
Говорят, что один (мужчина, женщина — какой-то человек) — в поле не воин. Но в наши дни к этому списку можно добавить и «компьютер». Мы окружены машинами, компьютерами и базами данных, которые «переговариваются» между собой. К слову сказать, большинство приложений и сервисов, с которыми мы ежедневно взаимодействуем (и создаем!), являются целой группой вычислительных элементов, общающихся друг с другом, даже если мы этого не замечаем.
Изучение данных систем и принципа их работы относится к области распределенных вычислений, в центре которых располагаются распределенные системы. С одной стороны, распределенные системы являются продолжением, или даже дополнением, информатики. Довольно часто они занимаются решением проблем, разделением их на отдельные задачи и поиском методов взаимодействия, сохранения и обработки данных.
Но, с другой стороны, распределенные системы совсем не похожи на информатику. Почти все распределенные вычисления требуют от нас распрощаться с нашими предположениями о том, как работают машины. Имея дело с одним компьютером, все выглядит не особо сложным. Однако, как быть, если задействованы несколько компьютеров?
Ну, это совершенно другая история.
До того, как их стало много, был только один
Чтобы лучше понять, что именно считается распределенной системой, необходимо разобраться в том, что таковой не является. На самом деле, точное определение «противоположности» распределенной системы вызывает ряд споров. В теории «противоположность» можно трактовать двояко, ведь определение распределенной системы зависит от ее компонентов. Но поговорим об этом чуть позже.
Мы можем рассматривать нераспределенную систему как «одиночную» систему. Одиночная система, которая не взаимодействует с другими и функционирует сама по себе, не является распределенной системой.

Одиночный процесс в нашем компьютере — это одиночная система, работающая сама по себе. Если процесс не взаимодействует с другими процессами, то он однозначно не является частью более крупной системы. Мы можем рассматривать отдельный компьютер, отключенный от интернета, как «одиночную» систему. Хотя все-таки существуют исследования, доказывающие обратное.
Слово распределенный означает рассеянный, разбросанный или как-то иначе распространенный в некотором пространстве. Если рассмотреть данное определение и то, как именно работают одиночные системы, то становится понятным, что сама по себе одиночная система не является распределенной. Существует только одна машина, работающая обособленно, поэтому она никак не может куда-либо распространяться!
Что же в данном случае будет считаться распределенной системой? Если мы представим себе, как именно взаимодействуют машины в реальном мире, то поймем, что большинство компьютеров существует внутри распределенной системы. Компьютеры редко используются в качестве обособленных единиц. Мы же почти всегда пользуемся ими для взаимодействия с другими приложениями и сервисами.
Если вы когда-либо играли в многопользовательскую онлайн-игру, бронировали билеты, постили твит с забавными котиками, смотрели шоу на Netflix или покупали кигуруми на Amazon, то делали это через распределенную систему.
Кроме того, скорее всего, каждый день вы взаимодействуете с крупнейшей распределенной системой — интернетом! Но не все распределенные системы бывают масштабными. К слову сказать, масштабность системы еще не делает ее распределенной.
Распределенная система — это ни что иное, как несколько элементов, которые общаются между собой в процессе выполнения своих операций. Такая система может быть простой как сенсорный датчик или беспроводной разъем, который собирает и передает данные по Wi-Fi… или даже беспроводная клавиатура или мышь, подключаемые к ноутбуку.
Если все процессы, происходящие внутри системы, автономны, выполняют собственные задачи и одновременно могут взаимодействовать с другими процессами, то мы называем такую систему распределенной.
Узлы, которые держатся вместе
Теперь, когда мы немного разобрались в определении распределенной системы, давайте познакомимся с ее главными составляющими, то есть «элементами» системы!
Возможно, вы уже заметили, что я называю компоненты распределенной системы «компьютером», «процессом» или даже «машиной». Точный термин, которым мы описываем составляющие распределенной системы, целиком и полностью зависит от того, что из себя представляет данная система, и к какому типу она относится. Если система — это группа распределенных серверов, то ее компоненты можно называть «серверами». Если в системе присутствуют взаимодействующие друг с другом процессы, то компонентами такой системы будут являться «процессы».
Во избежание путаницы в терминологии можно пользоваться совершенно иным, более собирательным определением. Отдельные компоненты распределенной системы называются узлами.
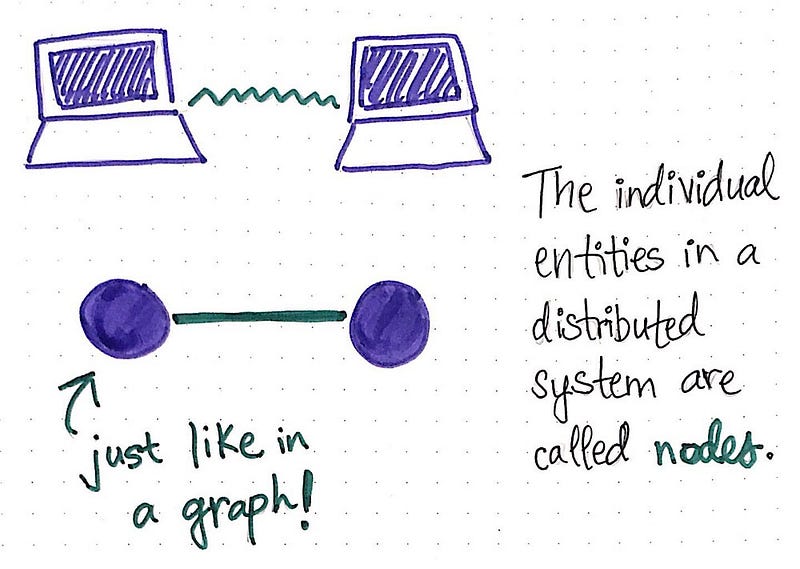
Если термин «узел» («нод») кажется вам знакомым (и даже напоминает о теории графов), то инстинкты вас не подводят — эти вещи действительно связаны! Если думать о распределенной системе как о сети вычислительных элементов (а именно таковыми они и являются), то сеть можно представить в виде графа, состоящего из взаимосвязанных узлов.
Поскольку мы уже знаем, что распределенная система может работать в большом и малом масштабе, то логично предположить, что и узлы различаются по своей природе. Узлом может являться аппаратное средство (например, сенсор) или процесс приложения (клиент или сервер). Узлам не обязательно находиться в одном месте (это и есть «распределение» системы). Они могут находиться на значительном физическом расстоянии друг от друга.
Новый способ изучения узлов
Несмотря на то, что узлы в распределенной системе чрезвычайно похожи на узлы в графе, есть ряд моментов, которые несколько осложняют ситуацию. Некоторые предположения, которые мы делаем для одиночной системы, оказываются в корне неверными, когда дело доходит до распределенных систем. Что до самих распределенных систем, то почти все трудности, возникающие на нашем пути, сводятся к одному и тому же: взаимодействие между узлами.

Поскольку изначально все узлы распределенной системы автономны, они могут выполнять собственные операции. Операции, происходящие внутри узла (и выполняющиеся самим узлом), не должны полагаться на внешнюю информацию. Другими словами, узел способен выполнять собственные операции без привлечения других узлов этой распределенной системы. То есть, узел может выполнять собственные операции без сторонней помощи и делает это довольно быстро.
Операции внутри узла выполняются быстро. Однако нельзя сказать того же о взаимодействии между узлами.
Как нам уже известно, узлы системы могут располагаться в разных местах, а для «переговоров» использовать сеть распределенной системы. Взаимодействие между узлами — это совсем другая история. Несмотря на «быстроту» проводимых операций внутри узлов, взаимодействие между узлами не всегда происходит быстро. На самом деле, взаимодействие между двумя узлами сильно «заторможено» (не говоря о том, что ненадежно!), что и является ключевой проблемой распределенных вычислений.
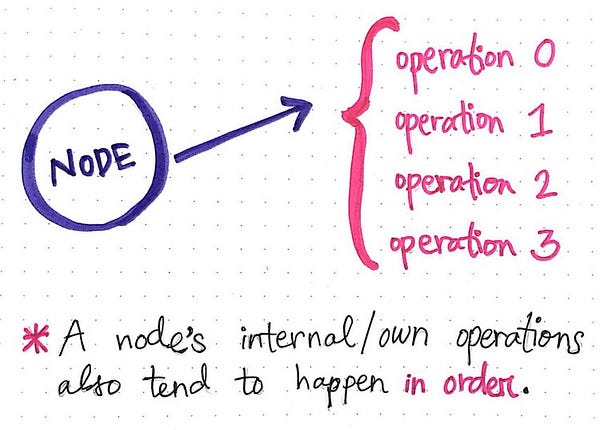
Операции внутри узла выполняются не только быстро, но и по порядку. На первый взгляд это кажется вполне логичным, ведь, конечно же, события должны происходить в определенной последовательности, разве не так? Но когда речь заходит о распределенных системах, ответом будет «не всегда».
Несмотря на очередность выполнения операций внутри узла, при «коллективной» работе нескольких узлов в распределенной системе возникает путаница. Как только мы переходим от одиночной системы/одного узла к распределенной системе/нескольким узлам, повышается вероятность того, что операции внутри группы узлов будут выполняться не по порядку.
Одной из причин упорядоченности операций внутри узла является тот факт, что каждый узел внутри системы работает по собственным часам.
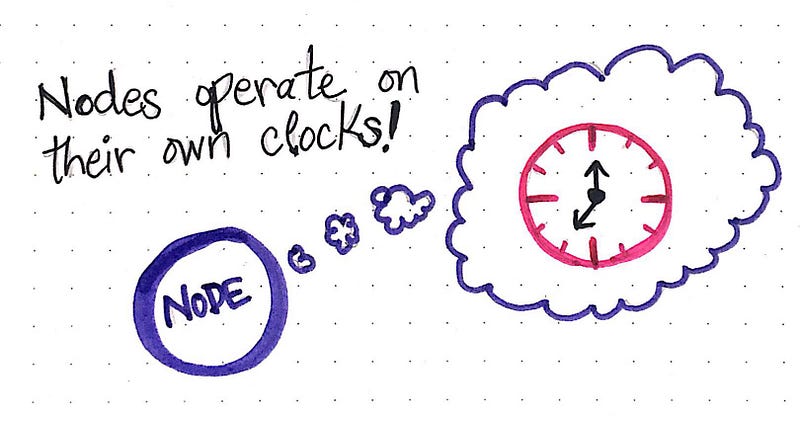
Если призадуматься о том, что именно может выступать в роли узла в распределенной системе (датчик, процесс, сервер или база данных), то наличие собственного времени в узле кажется волне логичным. Но, опять же, не трудно догадаться, какие проблемы это может привнести в распределенную систему: что если часы в двух отдельных узлах системы не совпадают? Это еще одна серьезная проблема распределенного вычисления.
Все, что мы знаем и любим в отдельно взятых элементах системы начинает казаться малознакомым и не таким уж хорошим, когда к процессу подключается сразу много узлов. Но как раз в этом и заключена вся прелесть изучения чего-то нового, например, распределенных систем!
Нам придется изменить свой подход к делу и пересмотреть наше видение распределенных систем и их составляющих, которые позволяют этим системам эффективно функционировать как единое целое.
Перевод статьи Vaidehi Joshi: Many Nodes, One Distributed System





