых возможна благодаря общим представлениям данных и единому дизайну API. Этот пакет придумали, чтобы «уместить» установку и загрузку нескольких пакетов tidyverse в один этап.
Функция read.csv считывает данные из CSV-файла и сохраняет их в переменной в виде пакета данных. У нас он называется nobel.
Функция mutate добавляет новые переменные и сохраняет уже существующие в пакеты данных. В нашем случае mutate добавляет в пакет данных новый столбец под названием age (возраст).
age рассчитывается через функцию as.Date, которая преобразует представления символов в объекты класса Date (даты в календаре).
И, наконец, ggplot используется для диаграммы рассеивания. Эта диаграмма строится путем размещения переменной year на оси Х и age на оси У. Для построения точек используется geom_point. Мы можем задать размер каждой точки. В нашем примере size (размер) равен 3, а alpha (альфа) — 0,5. Эти показателизададут непрозрачность (прозрачность) точек и помогут быстрее обнаружить области их наложения.
#Загрузка необходимых библиотек
library(tidyverse)
nobel <- read.csv("nobel.csv")
nobel_age <- nobel %>%
mutate(age = year - year(as.Date(birth_date)))
ggplot(nobel_age,aes(x=year,y=age)) + geom_point(size = 3, alpha = 0.5,color = "black") + geom_smooth(aes(fill = "red")) + xlab("Year of Nobel Prize Distribution") + ylab("Age while Receiving the Prize")Исследуем данные
Есть одна проблема. Как мы видим, на диаграмме представлено слишком мало информации. А при визуализации данных их форма и цвет играют ту же роль, что и сахар в приготовлении леденцов.
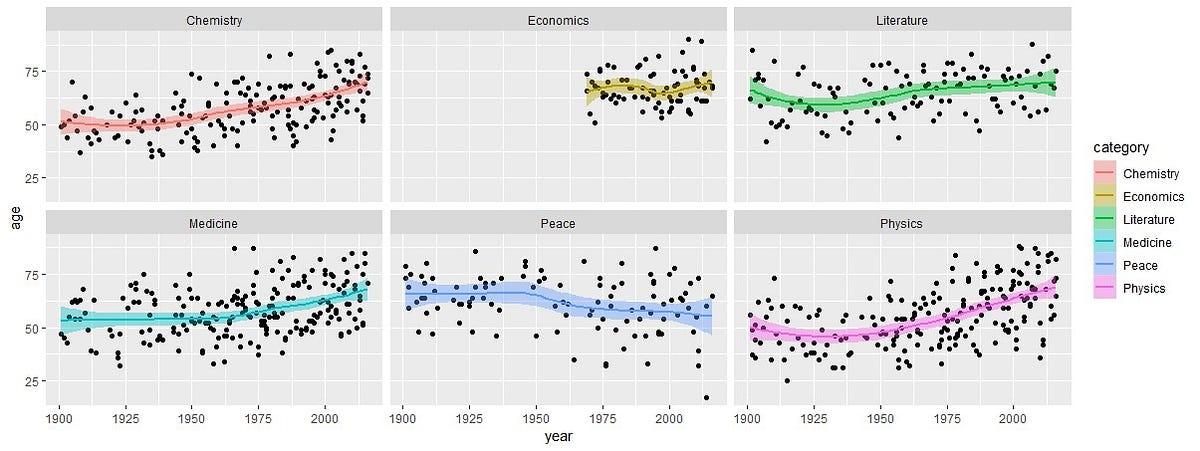
На диаграмме ниже мы видим, что в трех категориях Chemistry (Химия), Medicine (Медицина) и Physics (Физика) прослеживаются схожие тенденции — средний возраст получения премии с годами увеличивается. Наибольшее отклонение отмечается в категории «Физика». Единственная категория, демонстрирующая снижение среднего возраста во времени, — это Peace (Премия мира). Значения в категориях Economics (Экономика) и Literature (Литература) почти не менялись.
Еще одно важное наблюдение: большой разброс точек в категории «Премия мира» говорит о том, что было много таких Нобелевских лауреатов, возраст которых сильно отличается от среднего значения.
Так в каком же возрасте вы бы смогли получить Нобелевскую премию в различных категориях?
- Химия, возраст= 70 | Наиболее вероятно: (возраст > 70)
- Экономика, возраст = 69 | Наиболее вероятно: (67 < возраст < 71)
- Литература, возраст = 70 | Наиболее вероятно: (67 < возраст < 75)
- Медицина, возраст = 68 | Наиболее вероятно: (возраст > 52)
- Премия мира, возраст = 55| Наиболее вероятно: (возраст < 65)
- Физика, возраст = 69| Наиболее вероятно: (возраст > 66)
Давайте разберемся с кодом, который помог нам получить эти результаты. Мы загрузили ту же библиотеку, что и ранее в статье.
facet_wrap — оборачивает первую последовательность панелей во вторую. Это куда лучшее использование экранного пространства, чем facet_grid(), поскольку большинство представлений имеют прямоугольную форму.
ggplotly — преобразует ggplot2 в plotly. Данная функция конвертирует объект ggplot2::ggplot() в объект plotly.
Так что же в итоге делает этот код?
Диаграмма создавалась с использованием функции ggplot. Вкачестве данных рассматривался измененный пакет данных nobel_age. По осям Х и У располагались соответственно год и возраст. geom_point использовался для отрисовки диаграммы рассеивания, а geom_smoothискал закономерности в наложении точек одного цвета/заливки друг на друга.
Цвета и заливка задавались в переменной category. Так разные категории на диаграмме были окрашены в разные цвета. Например, если бы нам нужно было нарисовать диаграмму для магазина шоколада и отобразить там три категории («молочный шоколад», «белый шоколад» и «темный шоколад»), то этот метод разметил бы категории разными цветами, и мы бы смогли легче интерпретировать результаты.
facet_wrap в нашем примере отвечает за отрисовку каждого подокна категории. Так мы получаем шесть разных подокон, разделенных по категориям.
#Загрузка нужных библиотек
library(tidyverse)
library(plotly)
nobel <- read.csv("nobel.csv")
nobel_age <- nobel %>%
mutate(age = year - year(as.Date(birth_date)))
p <- ggplot(nobel_age,aes(x=year,y=age)) +
geom_point() +
geom_smooth(aes(colour = category, fill = category)) +
facet_wrap(~ category)
ggplotly(p)Перевод статьи Satyam Singh Chauhan: At what age will you win the Nobel Prize? Let’s Visualize using R.





