
Я уже не могу зайти в LinkedIn, чтобы не увидеть рекламу какого-нибудь менеджера по продуктам о том, что время агентов ИИ «не за горами».
Я работал с большими языковыми моделями еще до разработки ChatGPT, когда GPT-3 на сайте OpenAI только предсказывал следующие слова в предложении (в отличие от привычного сейчас интерфейса чата).
Я с нуля создавал приложения с поддержкой ИИ и обучал все типы моделей ИИ. Я прослушал курсы по глубокому обучению и получил степень магистра в университете Карнеги-Меллона — лучшем в мире центре исследования ИИ и компьютерных наук.
И все же, когда я вижу очередное видео в ленте TikTok, не могу не скривиться и не вспомнить о том, как «Web 3 должен был изменить интернет».
Это не иначе как результат работы ферм ботов, технически необразованных людей и рекламы, искусственно раздуваемой OpenAI для увеличения финансирования. Cколько вы знаете инженеров-программистов, выпустивших готовых к производству агентов ИИ? Скорее всего, ни одного.
Вот почему вся эта рекламная шумиха — полная чушь.
Что такое «агент ИИ»?
Термин «агент» на самом деле имеет долгую историю в области исследования искусственного интеллекта. С момента появления ChatGPT этим термином стали обозначать большую языковую модель, структурированную для рассуждений и автономного выполнения задач.
Эту модель можно точно настроить с помощью обучения с подкреплением. Однако на практике обычно используют GPT от OpenAI, Gemini от Google или Claude от Anthropic.
Разница между агентом и языковой моделью заключается в том, что агенты выполняют задачи автономно.
Вот пример: у меня есть платформа для алгоритмического трейдинга и финансовых исследований NexusTrade. Допустим, я захотел перестать платить внешнему поставщику данных за получение фундаментальных данных по американским компаниям.
При использовании традиционной языковой модели мне пришлось бы написать код, который бы с ней взаимодействовал. Это выглядело бы следующим образом:
- Создание скрипта, который извлекает данные с сайта SEC или использует репозиторий GitHub для получения информации о компаниях (в соответствии с рекомендацией о 10 запросах в секунду в условиях предоставления услуг).
- Использование библиотеки Python, например pypdf, для преобразования PDF-файлов в текст.
- Отправка полученного текста в большую языковую модель для форматирования данных.
- Валидация ответа.
- Сохранение ответа в базе данных.
- Повторение для всех компаний.
Используя агента ИИ, теоретически можно просто сказать ему: «Собери прошлые и будущие исторические данные по всем компаниям США и сохрани их в базе данных MongoDB».
Возможно, он задаст вам несколько уточняющих вопросов. Возможно, спросит, как должна выглядеть схема или какая информация является наиболее важной. Но идея заключается в том, что вы ставите перед ним задачу, а он выполняет ее полностью автономно.
Звучит слишком хорошо, чтобы быть правдой? Так оно и есть.
Проблема с агентами ИИ на практике
Если бы самая дешевая и компактная языковая модель была бесплатной, такой же надежной, как Claude 3.5, и запускаемой локально на любом AWS-инстансе T2, то эта статья была бы написана в совершенно ином ключе.
Это была бы не критика. Это было бы предупреждение.
Однако на данный момент агенты ИИ не работают в реальном мире, и вот почему.
1. Недостаточная эффективность моделей небольшого размера
Основная проблема агентов заключается в том, что они полагаются на большие языковые модели.
Точнее, они полагаются на эффективную модель.
GPT-4o mini — самая дешевая модель, поддерживающая множество языков, за исключением Flash, — имеет потрясающую стоимость.
Но и эта модель недостаточно эффективна для выполнения реальных агентских задач.
Она будет отклоняться, забывать о своих целях или просто совершать ошибки, как бы хорошо ее ни обучили.
Если же ее развернуть в реальном времени, ваш бизнес поплатится за это. Ошибку, совершаемую большой языковой моделью, не так-то просто обнаружить, если только не создать (скорее всего, на основе LLM) систему проверки. Одна небольшая ошибка, допущенная в самом начале, — и вся последующая работа будет загублена.
Вот чем это оборачивается на практике.
2. Усугубление ошибок
Предположим, вы используете GPT-4o-mini для агентской работы.
Ваш агент разбивает задачу сбора финансовой информации о компании на более мелкие подзадачи. Допустим, вероятность того, что он правильно выполнит каждую подзадачу, составляет 90 %.
При этом ошибки усугубляются. Если задачу даже умеренной сложности разбить на 4 подзадачи, вероятность того, что конечный результат будет верным, крайне мала, поскольку:
- вероятность выполнения одной подзадачи составляет 90 %;
- вероятность выполнения двух подзадач составляет 0,9*0,9 = 81 %;
- вероятность выполнения четырех подзадач составляет 66 %.
Чтобы хотя бы частично решить эту проблему, нужно использовать более совершенную языковую модель. Более эффективная модель может повысить точность выполнения каждой подзадачи до 99 %. После выполнения четырех подзадач итоговая точность составит 96 %. Намного лучше (но все же не идеально).
Самое главное, что переход на эти более эффективные модели влечет за собой увеличение затрат.
3. Резкое возрастание расходов
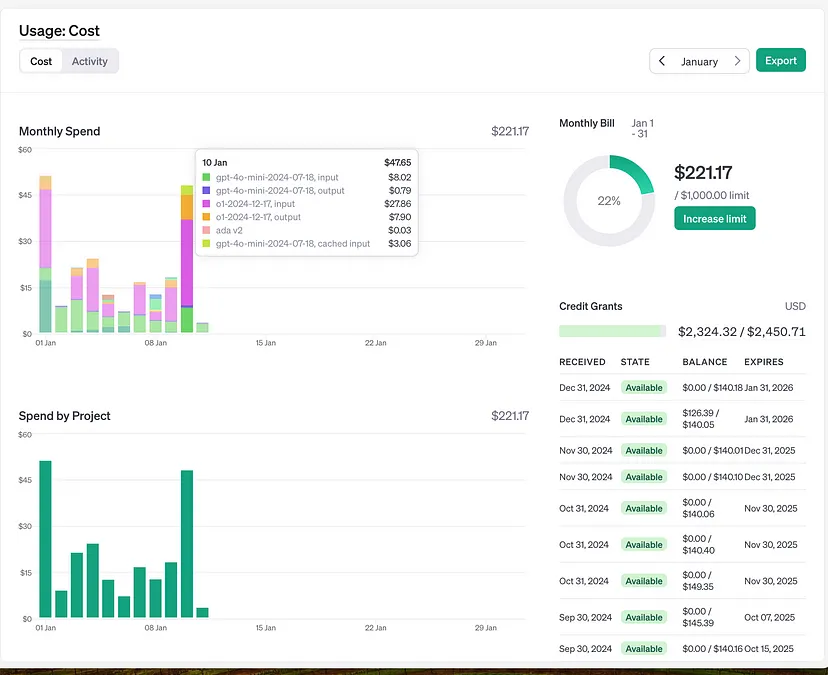
Судя по этому графику, как только вы перейдете на более мощные модели OpenAI, ваши затраты резко возрастут.
Сиреневая и оранжевая колонки — стоимость модели o1 от OpenAI. Я использую ее примерно 4-5 раз в день для очень интенсивных задач, таких как генерация синтаксически корректных запросов для анализа акций.
Лимонно-зеленая и темно-синяя колонки — стоимость GPT-4o-mini. Эта модель мониторит сотни запросов ежедневно, а ее конечные затраты составляют малую долю от затрат на o1.
Более того, даже после проведения всей этой работы вам все равно нужно подтвердить итоговый результат. По тем же причинам вы будете использовать более надежные модели для проверки.
Таким образом, вам придется использовать более крупные модели для агента и более крупные модели для проверки.
Видите, почему я думаю, что это заговор OpenAI?
Наконец, переход от работы с кодом к работе с моделями имеет массу побочных эффектов.
4. Выполнение работы с недетерминированными результатами
При использовании LLM-агентов вся парадигма вашей работы смещается в сторону подхода, применяемого в науке о данных.
Вместо того чтобы писать детерминированный код, который обходится дешево и может выполняться повсеместно на Arduino (или, на практике, на микроинстансе T2 от AWS), вы пишете недетерминированные промпты для модели, работающей на кластере графических процессоров.
Если «повезет», вы будете использовать собственные графические процессоры с точно настроенными моделями, но содержание агентов для выполнения простых задач все равно будет стоить вам немалых денег.
Если же не повезет, вы будете полностью привязаны к OpenAI; ваши промпты не будут работать напрямую при попытке перейти на другую модель, и платформа будет постепенно повышать цену, пока вы выполняете критические бизнес-процессы с использованием ее API.
Прежде чем вы решите, что «можете использовать OpenRouter для беспроблемного перехода с одной модели на другую», подумайте еще раз. Выходные данные модели Anthropic отличаются от выходных данных моделей OpenAI.
Таким образом, вам придется перепрограммировать весь свой стек, что выльется в кругленькую сумму, только чтобы получить незначительное улучшение итоговой производительности для другого LLM-провайдера.
Видите, в чем проблема?
Заключительные мысли
Я почти уверен, что посты об агентах пишут люди, которые никогда не использовали языковые модели на практике.
И это, как понимаете, приводит меня в бешенство.
Я не утверждаю, что у ИИ нет вариантов использования. Через несколько лет агенты могут пригодиться инженерам для написания простого кода.
Но ни одна нормальная компания не заменит свой проектный отдел набором чрезвычайно дорогих, склонных к ошибкам агентов для выполнения критически важных бизнес-процессов.
А если какая-то фирма и попытается это сделать, через пару лет мы все станем свидетелями ее банкротства. Этот случай войдет в учебники по бизнесу и принесет OpenAI дополнительный доход в размере 1 миллиарда долларов.
Читайте также:
- 15 бизнес-идей агентов на основе ИИ в 2025 году
- Как работает искусственный интеллект
- Интеллектуальная синергия: динамические отношения между искусственным и человеческим интеллектом
Читайте нас в Telegram, VK и Дзен
Перевод статьи Austin Starks: You are an absolute moron for believing in the hype of “AI Agents”





