
Асинхронный поток для вас загадка? Чтобы полностью его освоить, напишите собственный.
Асинхронное программирование стало доступным большинству разработчиков благодаря парадигме async/await. Код похож на классический блокирующий поток из-за создания компилятором сложного конечного автомата.
Слоем ниже в Rust используются опрашивание, будильщики, фиксация. Этими компонентами не применяется синтаксис async/await, но при этом в полном объеме обеспечивается неблокирующая конкурентность. Отсутствие сгенерированного конечного автомата компенсируется написанием собственного, увеличением производительности, полным контролем над рабочим кодом.
Один из примеров, когда хочется и нужно быть на уровне опроса, — асинхронные потоки. Идеально интегрируясь в мир async/await, они остаются настоящей неблокирующей реализацией в фоновом режиме без больших накладных расходов.
Напишем поток фрагментов двоичного файла для исходящего tar-архива, создадим сложный конечный автомат, попробуем продемонстрировать итоговый результат и интегрировать его в процесс загрузки файлов в запущенный контейнер с API среды выполнения Docker.
Асинхронные потоки очень похожи на обычные итераторы, которыми часто проходят коллекции. Например, напишем обычный цикл for для идиоматического прохождения коллекции:
fn main() {
let numbers = vec![1, 2, 3, 4, 5];
for number in numbers.iter() {
println!("Number: {}", number);
}
}
Фактически это эквивалентно такому синтаксису, где временно созданный итератор — изменяемая переменная:
fn main() {
let numbers = vec![1, 2, 3, 4, 5];
let mut iter = numbers.iter();
while let Some(number) = iter.next() {
println!("Number: {}", number);
}
}
Проходимся по вектору, поэтому супербыстро. Следующей функцией не выполняется никаких операций ввода-вывода. А что, если итератором выдаются числа или сетевые подключения? Чтобы воспользоваться async/await, изменим пару строк:
#[tokio::main]
async fn main() {
let mut numbers = fetch_numbers();
while let Some(number) = numbers.next().await {
println!("{}", number);
}
}
Практически обычный итератор, на самом же деле это асинхронный поток.
Посмотрим, как появляются еще не реализованные типажи:
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
pub trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>
) -> Poll<Option<Self::Item>>;
}
Сходство очевидно: и там и тут определяется возвращаемый тип элемента, сопоставляемый в цикле while, требуется код для указания в следующей функции следующего выдаваемого элемента.
Что же такое tar и как он связан с асинхронными потоками на Rust? tar — способ объединения файлов и каталогов в один файл. Этот файловый формат тесно связан с историей ленточных накопителей, бывших на заре компьютерных вычислений одной из форм хранения данных. Он предназначен для ленточного запоминающего устройства, а название — сокращение от Tape ARchive («Ленточный архив»).
Чтобы создать tar-архив, обрабатывается несколько файлов, для каждого из которых создается заголовок в 512 байт. Затем добавляется содержимое файла с дополнением, если необходимо, в 512 байт. Много файлов, значит, много операций ввода-вывода. Где, как не здесь, требуются асинхронные потоки?
Начнем с простого tar-заголовка ровно в 512 байт, которым кодируется много информации о едином файле Cargo.toml:
00000000: 4361 7267 6f2e 746f 6d6c 0000 0000 0000 Cargo.toml......
00000010: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000030: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000040: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000050: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000060: 0000 0000 3030 3030 3634 3400 3030 3031 ....0000644.0001
00000070: 3735 3000 3030 3031 3735 3000 3030 3030 750.0001750.0000
00000080: 3030 3030 3037 3000 3134 3537 3136 3533 0000070.14571653
00000090: 3534 3000 3031 3233 3435 0020 3000 0000 540.012345. 0...
000000a0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000000b0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000000c0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000000d0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000000e0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000000f0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000100: 0075 7374 6172 2020 0076 7363 6f64 6500 .ustar .vscode.
00000110: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000120: 0000 0000 0000 0000 0076 7363 6f64 6500 .........vscode.
00000130: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000140: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000150: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000160: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000170: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000180: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000190: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000001a0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000001b0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000001c0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000001d0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000001e0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000001f0: 0000 0000 0000 0000 0000 0000 0000 0000 ................
Глядя в документацию, попробуем расшифровать закодированное:
- Название файла: Cargo.toml.
- Разрешения файла: 0000644, закодировано как восьмеричная строка.
- Пользователь и группа: 0001750, закодировано как восьмеричная строка.
- Размер файла: 0000070, закодировано как восьмеричная строка -> 56 байт.
- Временнáя метка файла: 14571653540, закодировано как восьмеричная строка -> 1709660000.
- Контрольная сумма заголовка: 012345, закодировано как восьмеричная строка.
Другие, необязательные данные файла при генерировании заголовка игнорируем.
Напишем базовый код Rust. Сначала определяем структуры и пример их использования без фактической реализации, создаем новый экземпляр структуры TarArchive, добавляем названия файлов:
enum TarEntry {
File(String),
}
struct TarArchive {
entries: Vec<TarEntry>,
}
impl TarArchive {
fn new() -> Self {
Self { entries: Vec::new() }
}
fn append_file(&mut self, file: String) {
self.entries.push(TarEntry::File(file));
}
}
В архиве содержатся только записи, подлежащие архивации. Теперь добавляем возможность преобразования его в поток, так архив используется:
impl TarArchive {
...
fn into_stream(self, buffer_size: usize) -> TarStream {
TarStream::new(self.entries, buffer_size)
}
}
struct TarStream {
buffer_size: usize,
entries: VecDeque<TarEntry>,
}
impl TarStream {
fn new(entries: Vec<TarEntry>, buffer_size: usize) -> Self {
Self {
buffer_size: buffer_size / 512 * 512,
entries: entries.into(),
}
}
}
Поток почти создан. Недостает лишь самого кода типажа Stream, а реализации типажа требуется определение, что такое элемент потока:
enum TarChunk {
Header(String, Box<[u8; 512]>),
Data(Vec<u8>),
Padding(usize),
}
enum TarError {}
type TarResult<T> = Result<T, TarError>;
impl Stream for TarStream {
type Item = TarResult<TarChunk>;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> {
todo!()
}
}
Возвращается фрагмент с тремя вариантами:
- заголовок
headerс названием файла и 512 байт полезной нагрузки; - данные
data, то есть срез считанного файла, но согласно документации может содержаться и дополнение; - собственно дополнение
padding— в конце каждого tar-архива всегда отправляется два пустых фрагмента.
Напишем из этой заготовки получателя. Возможно, достаточно вывести на консоль то, что происходит.
Следующим кодом генерируется tar-архив для трех файлов, показывается только ход выполнения в интерактивном режиме без записи архива:
#[tokio::main]
async fn main() {
let mut archive = TarArchive::new();
archive.append_file("enwiki-20230801-pages-meta-history27.xml-p74198591p74500204".to_owned());
archive.append_file("lubuntu-22.04.3-desktop-amd64.iso".to_owned());
archive.append_file("qemu-8.2.1.tar.xz".to_owned());
let mut stream = archive.into_stream(10 * 1024 * 1024);
while let Some(chunk) = stream.next().await {
match chunk {
Ok(TarChunk::Header(path, _)) => println!("\nheader {path}"),
Ok(TarChunk::Data(_)) => print!("."),
Ok(TarChunk::Padding(0)) => println!("\npadding 0"),
Ok(TarChunk::Padding(index)) => println!("padding {index}"),
Err(error) => println!("error: {:?}", error),
}
std::io::stdout().flush().unwrap();
}
}
Вот какой вывод получается на моем компьютере:
header enwiki-20230801-pages-meta-history27.xml-p74198591p74500204
.........................................................................
.........................................................................
.........................................................................
.........................................................................
.........................................................................
.........................................................................
.............................................................
header lubuntu-22.04.3-desktop-amd64.iso
.........................................................................
.........................................................................
.........................................................................
............................................................
header qemu-8.2.1.tar.xz
.............
padding 0
padding 1
Количество точек представляет собой фрагмент данных каждые 10 Мб, приложение запускается считанные секунды.
Чтобы достигать такого результата в реализации и знать, где мы в конечном автомате, добавим к потоку поле состояния:
struct TarStream {
state: TarState,
...
}
impl TarStream {
pub fn new(entries: Vec<TarEntry>, buffer_size: usize) -> Self {
Self {
state: TarState::init(),
...
}
}
}
impl Stream for TarStream {
...
fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> {
let self_mut = self.get_mut();
loop {
let mut state = TarState::completed();
mem::swap(&mut state, &mut self_mut.state);
let result = match state {
TarState::Init(state) => state.poll(cx),
TarState::Open(state) => state.poll(cx),
TarState::Header(state) => state.poll(cx),
TarState::Read(state) => state.poll(cx),
TarState::Padding(state) => state.poll(cx),
TarState::Completed(state) => state.poll(cx),
};
let (state, poll) = match result {
TarPollResult::ContinueLooping(state) => (state, None),
TarPollResult::ReturnPolling(state, poll) => (state, Some(poll)),
TarPollResult::NextEntry() => match self_mut.entries.pop_front() {
None => (TarState::padding(), None),
Some(entry) => (TarState::open(self_mut.buffer_size, entry), None),
},
};
self_mut.state = state;
if let Some(poll) = poll {
return poll;
}
}
}
}
Каждым вариантом состояния получается опрос, а возвращается результат опроса, на основе которого принимается решение: продолжить итерирование, вернуть найденный результат опроса или перейти к следующей записи. Каждый раз текущее состояние обновляется.
Но что именно представляет собой опрашивание? С одной стороны, нас опрашивают при реализации асинхронного потока, с другой — мы делегируем опрашивание другим опрашиваемым сущностям. Каждой функцией опроса принимается контекст, а возвращается вариант опроса.
В контексте содержится будильщик для возобновления блокированной задачи. Но важнее понять два варианта перечисления опроса: отложенный Pending и готовый Ready.
Отложенным указывается, что процесс опрашивания не завершен. Когда из функции получается этот вариант, нужно не опрашивать тут же заново, но подождать еще. Если получается готовый — искомое значение найдено.
Надеюсь, предыдущий листинг стал понятен. А зачем нужен конечный автомат? Представьте: кто-то вызывает функцию опроса, а вы возвращаете отложенный Pending. То есть обещаете уведомить вызывающего, когда можно будет продолжить. Когда это случится, уведомленный снова вызовет функцию опроса, и вам нужно будет определить, где вы с ним остановились. Вы отвечаете за отслеживание его продвижения. Шаблон конечного автомата — элегантный способ смоделировать это.
Чтобы обрабатывать создание tar-архива, в определенном конечном автомате содержатся состояния, смоделированные как варианты перечисления:
enum TarState {
Init(TarStateInit),
Open(TarStateOpen),
Header(TarStateHeader),
Read(TarStateRead),
Padding(TarStatePadding),
Completed(TarStateCompleted),
}
У каждого состояния имеется особое значение:
- Init — начало обработки единого файла;
- в Open хранится информация о начатом процессе открытия файла;
- в Header содержится информация о начатом процессе считывания метаданных, например длина и разрешения;
- в Read для каждого фрагмента отслеживается ход считывания из файла;
- в Padding указывается, какая информация о дополнении уже выведена;
- Completed — заключительный этап генерирования потока.
Принципиальный поток конечного автомата представлен на схеме, в случае какой-либо ошибки сразу переходим в состояние completed:
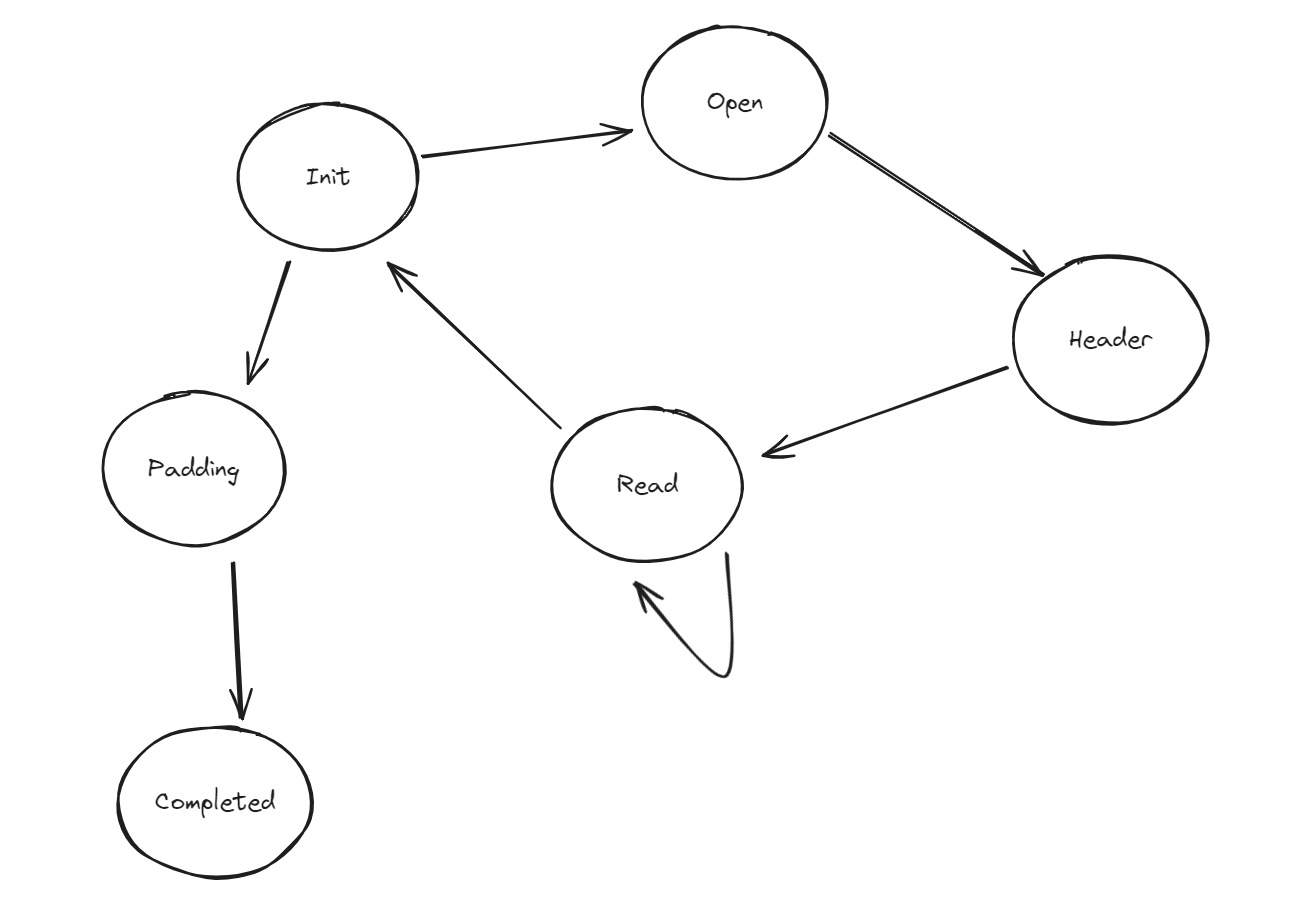
Разберемся сначала с исходным состоянием:
impl TarStateHandler for TarStateInit {
fn poll(self, _cx: &mut Context<'_>) -> TarPollResult {
TarPollResult::NextEntry()
}
}
Исходным состоянием почти ничего не делается, основное его назначение — указать потоку на переход к следующей записи. Процесс интерпретации результата, возвращаемого из любого состояния, обрабатывается самим потоком:
let (state, poll) = match result {
TarPollResult::ContinueLooping(state) => (state, None),
TarPollResult::ReturnPolling(state, poll) => (state, Some(poll)),
TarPollResult::NextEntry() => match self_mut.entries.pop_front() {
None => (TarState::padding(), None),
Some(entry) => (TarState::open(self_mut.buffer_size, entry), None),
},
};
В данном случае в результате выполнения NextEntry выбор следующей записи осуществляется из вектора. Если ничего не найдено, начинаем дополнение padding. В противном случае переходим в состояние open с вновь выбранной записью.
Состояние open чуть сложнее. Открытие файла — это операция, чреватая блокированием. Однако частью операционных систем она, похоже, поддерживается не в полной мере, и в Tokio стандартный вызов каким-то образом искусственно делается асинхронным:
pub async fn open(path: impl AsRef<Path>) -> io::Result<File> {
let path = path.as_ref().to_owned();
let std = asyncify(|| StdFile::open(path)).await?;
Ok(File::from_std(std))
}
Что это значит для нас? Трудности при опрашивании футуры, ведь для этого ее нужно сохранить как фиксированный и упакованный динамический объект:
struct TarStateOpen {
buffer_size: usize,
task: Pin<Box<dyn Future<Output = Result<(String, File), std::io::Error>> + Send>>,
}
impl TarStateOpen {
fn new(buffer_size: usize, entry: TarEntry) -> Self {
let task = async move {
match entry {
TarEntry::File(path) => match File::open(&path).await {
Ok(file) => Ok((path, file)),
Err(error) => Err(error),
},
}
};
Self {
buffer_size: buffer_size,
task: Box::pin(task),
}
}
}
impl TarStateHandler for TarStateOpen {
fn poll(mut self, cx: &mut Context<'_>) -> TarPollResult {
let (path, file) = match self.task.as_mut().poll(cx) {
Poll::Pending => return TarState::Open(self).pending(),
Poll::Ready(Err(error)) => return TarState::failed(TarError::IOFailed(error)),
Poll::Ready(Ok((path, file))) => (path, file),
};
TarStateHeader::new(self.buffer_size, path, file).poll(cx)
}
}
В конструкторе сохраняется фиксированная ссылка на футуру, возвращаемую из асинхронного блока. Футура не применяется с await, опросим ее позже в функции опроса.
Если мы получаем отложенный Pending, просто возвращаем то же состояние вместе с отложенным Pending результатом потока. Если получаем кортеж, передаем его в следующее состояние. Легко и просто.
По той же причине опросим футуру и в состоянии header. Метаданные извлекаются только блокирующим вызовом, а искусственная async-ификация появилась в Tokio:
pub async fn metadata(&self) -> io::Result<Metadata> {
let std = self.std.clone();
asyncify(move || std.metadata()).await
}
То есть нужно сохранить эту футуру вместе с файлом, полученном в предыдущем состоянии:
struct TarStateHeader {
buffer_size: usize,
path: String,
task: Pin<Box<dyn Future<Output = Result<(File, Metadata), std::io::Error>> + Send>>,
}
impl TarStateHeader {
fn new<'a>(buffer_size: usize, path: String, file: File) -> TarStateHeader {
let task = async move {
match file.metadata().await {
Ok(metadata) => Ok((file, metadata)),
Err(error) => Err(error),
}
};
Self {
path: path,
task: Box::pin(task),
buffer_size: buffer_size,
}
}
}
impl TarStateHandler for TarStateHeader {
fn poll(mut self, cx: &mut Context<'_>) -> TarPollResult {
let (file, metadata) = match self.task.as_mut().poll(cx) {
Poll::Pending => return TarState::Header(self).pending(),
Poll::Ready(Err(error)) => return TarState::failed(TarError::IOFailed(error)),
Poll::Ready(Ok(metadata)) => metadata,
};
let length: u64 = metadata.len();
let header: TarHeader = TarHeader::empty(self.path);
match header.write(&metadata) {
Ok(chunk) => TarState::read(self.buffer_size, file, length).ready(chunk),
Err(error) => TarState::failed(error),
}
}
}
Метаданными заполняется структура tar-заголовка, а файл передается на следующий этап. Как и в предыдущем состоянии, отложенный Pending результат мы возвращаем вместе с самим состоянием и идем дальше.
Как же tar-заголовок создается и преобразуется в фрагмент? Чтобы акцентировать внимание на основных этапах создания заголовка, часть кода я опустил:
struct TarHeader {
path: String,
data: Box<[u8; 512]>,
}
impl TarHeader {
...
fn write(mut self, metadata: &Metadata) -> TarResult<TarChunk> {
let data = &mut self.data;
Self::write_name(data, &self.path)?;
Self::write_mode(data, metadata)?;
Self::write_uid(data, 0)?;
Self::write_gid(data, 0)?;
Self::write_size(data, metadata)?;
Self::write_mtime(data, metadata)?;
Self::write_magic(data)?;
Self::write_type_flag(data)?;
Self::write_chksum(data)?;
Ok(self.into())
}
}
impl Into<TarChunk> for TarHeader {
fn into(self) -> TarChunk {
TarChunk::header(self.path, self.data)
}
}
Наконец, состояние чтения. Пожалуй, самое важное — ему уделяется большая часть процессорного времени — и самое опрашиваемое:
struct TarStateRead {
buffer_size: usize,
file: File,
left: usize,
completed: usize,
chunk: TarChunk,
offset: usize,
}
impl TarStateRead {
fn new(buffer_size: usize, file: File, length: u64) -> Self {
let left = length as usize / 512;
let available = buffer_size / 512;
let pages = std::cmp::min(available, left);
let pages = pages + if length as usize > 0 { 1 } else { 0 };
Self {
buffer_size: buffer_size,
file: file,
left: length as usize,
completed: 0,
chunk: TarChunk::data(pages),
offset: 0,
}
}
fn advance(self, bytes: usize) -> Self {
Self {
buffer_size: self.buffer_size,
file: self.file,
left: self.left - bytes,
completed: self.completed + bytes,
chunk: self.chunk,
offset: self.offset + bytes,
}
}
fn next(self) -> (TarChunk, Self) {
let left = self.left / 512;
let available = self.buffer_size / 512;
let pages = std::cmp::min(available, left);
let pages = pages + if self.left % 512 > 0 { 1 } else { 0 };
(
self.chunk,
Self {
buffer_size: self.buffer_size,
file: self.file,
left: self.left,
completed: self.completed,
chunk: TarChunk::data(pages),
offset: 0,
},
)
}
}
Здесь еще много полей, которые нужно проконтролировать. В состоянии содержатся считываемый файл, его длина, а также числа, которыми обозначаются текущая позиция, оставшиеся байты или смещения в пределах текущего фрагмента.
Примечателен и текущий фрагмент, еще не полностью заполненный или даже пустой. Определили для него две функции: advance и next. Первой увеличивается смещение в текущем фрагменте, второй создается новое состояние с возвращением предыдущего заполненного фрагмента.
Поскольку считывание — важнейшая часть потока, немного кода обработчику состояния тоже потребуется:
impl TarStateHandler for TarStateRead {
fn poll(mut self, cx: &mut Context<'_>) -> TarPollResult {
let pinned: Pin<&mut File> = Pin::new(&mut self.file);
let data = match self.chunk.offset(self.offset) {
Err(error) => return TarState::failed(error),
Ok(data) => data,
};
let mut buffer: ReadBuf<'_> = ReadBuf::new(data);
match pinned.poll_read(cx, &mut buffer) {
Poll::Pending => return TarState::Read(self).pending(),
Poll::Ready(Err(error)) => return TarState::failed(TarError::IOFailed(error)),
_ => (),
}
let read: usize = buffer.filled().len();
let advanced: TarStateRead = self.advance(read);
if advanced.left == 0 {
return TarState::init().ready(advanced.chunk);
}
if advanced.offset == advanced.chunk.len() {
let (chunk, state) = advanced.next();
return TarState::from(TarState::Read(state)).ready(chunk);
}
TarState::from(TarState::Read(advanced)).looping()
}
}
Основной поток аналогичен: когда данные не готовы, возвращаем отложенное Pending состояние, когда данные получаются — принимаем решения. Текущий фрагмент заполнен полностью? Считывание файла завершено? Ответы на эти вопросы сказываются на возвращаемом состоянии или потоке, в котором выдается фрагмент.
Что дальше? Padding, одно из простейших состояний с полем для индекса:
struct TarStatePadding {
index: usize,
}
impl TarStatePadding {
fn new() -> Self {
Self { index: 0 }
}
fn next(self) -> Self {
Self { index: self.index + 1 }
}
}
Два таких же отправляются в конце, поэтому обработчик состояний так прост:
impl TarStateHandler for TarStatePadding {
fn poll(self, _cx: &mut Context<'_>) -> TarPollResult {
match self.index {
0 => TarState::Padding(self.next()).ready(TarChunk::padding(0)),
index => TarState::completed().ready(TarChunk::padding(index)),
}
}
}
Отправив два дополнения padding, перемещаемся в состояние completed. Просто возвращаем None, указывая конец потока:
impl TarStateHandler for TarStateCompleted {
fn poll(self, _cx: &mut Context<'_>) -> TarPollResult {
TarPollResult::ReturnPolling(TarState::completed(), Poll::Ready(None))
}
}
Когда применяется async/await, весь этот код — только чуть лаконичнее — генерируется компилятором: сопровождаемость кода у него не в приоритете.
Попробуем этим асинхронным потоком загружать в контейнер Docker файлы. Воспользуемся легковесным HTTP-клиентом с сокетами Unix для взаимодействия с API среды выполнения Docker и расширим его возможности.
Сначала интегрируем поток tar-архива с таким же подлежащим реализации асинхронным потоком body из hyper. Вместо того чтобы передавать в hyper 8 Гб данных для запроса PUT, напишем поток фрагментов body:
pub struct TarBody {
inner: TarStream,
}
impl TarBody {
pub fn from(stream: TarStream) -> Self {
Self { inner: stream }
}
}
impl Body for TarBody {
type Data = Bytes;
type Error = DockerError;
fn poll_frame(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Result<Frame<Self::Data>, Self::Error>>> {
let self_mut: &mut TarBody = self.get_mut();
let pointer: &mut TarStream = &mut self_mut.inner;
let inner: Pin<&mut TarStream> = Pin::new(pointer);
match inner.poll_next(cx) {
Poll::Pending => Poll::Pending,
Poll::Ready(chunk) => match chunk {
None => Poll::Ready(None),
Some(Err(error)) => Poll::Ready(Some(DockerError::raise_outgoing_archive_failed(error))),
Some(Ok(chunk)) => {
let data: Vec<u8> = chunk.into();
let frame: Frame<Bytes> = Frame::data(Bytes::from(data));
Poll::Ready(Some(Ok(frame)))
}
},
}
}
}
В 33 строках кода мы волшебным образом превратили tar-фрагмент в приемлемый для hyper байтовый фрейм, заодно обработав все ошибки. Интегрируем это в HTTP-клиент:
async fn container_upload(&self, id: &str, path: &str, archive: TarArchive) -> DockerResult<ContainerUpload> {
let url: String = format!("/v1.42/containers/{id}/archive?path={path}");
let connection: DockerConnection<TarBody> = DockerConnection::open(&self.socket).await?;
let stream: TarStream = archive.into_stream(256 * 1024);
let data: TarBody = TarBody::from(stream);
match connection.put(&url, data).await {
Ok(response) => match response.into_bytes().await {
Ok(_) => Ok(ContainerUpload::Succeeded),
Err(error) => Err(error),
},
Err(error) => match error {
DockerError::StatusFailed(url, status, response) => match status.as_u16() {
400 => Ok(ContainerUpload::BadParameter(response.into_error().await?)),
403 => Ok(ContainerUpload::PermissionDenied(response.into_error().await?)),
404 => Ok(ContainerUpload::NoSuchContainer(response.into_error().await?)),
500 => Ok(ContainerUpload::ServerError(response.into_error().await?)),
_ => Err(DockerError::StatusFailed(url, status, response)),
},
error => Err(error),
},
}
}
Принимаемый функцией upload поток tar-архива преобразуется в tar-поток body и передается в функцию put. Идеальная интеграция.
Как узнать, что обошлось без неожиданностей? Создадим контейнер, загрузим файлы, вычислим их хеши, а затем сравним с локальными файлами.
Мы описали очень подробную реализацию асинхронного потока, сделали нетривиальный конечный автомат, проверили в консоли создание tar-архива, а также доказали, что созданный tar полностью распознается в API среды выполнения Docker.
Код — здесь.
Читайте также:
- Борьба с веб-скрейперами с помощью Rust
- Rust: рефакторинг для новичков
- Как я создавал систему для алгоритмического трейдинга на Rust и о чем сожалею
Читайте нас в Telegram, VK и Дзен
Перевод статьи Adrian Macal: Learning Rust: Streaming Tarball


")


