

Последние исследования показывают, что большие языковые модели (LLM) становятся более продвинутыми в прогнозировании будущего. Хотя меня это не удивляет, я скептически отношусь к тому, что эти успехи смогут существенно превзойти оптимальные человеческие прогнозы. И уж точно не жду, что LLM предскажут траекторию человеческой истории с точностью физика.
Все потому, что наблюдения LLM в принципе ограничены анализом языка, а этого, как я покажу, недостаточно для надежного долгосрочного прогнозирования.
Мы все знаем, что значения слов со временем меняются. Язык — это не какая-то метафизическая данность. Просто почитайте Чосера или Шекспира, если не верите. Тем не менее, как и стоимость доллара, значение слова определяется и переопределяется в миллиардах «сделок» каждый день, что придает ему определенную стабильность.
Именно эта стабильность делает LLM возможными. Ведь нельзя предсказать следующее слово в предложений, если не сформированы четкие представления о том, какие слова обычно сочетаются. Эти взаимосвязи в предложении существуют, потому что слова, как правило, имеют устойчивые значения.
Но так же, как стоимость валюты может кардинально измениться — вспомните инфляцию в Веймарской Германии — значение слова может претерпеть быструю и непредсказуемую трансформацию. Сколько людей, живших в 1990-х, могли предсказать, что будет означать слово «телефон» всего двадцать лет спустя?
Такие смысловые сдвиги происходят по причинам, связанным с технологическими и культурными тенденциями, которые лишь частично можно понять и усвоить через язык. Это значит, что сам по себе язык недостаточно определяет то, какие в конечном итоге у нас сложатся представления о конкретных результатах этих тенденций.
Другими словами, трансформация языка — это запаздывающий, а не опережающий индикатор технологических и культурных трансформаций. Поэтому, если вы понимаете, как работают LLM, поймете, почему они не могут предвидеть очередной смысловой сдвиг.
Векторные эмбеддинги: превращаем слова в математику
Чтобы понять, почему LLM не могут предвидеть смысловые сдвиги в языке, нужно прежде всего разобраться с векторными эмбеддингами, которые позволяют ИИ формировать представления и находить слова и фразы, используемые для генерации контента. В случае LLM, обученной исключительно на тексте (в отличие от ИИ, обученного на изображениях или аудио), эти векторные эмбеддинги иногда называют просто «векторными представлениями слов» (word embeddings).
Вот как это объясняет инженер IBM Мартин Кин:
«Векторные представления слов описывают слова числами, а именно числовыми векторами, таким образом, чтобы можно было уловить их семантические связи и контекстную информацию. Это значит, что слова со схожим значением расположены близко друг к другу, а расстояние и направление между векторами кодируют степень сходства слов.
Векторные представления слов создаются путем обучения моделей на большом корпусе текстов… Модель обучается предсказывать [слова] на основе их контекста, располагая семантически близкие слова рядом в векторном пространстве. В процессе обучения параметры модели корректируются для минимизации ошибок предсказания».
Это довольно точное описание, но чтобы лучше усвоить, как работают векторные представления, давайте взглянем на упрощенную визуализацию.
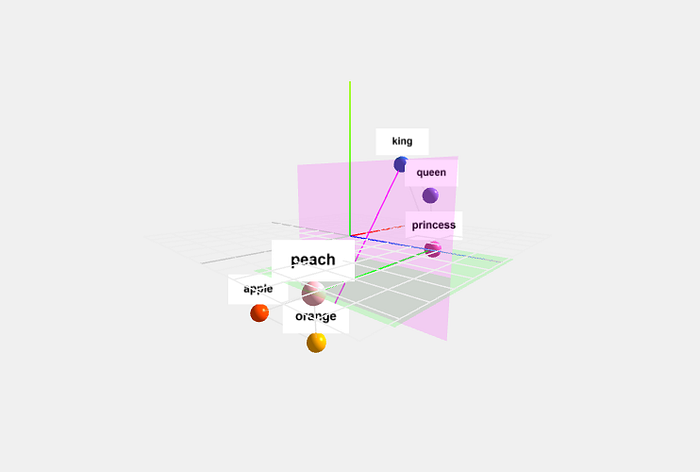
На этой диаграмме показано взаимное расположение в векторном пространстве слов «king» (король), «queen» (королева), «princess» (принцесса), «apple» (яблоко), «orange» (апельсин) и «peach» (персик). Обратите внимание, что первые три слова образуют собственный кластер «королевской семьи», а последние три — кластер «фруктов». Тем не менее, существует по меньшей мере одно измерение — зеленая плоскость, — которое связывает «princess» и «peach», поскольку эти слова связаны по смыслу как минимум в одном контексте: компьютерная игра Super Mario Bros., в которой есть персонаж Princess Peach (Принцесса Персик). А слова «king» и «orange» соединены розовой линией, которая символизирует историческую личность — короля Вильгельма III Оранского (king William of Orange).
Разумеется, эта диаграмма очень упрощенная. Большинство слов представлены сотнями, если не тысячами измерений, и очевидно, что невозможно изобразить это визуально. Но общий принцип ясен.
После того, как словам присвоены числовые значения, позволяющие представлять их таким образом, их можно хранить в так называемой векторной базе данных. Именно относительное расстояние и направление между словами позволяет нам «искать» в этой базе, используя запросы на естественном языке (промпты), и получать ответ на естественном языке от языковой модели.
Миграция смысла
Итак, массовое использование LLM широкой публикой насчитывает всего несколько лет. Этого периода действительно недостаточно для сколько-нибудь значительных языковых изменений. Но ученые все равно могут использовать технику векторных эмбеддингов, чтобы заглянуть в прошлое и увидеть, как языки эволюционировали на протяжении веков.
В статье «Диахронические векторные представления слов выявляют статистические законы семантических изменений» (Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change) Гамильтон, Лесковец и Юрафски проанализировали шесть больших текстовых корпусов на четырех разных языках, охватывающих период в два столетия. Они создали модели, подобные показанной выше — только гораздо более сложные, — которые демонстрируют, как слова мигрируют в векторном пространстве с течением времени. В процессе работы исследователи обнаружили нечто очень интересное.
Значения слов меняются не как попало. Значения наиболее употребительных слов — таких как «the» (определенный артикль), «and» (и) или «you» (ты/вы) — обладают высокой степенью устойчивости. Слова, реже употребляемые, напротив, с большей вероятностью обретают новые значения со временем. Исследователи назвали это «законом соответствия» (law of conformity).
Слова, имеющие несколько значений — лингвисты называют их «многозначными» — более склонны к изменению смысла, чем слова с единственным значением, независимо от частоты их употребления. Исследователи назвали это «законом обновления» (law of innovation).
Эти выводы логичны. Как я отмечал ранее, устойчивость значения слова, как и устойчивость валюты, во многом обусловлена его использованием в бесчисленных «сделках» каждый день. Это согласуется с «законом соответствия». И чем больше люди привыкают воспринимать слово гибко — потому что оно уже имеет два или более значения — тем проще становится применять его в новых контекстах.
Но если можно проследить изменение языка в прошлом благодаря этим статистическим законам, значит ли это, что можно предсказать, как язык изменится в будущем? Можно ли предсказать будущее, хотя бы в общих чертах, предсказав, как люди будущего будут говорить и писать?
Возможности и случайности
Если коротко, то нельзя. Учтите, это лишь статистические законы. Если бы мы, скажем, рассмотрели весь корпус текстов, созданных людьми за последние 50 лет, Гамильтон и его коллеги могли бы сказать, какие слова с большей вероятностью изменят свое значение в будущем, но не смогли бы точно предсказать, какие именно. Они также не смогли бы сказать, в каком направлении произойдут эти изменения.
В 1975 году, за десять лет до выхода игры Super Mario Bros., можно было бы вычислить вероятность того, что слова «princess» и «peach» сблизятся. Но вы не смогли бы предсказать, что их миграция в векторном пространстве идеально выстроит их вдоль именно той оси, которая определяет персонажа Princess Peach.
Это важный момент, но не главный. До сих пор речь шла о том, что статистические законы — не то же самое, что детерминистические. Углубленное исследование показывает, почему изучение одного лишь языка и его эволюции не может дать достаточно информации, необходимой для предсказания будущих событий.
Чтобы прояснить эту мысль, вернемся к примеру со словом «телефон». Когда телефоны только были изобретены, они существовали исключительно для устного общения на больших расстояниях. Первые сотовые телефоны лишь повторили эту функцию. Однако конструкция сотовых телефонов позволила вводить не только цифры, но и буквы, что естественным образом натолкнуло на идею отправки текстовых сообщений.
Эта тактильная, зрительно-моторная связь между пользователем и телефоном также открыла другие возможности, поэтому были добавлены первые простые игры для мобильных телефонов, такие как Snake («Змейка») или Tetris («Тетрис»). По мере совершенствования технологий, более точная графика и более чуткий отклик на управление касанием открыли целые горизонты новых приложений, которые первые пользователи изобретения Александра Грейама Белла не могли даже вообразить.
Этот пример иллюстрирует два понятия, которые являются фундаментальными для моей аргументации. Первое — «возможность» (affordance). Второе — «случайность» (contingency).
Психолог Джеймс Гибсон определил понятие «возможность» как некий аспект окружающей среды, который предоставляет индивиду определенные возможности для действия. Например, стул предоставляет возможность сидеть. Наши физиологические особенности часто предоставляют поведенческие возможности, которые отличаются от причин, по которым особенности изначально эволюционировали, позволяя им служить своего рода «эволюционным фундаментом».
Самые первые телефоны не были рассчитаны на то, чтобы на них смотреть — в них говорили. Однако создание портативного телефона потребовало разработки устройства, которое можно было бы держать на расстоянии. Это был первый небольшой шаг от устного способа взаимодействия с телефоном к зрительно-моторному. И этот сдвиг продолжался, поскольку каждый шаг в эволюции дизайна телефона предоставлял новые возможности для использования нашей моторики и богатства нашего визуального восприятия.
А теперь сравните понятие «возможность» с понятием, которое палеонтолог Стивен Джей Гулд называл «случайностью», исходя из того, что путь эволюции формируется непредсказуемыми событиями. Если бы перемотать назад историю Вселенной и позволить ей развернуться заново, эволюционировали бы совершенно иные формы жизни.
Возможно, в другой временной шкале то, что мы сейчас называем «телефоном», называлось бы как-то иначе, потому что, возможно, в той шкале его первым применением была бы отправка текстовых сообщений, а не звонки. В этом случае он произошел бы от другой технологии и унаследовал бы имя своего предка, а не то имя, которое имеет сейчас.

Воплощенный разум, а не просто встроенные слова
А теперь объединим эти два понятия — возможности и случайности. Люди отчасти познают мир через язык, но на самом деле язык — лишь верхушка когнитивного айсберга. Человек является тем, что некоторые психологи называют «воплощенным разумом» (embodied minds): наши восприятия и мысли формируются нашими телами бесчисленными способами, которые затем просачиваются в наш язык.
Наша «воплощенность» (embodiedness) — каркас, на котором построен язык. Но это означает, что природа и направление эволюции языка лишь отчасти определяются тем, как язык развивался в прошлом. Они также определяются тем, как наши тела взаимодействуют с миром. Эволюция «телефона» иллюстрирует это. Она включала возможности и случайности, которые анализ одного лишь языка мог бы выявить лишь задним числом (after the fact).
В своей песне «На дне всего» (At the Bottom of Everything) фронтмен группы Bright Eyes Конор Оберст (Conor Oberst) поет: «Мы должны смотреть в хрустальный шар и видеть лишь прошлое». Это примерно то, на что похоже общение с LLM. Ее архитектура позволяет ей экстраполировать будущие тенденции в эволюции языка, основываясь лишь на прошлой эволюции векторных представлений слов.
Но возможности, которые порождают случайности, которые, в свою очередь, определяют историю человечества — включая эволюцию нашего языка — не различимы на таком абстрактном уровне анализа. Они слышатся, обоняются и постигаются на уровне наших тел.
Возможно, однажды искусственный интеллект обретет собственное тело и будет опираться на богатое, воплощенное сознание (embodied consciousness), чтобы формулировать свои семантические утверждения о мире. Когда этот день настанет, мне, вероятно, придется пересмотреть свой тезис. А до тех пор лучше всего прислушаться к мудрости Йоги Берры (Yogi Berra) — в прошлом американского бейсболиста, ставшего сегодня спортивным менеджером:
«Трудно делать предсказания, особенно о будущем».
Читайте также:
- Искусственный интеллект и машинное обучение
- Что мы теряем, когда экономим творческие усилия
- Машинное обучение. С чего начать? Часть 2
Читайте нас в Telegram, VK и Дзен
Перевод статьи Dustin Arand: Why AI Can’t Predict the Future
 улучшить написание кода на Swift")




