
Мой кейс
Масштабный симулятор муравьев, Ants, казался мне идеальным решением для моего первого хакатон-проекта. Но только до тех пор, пока я не добавил достаточно муравьев, чтобы стало еще интереснее. Правда, после этого резко упала производительность.
Проблема крылась в проверках близости между муравьями. Если каждый муравей должен проверять положение каждого другого муравья, внезапно получается O(N²) проверок расстояний, где N — количество муравьев. При нескольких сотнях муравьев это работало нормально. При нескольких тысячах симуляция начала давать сбои.
Откуда-то из глубин памяти я извлек структуру данных для пространственного индексирования под названием quadtree, или «квадродерево» (четырехмерное дерево). Вместо того чтобы хранить всех муравьев в одном большом списке, квадродерево позволяет сортировать их по местоположению и быстро задавать вопрос: «какие муравьи находятся внутри этой области?». Благодаря тому, что структура квадродерева обрабатывала эти пространственные запросы, мне удалось увеличить количество муравьев примерно в десять раз, сохранив при этом отзывчивость симуляции. Одно только это изменение не только спасло проект, но и заставило меня всерьез заинтересоваться квадродеревьями.
Проблема
Пакет quadtree, который я использовал для своего муравьиного симулятора, оказался полезным, но его значительный потенциал производительности оставался неиспользованным.
Python великолепно подходит для разработки приложений и машинного обучения, однако обычно он не является выбором номер один для низкоуровневых, кэш-эффективных структур данных. Реализации на чистом Python удобны: они не требуют дополнительных зависимостей, их легко читать, и их можно перенести почти куда угодно. Расплатой за это является то, что они редко приближаются к пиковой производительности, достижимой на таких языках, как C или Rust. Многие из самых популярных библиотек Python имеют значительную кодовую базу, написанную не на Python.
Поэтому я решил создать собственную гибридную библиотеку quadtree для Python. Цель состояла в том, чтобы построить высокоскоростное ядро на Rust для критичных к производительности операций, а затем соединить его с удобным Python API, который прост в использовании, но не допускает снижения производительности ядра. В итоге эта библиотека получила название fastquadtree.
Уже используете pyqtree? Смените один импорт. Сохраните весь ваш код. Получите ускорение в 6,5 раза.
from fastquadtree.pyqtree import Index # вот так
Основы квадродеревьев
Давайте разберемся, почему квадродеревья полезны для пространственных запросов в 2D.
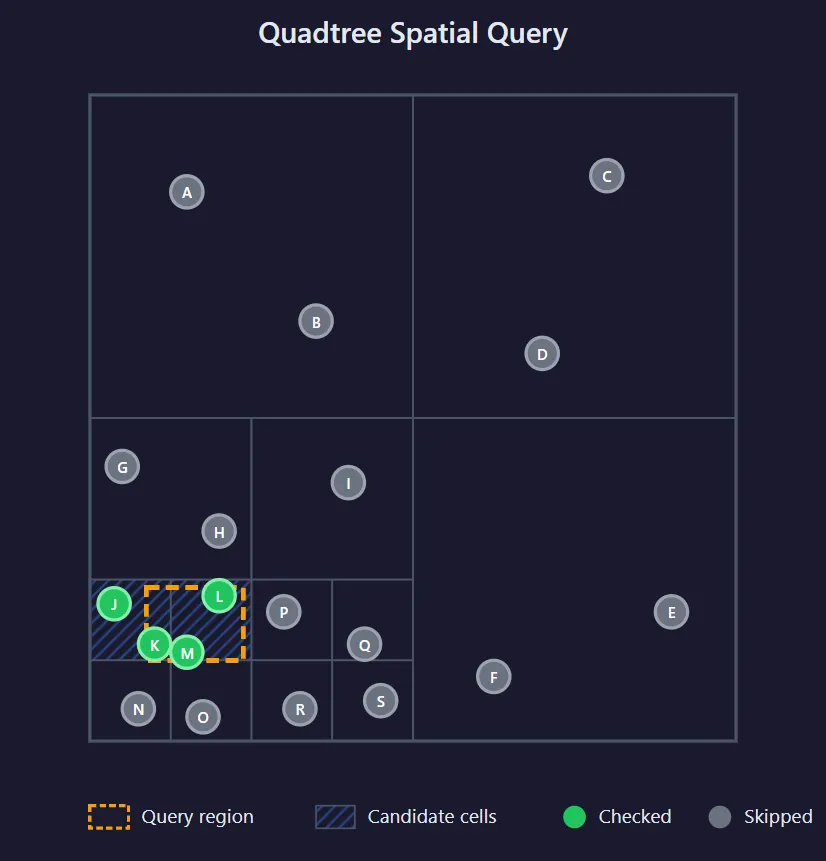
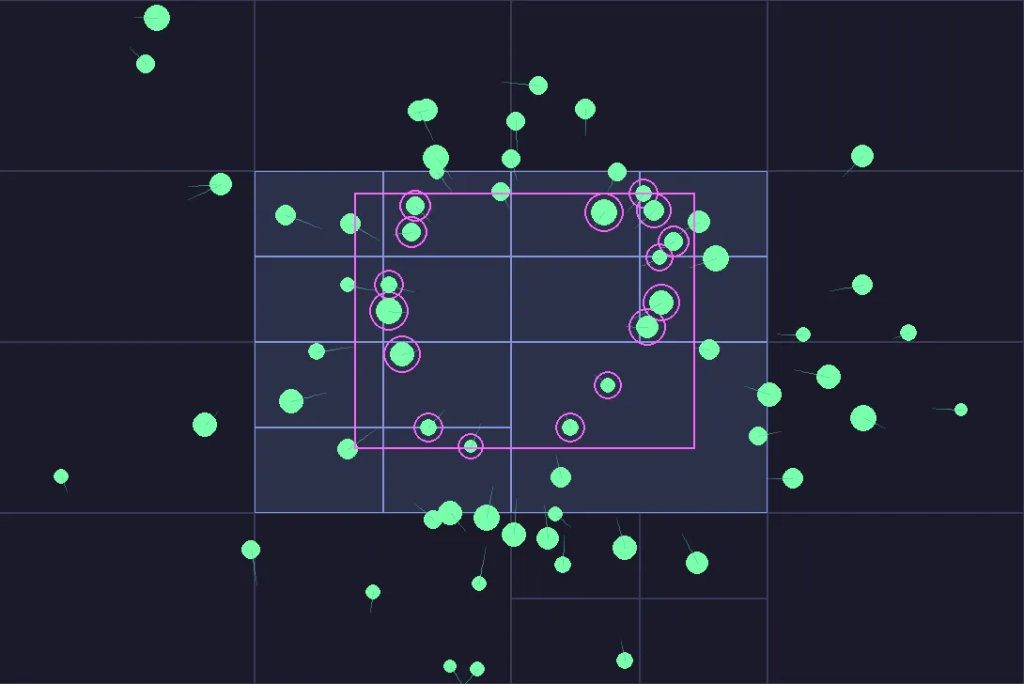
Квадродерево делится, когда данные становятся плотными. Когда ячейка превышает заданную вместимость (здесь — 2), она разделяется на четыре (отсюда и quad в слове «quadtree»). Таким образом, плотные области (например, нижний левый угол с 13 объектами) разбиваются на множество мелких ячеек, а разреженные зоны остаются крупными ячейками.
Для пространственного запроса важно минимизировать количество точных проверок точек. Как показано на схеме, оранжевый прямоугольник запроса пересекает только две ячейки, поэтому в качестве кандидатов рассматриваются только объекты в этих ячейках. Это сокращает количество точных проверок до 4 (J, K, L, M), причём объект J отбрасывается.
По сравнению с фиксированной сеткой, не нужно заранее выбирать размер ячейки. Если сетка слишком крупная, плотные ячейки могут замедлять запросы из-за большого числа сущностей. Если сетка слишком мелкая, тратится много памяти, и приходится получать объекты из большего числа ячеек. Квадродерево автоматически подстраивает размер ячейки в зависимости от локальной плотности.
Компромиссом является время построения: вставки могут вызывать разделения, поэтому построение проходит медленнее, чем в случае равномерной сетки. Но когда выполняется много запросов на одно построение, польза от оптимизации запросов обычно перевешивает этот недостаток.
Как работает fastquadtree?
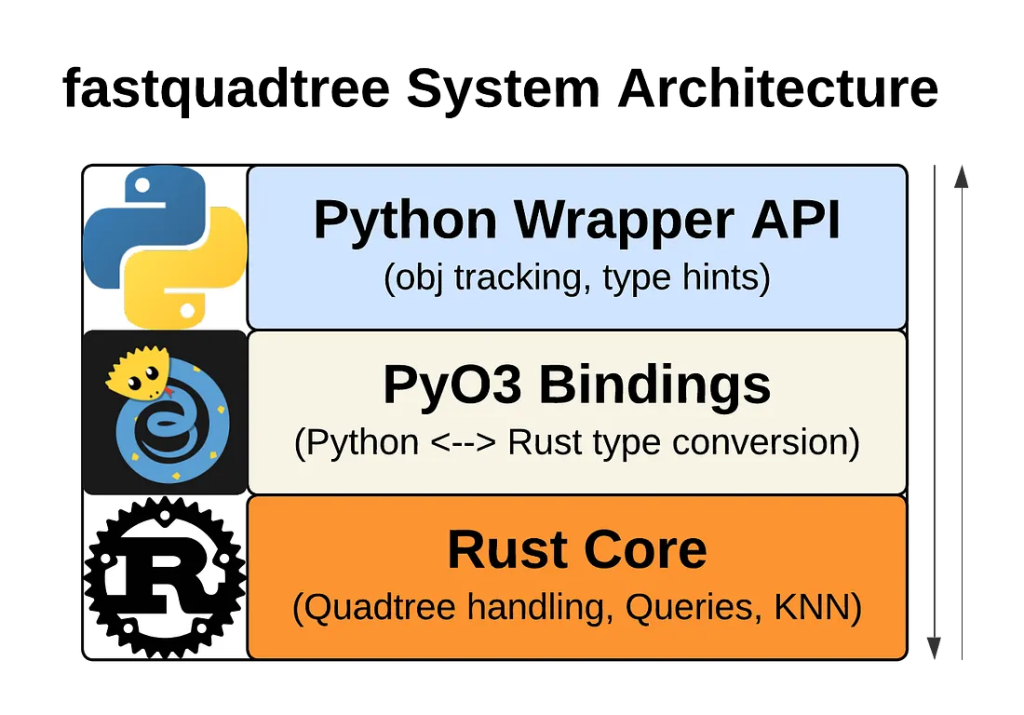
fastquadtree использует ядро на Rust и Python API, чтобы получить лучшее из обоих миров: сверхбыстрые операции и удобный интерфейс для разработчика.
Архитектура
- Python Wrapper API. Его задача — сделать API понятным и простым в использовании. Он предоставляет весь функционал Rust, включая вызовы NumPy (что позволяет пропустить этап построения списков в Python). Обертка также содержит высокооптимизированное хранилище объектов для отслеживания объектов, что дает множество полезных возможностей, например перемещение и удаление сущностей по ссылке объекта.
- PyO3 Bindings. Эти привязки обеспечивают взаимодействие между Python и Rust. Они преобразуют типы Python в их эквиваленты на Rust, позволяя эффективно передавать массивы NumPy через языковые границы.
- Rust Core. Это самый критичный к производительности уровень стека, отвечающий за все вычислительно сложные операции с квадродеревом. Именно здесь достигается основное ускорение по сравнению с реализациями на чистом Python.
Сериализация
fastquadtree поддерживает полную сериализацию, что позволяет сохранять квадродерево на диск или передавать между процессами. Ядро на Rust сериализуется с помощью Serde, а Python-обертка использует упаковку вручную через модуль struct. При желании пользователь может применить Pickle для хранения связанных Python-объектов.
Поиск k-ближайших соседей (KNN)
Помимо запросов по области, fastquadtree поддерживает запросы k-ближайших соседей. Это позволяет находить ближайшие точки к целевой точке (а для прямоугольников — ближайшие ограничивающие рамки), используя то же дерево, которое уже построено для запросов по диапазону.
Использование fastquadtree в Python
Давайте разберемся, как использовать fastquadtree в Python.
Установка
Установка предельно проста, потому что пакет поставляется в PyPI с предварительно собранными бинарными сборками для Windows, macOS и Linux (не требуется компиляция Rust на стороне пользователя). Поэтому просто выполните:
pip install fastquadtree
Быстрый пример:
from fastquadtree import QuadTree qt = QuadTree((0, 0, 1000, 1000), 16) qt.insert((100, 200), id_=1) print(qt.query((0, 0, 500, 500))) # [(1, 100.0, 200.0)]
Это элементарный пример, где точка вставляется в (100, 200). Затем выполняется запрос области от (0, 0) до (500, 500), и вставленная точка находится.
Более реалистичный пример:
from fastquadtree import QuadTree
class Person:
def __init__(self, x: float, y: float, name: str):
self.x = x
self.y = y
self.name = name
qt = QuadTree((0, 0, 1000, 1000), 16)
people = [
Person(100, 200, "Alice"),
Person(150, 250, "Bob"),
Person(300, 400, "Charlie"),
]
for idx, person in enumerate(people):
qt.insert((person.x, person.y), id_=idx)
# Находим людей в определенной области
results = qt.query((90, 190, 200, 300))
for id_, x, y in results:
person = people[id_]
print(f"Found {person.name} at ({x}, {y})")
# Вывод:
# Алиса найдена в (100.0, 200.0)
# Боб найден в (150.0, 250.0)
В этом примере мы помещаем Алису, Боба и Чарли в квадродерево на основе их местоположения и отслеживаем их с помощью индекса в списке people. Затем можем запросить область мира и получить обратно местоположение и ID каждого объекта, найденного в этой области.
Мы также могли бы вставлять людей напрямую, используя класс QuadTreeObjects, но это добавило бы чуть больше накладных расходов по сравнению с использованием индексов. Также есть опция RectQuadTree для хранения ограничивающих рамок вместо точек. Подробности смотрите в полной документации.
from fastquadtree import QuadTreeObjects
qt = QuadTreeObjects((0, 0, 1000, 1000), 16)
... # То же самое, что и раньше
for person in people:
# Связать объект с точкой
qt.insert((person.x, person.y), obj=person)
# Найти людей в определенной области
results = qt.query((90, 190, 200, 300))
for item in results:
print(f"Found {item.obj.name} at ({item.x}, {item.y})")
В целом, API для fastquadtree разработан интуитивно понятным и простым в использовании. Было приложено много усилий для обеспечения отличных подсказок типов (type-hints), чтобы избежать проблем во время выполнения. Полная документация API доступна здесь.
Производительность
В заголовке утверждается, что я создал самое быстрое квадродерево на Python, и я провел ряд комплексных тестов, чтобы это доказать. В них измерялись такие параметры, как время построения + время запроса среди всех найденных мной пакетов Python с квадродеревьями, а также некоторых реализаций rtree. Клонируйте репозиторий и запустите тесты самостоятельно.
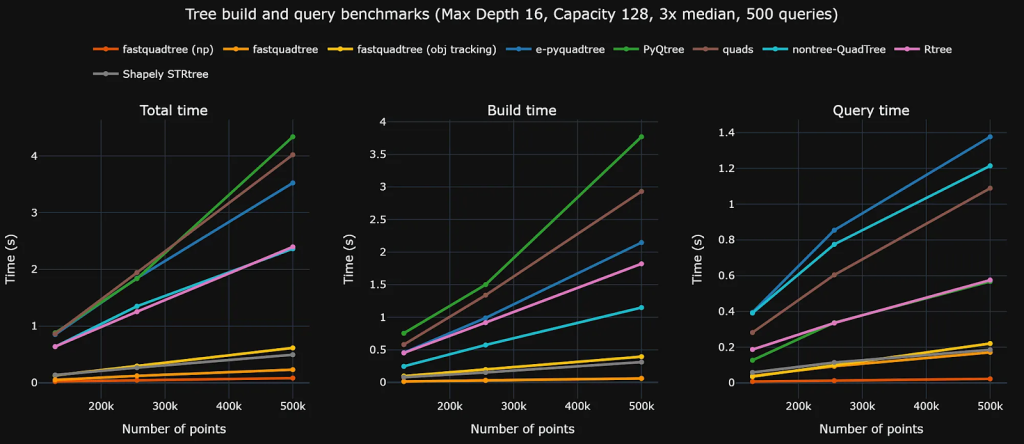
Сравнительный тест между библиотеками
- fastquadtree — самая быстрая в целом: общее время 0,067 с (0,050 с на построение и 0,017 с на выполнение всех 500 запросов).
Сравнение:
- fastquadtree: 0,050 с на построение, 0,017 с на запрос, 0,067 с — общее время, в 44,95 раза быстрее, чем pyqtree;
- Shapely STRtree: общее время 0.312 с, в 9,58 раза быстрее, чем pyqtree;
- pyqtree: общее время 2.992 с.
Важное замечание: при достижении этих лучших результатов используется самый быстрый путь, когда fastquadtree возвращает результаты через массивы NumPy (query_np) вместо создания множества объектов Python. Возврат массивов NumPy экономит много времени. Можете посмотреть сравнение производительности разных типов возвращаемых значений здесь.
А что насчет отслеживания объектов?
Если вам нужны привязки Python-объектов к точкам (чтобы можно было перемещать/удалять по ссылке и получать объекты в результатах), возникают дополнительные накладные расходы. В том же тесте вариант с отслеживанием объектов показывает общее время 0,467 с, что все еще ~в 6,5 раза быстрее, чем pyqtree, но медленнее, чем путь работы с числами, так как приходится поддерживать и обращаться к таблице поиска.
Другими словами, если вам не нужно отслеживание объектов, используйте более быстрый путь с привязкой только по ID и возвратом массивов NumPy.
Ускорение без изменений кода под названием «Я уже использую pyqtree»
Если у вас уже есть проект, построенный на pyqtree, вам не нужно ничего переписывать. Пакет включает в себя совместимую обертку fastquadtree.pyqtree.Index (которая имеет точно такой же интерфейс), что сокращает общее время с 24,221 с до 3,567 с в тесте, давая примерно 6,791-кратное ускорение без изменений кода.
Сериализация: сохраняйте деревья!
При 1 000 000 точек перестроение дерева из точек занимает 0,107 с, а восстановление из сериализованных байтов — 0,0218 с, что примерно в 4,91 раза быстрее. Сериализованный блок данных в этом запуске занимал 13 770 328 байт (~13,8 МБ). Вместо передачи необработанных точек между процессами вы можете передавать сериализованное квадродерево, экономя при этом уйму времени.
Сферы применения
Используйте fastquadtree, если у вас большое количество точек и нужно выполнять множество запросов по областям или по ближайшим соседям (KNN). Вот несколько примеров, где возникает такая потребность:
- Игры и симуляции: объекты широкофазных столкновений, проверки близости, ИИ-зрение/aggro, триггеры областей, попадания пуль.
- Интерактивные инструменты: окна просмотра карт или редакторов, выделение лассо, выбор при наведении и клике, фильтрация и рисование «кистью».
- Пространственный анализ: повторяющиеся запросы по окну для больших наборов точек (тепловые карты, предварительные этапы кластеризации, подсчеты по областям).
Эта библиотека не очень подойдет, если вы выполняете всего несколько запросов (простой перебор списка может оказаться быстрее в целом), или если ваши данные лучше моделировать в виде сложных полигонов, а не точек.
Заключение
То, что начиналось как спасительное средство для ускорения муравьиного симулятора, превратилось в глубокое погружение в Rust, привязки Python и управление пакетами, кульминацией чего стала разработка полноценной библиотеки. fastquadtree существует потому, что я хотел получить всю мощь квадродерева на Rust, не покидая экосистему Python. fastquadtree активно поддерживается, и вклад в эту библиотеку приветствуется.
Читайте также:
- Rust против JavaScript: повышение производительности на 66 % с помощью WebAssembly
- История успеха FastAPI: как личный проект Себастьяна Рамиреса изменил экосистему Python
- Создание базы данных на Rust
Читайте нас в Telegram, VK и Дзен
Перевод статьи Ethan Anderson: fastquadtree: How I used Rust to make the fastest Python Quadtree

 в Node.js и Express App")



