
Для извлечения данных с веб-страницы существует множество решений и инструментов. Каждый метод обладает своими сильными и слабыми сторонами, знание которых сохранит время и повысит эффективность решения задач.
С помощью каких способов можно извлечь данные с веб-страницы?
Каковы плюсы и минусы каждого подхода?
Как использовать облачные сервисы для повышения уровня автоматизации?
Ответы на эти вопросы можно найти в этом руководстве.
Если вы не знакомы с базовыми понятиями работы браузеров, такими как HTTP-запросы, DOM (Document Object Model), HTML, CSS-селекторы и Async JavaScript, то изучите их, прежде чем продолжить чтение этой статьи. Примеры реализованы в Node.js, однако эту теорию можно использовать и для других языков.
Статическое содержимое
HTML source
Начнем с самого простого подхода. Он не требует большого количества вычислительной мощности и много времени на реализацию.
Однако он работает только в том случае, если исходный HTML-код содержит необходимые данные. Для проверки в Chrome нажмите правой кнопкой мыши и выберите View page source. Отобразится исходный код HTML.
Стоит отметить, что при использовании inspect tool в Chrome отобразится структура HTML, связанная с текущим состоянием страницы. Она не всегда совпадает с исходным HTML-документом, который можно получить с сервера.
После того, как вы найдете данные, напишите CSS-селектор, принадлежащий элементу wrapping. В дальнейшем вы будете ссылаться на него.
Для реализации отправьте запрос HTTP GET к URL-адресу страницы. Вы получите исходный HTML-код.
В Node можно использовать инструмент под названием CheerioJS для парсинга raw HTML и извлечения данных с помощью селектора. Код выглядит следующим образом:
const fetch = require('node-fetch');
const cheerio = require('cheerio');
const url = 'https://example.com/';
const selector = '.example';
fetch(url)
.then(res => res.text())
.then(html => {
const $ = cheerio.load(html);
const data = $(selector);
console.log(data.text());
});
Динамическое содержимое
В большинстве случаев невозможно получить доступ к информации из кода raw HTML, поскольку DOM находится под управлением JavaScript, который выполняется в фоновом режиме. К примеру, в SPA (Single Page Application) HTML-документ содержит минимальное количество информации, а JavaScript заполняет ее во время выполнения.
Чтобы решить эту проблему, нужно создать DOM и запустить сценарии, находящиеся в исходном HTML-коде, так же, как это происходит в браузере. В результате, данные из этого объекта можно извлечь с помощью селекторов.
Headless-браузеры
Headless-браузер очень схож с обычным браузером, однако в нем отсутствует пользовательский интерфейс. Он работает в фоновом режиме и может контролироваться с помощью программы.
Среди headless-браузеров самым популярным является Puppeteer. Это простая в использовании библиотека Node, предоставляющая высокоуровневый API для контроля Chrome в headless-режиме. Его можно настроить для работы в non-headless-режиме, что очень пригодится при разработке. Следующий код выполняет те же действия, что и предыдущий, но работает с динамическими страницами:
const puppeteer = require('puppeteer');
async function getData(url, selector){
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const data = await page.evaluate(selector => {
return document.querySelector(selector).innerText;
}, selector);
await browser.close();
return data;
}
const url = 'https://example.com';
const selector = '.example';
getData(url,selector)
.then(result => console.log(result));
Чтобы узнать больше о Puppeteer, посмотрите документацию. Фрагмент кода, с помощью которого можно перейти в URL, сделать скриншот и сохранить его:
const puppeteer = require('puppeteer');
async function takeScreenshot(url,path){
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
await page.screenshot({path: path});
await browser.close();
}
const url = 'https://example.com';
const path = 'example.png';
takeScreenshot(url, path);
Запуск браузера требует намного больше вычислительной мощности, чем отправка простого запроса GET и парсинг ответа. Следовательно, выполнение относительно более медлительно и энергозатратно. Помимо этого, включение браузера в качестве зависимости увеличивает размер пакета развертывания.
С другой стороны, этот метод очень гибкий. Его можно использовать для навигации по страницам, моделирования кликов, движений мышки и событий от клавиатуры, заполнения форм, скриншотов и генерирования PDF-страниц, выполнения команд в консоли, а также выбора элементов для извлечения их текстового содержимого. По сути, все действия, выполняемые в браузере вручную.
Создание DOM
Возможно, вы подумаете, что не стоит моделировать браузер целиком только для создания DOM. И вы правы. По крайней мере, при определенных обстоятельствах.
Библиотека Node под названием Jsdom выполняет парсинг HTML так же, как и браузер. Однако это не браузер, а инструмент для создания DOM из исходного кода HTML, одновременно выполняющий код JavaScript в этом HTML.
Благодаря абстракции, Jsdom работает быстрее, чем headless-браузер. Раз он быстрее, то почему бы не использовать его вместо headless-браузеров всегда?
Отрывок из документации:
При использовании jsdom часто возникают проблемы с асинхронной загрузкой сценариев. Многие страницы загружают сценарии асинхронно, однако невозможно определить, в какой момент это происходит, и следовательно, когда нужно запустить код и проверить полученную структуру DOM. Это основное ограничение.
… Его можно обойти с помощью проверки наличия определенного элемента.
Решение отображено в примере. Каждые 100 мс проверяется, появился ли элемент или произошел тайм-аут (через 2 секунды).
Также, если какая-либо функция браузера на странице не реализуется Jsdom, то появляются сообщения об ошибке. Например: “Error: Not implemented: window.alert…” или “Error: Not implemented: window.scrollTo…”. Эту проблему можно решить с помощью workarounds (virtual consoles).
В целом, это низкоуровневый API, по сравнению с Puppeteer, поэтому некоторые действия нужно реализовывать вручную.
Как видно из примера, все это усложняет его использование. Puppeteer решает эти проблемы за кадром и максимально упрощает использование. А Jsdom предложит быстрое решение для дополнительной работы.
Рассмотрим предыдущий пример, но с использованием Jsdom:
const jsdom = require("jsdom");
const { JSDOM } = jsdom;
async function getData(url,selector,timeout) {
const virtualConsole = new jsdom.VirtualConsole();
virtualConsole.sendTo(console, { omitJSDOMErrors: true });
const dom = await JSDOM.fromURL(url, {
runScripts: "dangerously",
resources: "usable",
virtualConsole
});
const data = await new Promise((res,rej)=>{
const started = Date.now();
const timer = setInterval(() => {
const element = dom.window.document.querySelector(selector)
if (element) {
res(element.textContent);
clearInterval(timer);
}
else if(Date.now()-started > timeout){
rej("Timed out");
clearInterval(timer);
}
}, 100);
});
dom.window.close();
return data;
}
const url = "https://example.com/";
const selector = ".example";
getData(url,selector,2000).then(result => console.log(result));
Обратная разработка
Jsdom — это быстрое и простое решение, однако можно найти более легкий подход.
Нужно ли вообще моделировать DOM?
Как правило, веб-страница, из которой нужно извлечь данные, состоит из HTML, JavaScript и других общеизвестных технологий. Таким образом, если найти кусочек кода, из которого получены необходимые данные, можно повторить ту же операцию для получения того же результата.
Проще говоря, этими данными могут быть:
- часть исходного кода HTML (как было сказано в первой части),
- часть статического файла, ссылка на который содержится в HTML-документе (к примеру, строка в файле javascript),
- ответ на сетевой запрос (к примеру, код JavaScript оправляет запрос AJAX к серверу и получает ответ строкой JSON).
Доступ к этим источникам данных можно получить с помощью сетевых запросов. С нашей точки зрения, не имеет значения, использует ли веб-страница HTTP, WebSockets или любой другой протокол связи, поскольку все они воспроизводимы в теории.
После нахождения ресурса, содержащего данные, можно отправить аналогичный сетевой запрос к тому же серверу, как и в исходной странице. В результате вы получаете ответ, содержащий необходимые данные, которые можно с легкостью извлечь с помощью регулярных выражений, методов string, JSON.parse и т. д.
Проще говоря, можно просто взять ресурс, в котором расположены данные, вместо того, чтобы обрабатывать и загружать все сразу. Таким образом, проблема, показанная в предыдущих примерах, решается с помощью одного HTTP-запроса.
В теории это решение выглядит простым, однако в большинстве случаев его выполнение занимает много времени и требует опыта работы с веб-страницами и серверами.
Поиски можно начать с наблюдения за сетевым трафиком. Для этого есть отличный инструмент Network tab в Chrome DevTools. Он отобразит все исходящие запросы с ответами (включая статические файлы, запросы AJAX и т. д.), которые можно просмотреть в поисках данных.
Процесс может замедлиться, если ответ был изменен фрагментом кода перед отображением на экране. В этом случае, нужно найти этот кусочек кода и разобраться, в чем дело.
Как можно заметить, это решение может потребовать еще больше работы, чем предыдущие методы. С другой стороны, после реализации оно предоставляет наилучшую производительность.
Этот график отображает необходимое время выполнения и размер пакета в сравнении с Jsdom и Puppeteer:
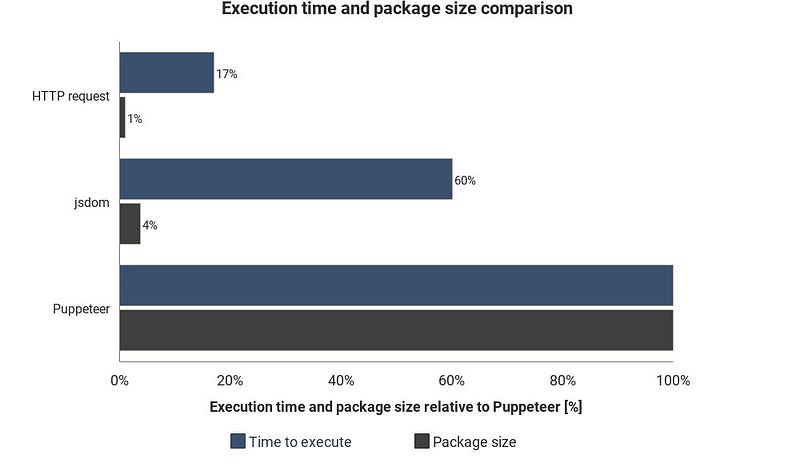
Результаты могут варьироваться в зависимости от ситуации, они лишь показывают примерную разницу между этими техниками.
Интеграция облачного сервиса
Допустим, вы реализовали одно из перечисленных решений. Один из способов выполнения сценария — включить компьютер, открыть терминал и запустить его вручную.
Однако все можно упростить, загрузив сценарий на сервер. Он будет выполнять код систематически в зависимости от настроек.
Это можно сделать, запустив сервер и настроив параметры выполнения сценария. Сервера светятся при наблюдении за элементом на странице. В других случаях облачная функция, вероятно, является более простым способом.
Облачные функции — это контейнеры, предназначенные для выполнения загруженного кода при появлении определенного события. Это означает, что не нужно управлять серверами, все выполняется автоматически с помощью выбранного облачного провайдера.
Возможным инициатором может быть программа, сетевой запрос и любые другие события. Полученные данные можно сохранить в базе данных, записать в Google sheet или отправить на email. Все зависит от вашей фантазии.
Популярные облачные провайдеры: Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure. Все они обладают сервисной функцией:
Google’s Cloud Functions — лучшее решение при использовании Puppeteer. Размер сжатого пакета Headless Chrome (~130MB) превышает лимит максимального сжатого размера AWS Lambda (50MB). Есть несколько техник выполнения для Lambda, однако функции GCP поддерживают headless Chrome по умолчанию. Нужно просто включить Puppeteer в качестве зависимости в package.json.
Вывод
Для реализации каждого решения вам понадобится заглянуть в документацию и прочитать несколько статей. Однако я надеюсь, что вы получили базовое представление о техниках, используемых для сбора данных с веб-страниц и продолжите дальнейшее изучение.
Перевод статьи David Karolyi: Web scraping for web developers: a concise summary





