
Большие языковые модели (LLM) быстро стали краеугольным камнем современного ИИ. Однако до сих пор нет общепринятых эффективных практик по разработке LLM-приложений. Поэтому первопроходцы, лишенные четкой дорожной карты, зачастую вынуждены изобретать колесо или застревать на полпути.
В течение последних двух лет я помогал организациям использовать LLM для создания инновационных приложений. Благодаря этому опыту я разработал апробированный метод создания инновационных решений (сформированный с учетом мнения сообщества LLM.org.il), которым поделюсь в этой статье.
Это руководство содержит четкую дорожную карту для навигации по сложному ландшафту LLM-разработок. Вы узнаете, как перейти от идеи к эксперименту, оценке и созданию продукта, используя весь потенциал в области создания революционных приложений.
Почему необходим стандартизированный процесс разработки?
Пространство LLM настолько динамично, что сообщения о революционных инновациях появляются изо дня в день. Этот процесс очень увлекателен, но в то же время чрезвычайно хаотичен — можно потерять ориентацию, задаваясь вопросом, что делать или как реализовать новую идею.
Словом, если вы — новатор в области ИИ (менеджер или практик), который хочет эффективно создавать приложения, совместимые с LLM, эта статья для вас.
Внедрение стандартизированного процесса помогает запускать новые проекты и дает несколько ключевых преимуществ.
- Упорядоченность работы. Деятельность по установленным правилам и общепринятым нормам помогает сплотить членов команды и обеспечивает плавный процесс вхождения новых специалистов в команду (особенно в условиях хаоса).
- Определение четких этапов. Это простой, но верный способ отслеживать работу, оценивать ее и убеждаться, что вы на правильном пути.
- Установление точек принятия решений. LLM-нативная разработка полна неожиданностей и «небольших экспериментов» [см. ниже]. Четкие точки принятия решений позволяют легко снизить риски и всегда оставаться эффективными при разработке.
Навыки, необходимые LLM-инженерам
В отличие от традиционных областей исследований и разработки ПО, LLM-нативная разработка требует специалистов абсолютно нового профиля: LLM-инженера или ИИ-инженера.
LLM-инженер — уникальная гибридная специализация, которая включает навыки из разных (традиционных) профессиональных сфер.
- Навыки программной инженерии: как и для большинства инженеров-программистов, преобладающая часть работы LLM-инженера заключается в сборке и соединении конструкционных деталей.
- Исследовательские навыки: правильное понимание экспериментальной природы LLM чрезвычайно важно; хотя создание «крутых демо-приложений» вполне доступно, дистанция между «крутым демо» и практическим решением требует экспериментов и оперативности.
- Глубокое понимание бизнеса/продукта: из-за специфичности моделей важно понимать бизнес-цели и процедуры, а не придерживаться определенной архитектуры; умение моделировать ручной процесс — золотой навык для LLM-инженеров.
На момент написания этой статьи LLM-инженерия была еще совсем новой сферой деятельности, что затрудняло набор подходящих специалистов. Выходом из положения может стать поиск кандидатов с опытом работы в бэкенд-/дата-инженерии или науке о данных.
Инженеры-программисты могут рассчитывать на более плавный переход, поскольку процесс экспериментирования более «инженерный», чем «научный» (по сравнению с традиционной работой в области науки о данных). Тем не менее, по моим наблюдениям, многие дата-сайентисты также совершали этот переход. Если вы готовы освоить новые «мягкие» (гибкие) навыки, вы на правильном пути!
Ключевые элементы LLM-нативной разработки
В отличие от классических подходов к бэкенд-разработке (например, CRUD — Create, Read, Update и Delete — создавай, читай, модифицируй, удаляй), в LLM-разработке нет готовых пошаговых инструкций. Как и все в искусственном интеллекте, LLM-нативные технологии требуют исследовательского и экспериментального мышления.
Чтобы приручить этого «зверя», нужно следовать принципу «разделяй и властвуй», разбивая работу на небольшие эксперименты, оценивая их результаты и выбирая наиболее перспективные.
Не могу не подчеркнуть важность исследовательского мышления. Вы можете потратить время на изучение вектора исследования и обнаружить, что это «невозможно», «недостаточно хорошо» или «не стоит того». Это совершенно нормально — значит, вы на правильном пути.
Экспериментирование — сердце процесса
Иногда первоначальный эксперимент проваливается. Приходится немного изменить направление работы, и следующий эксперимент удается.
Именно поэтому, прежде чем разрабатывать конечное решение, нужно начать с простых шагов и свести риски к минимуму.
- Определение бюджета и временных рамок. Посмотрите, что сможете сделать за X недель, а затем решите, стоит ли продолжать и как именно. Обычно 2-4 недели — достаточный срок для базовой стандартной операционной процедуры (PoC). Если она выглядит многообещающе — продолжайте вкладывать ресурсы в оптимизацию процесса.
- Экспериментирование. Независимо от подхода, выбранного для этапа экспериментирования, — «снизу вверх» или «сверху вниз», — вы должны стараться максимизировать скорость получения результата. К концу первой итерации экспериментов у вас должно быть несколько PoC (для представления заинтересованным сторонам) и достигнуты базовые показатели.
- Ретроспектива. К концу исследовательского этапа можно понять целесообразность, ограничения и стоимость разработки приложения. Это понимание позволяет решить, стоит ли запускать его в производство, как разрабатывать конечный продукт и его UX.
- Продуктизация. Разработка готовой к производству версии проекта и интеграция его с остальными компонентами решения предусматривает следование эффективным стандартным практикам программной инженерии и внедрение механизма обратной связи и сбора данных.
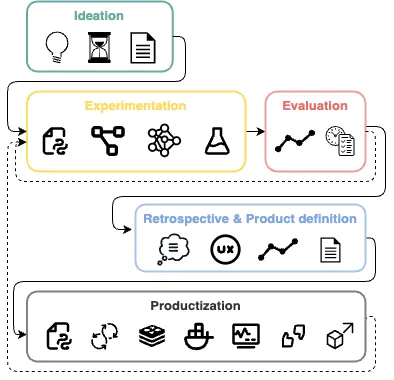
Для надлежащей реализации процесса, ориентированного на эксперименты, необходимо принять взвешенное решение о выборе подхода и способе организации этих экспериментов.
От малого к большому: подход «снизу вверх»
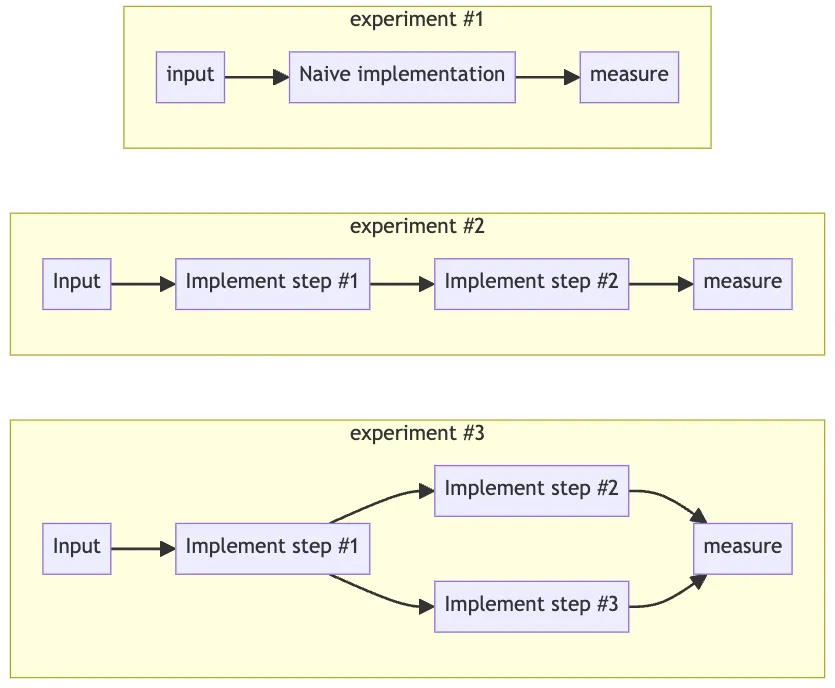
Многие ранние адепты LLM-инженерии стремились как можно быстрее приступить к разработке «ультрасовременных» многоцепочечных агентных систем с использованием полнофункционального фреймворка LangChain или подобного ему. Однако я обнаружил, что подход «снизу вверх» (от простого к сложному) часто дает лучшие результаты.
Начните с малого, совсем малого, придерживаясь философии «один промпт для управления всем«. Эта стратегия может показаться необычной и поначалу, скорее всего, даст плохие результаты. Но она устанавливает базовый уровень создаваемой системы.
В дальнейшем следует постоянно итерировать и совершенствовать промпты, применяя методы промпт-инжиниринга для оптимизации результатов. По мере выявления слабых мест в этом восходящем подходе, разделите процесс, добавив ветви для устранения недочетов.
При проектировании каждого «листа» графа операций LLM, или LLM-нативной архитектуры, я следую Магическому треугольнику, чтобы определить, где и когда нужно обрезать ветви, разделить их или утолстить корни (с помощью методов промпт-инжиниринга). Это позволяет максимально выжать лимон для получения лимонада.
Магический треугольник (The Magic Triangle) — проект развития LLM-нативных технологий, создаваемый автором.
Например, чтобы реализовать «запрос SQL на нативном языке» с помощью подхода «снизу вверх», надо начать с отправки LLM простейших схем, после чего предложить модели сгенерировать запрос.
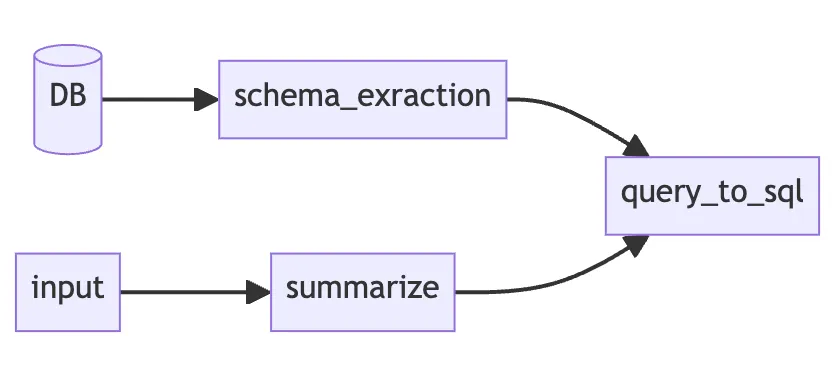
Обычно это решение не противоречит подходу «сверху вниз», а служит предваряющим его шагом. Это позволяет продемонстрировать быстрые победы и привлечь больше инвестиций в проект.
От общей картины к деталям: стратегия «сверху вниз»
«Мы знаем, что рабочий процесс LLM непрост, поэтому для достижения нашей цели мы придем к рабочему процессу или LLM-нативной архитектуре».
Подход «сверху вниз» признает эту стратегию и предполагает с самого начала проектировать LLM-нативную архитектуру и реализовывать ее различные шаги/цепочки.
Таким образом, открывается возможность протестировать архитектуру рабочего процесса в целом и выжать весь лимон сразу, а не по капле, дорабатывая каждый лист по отдельности.
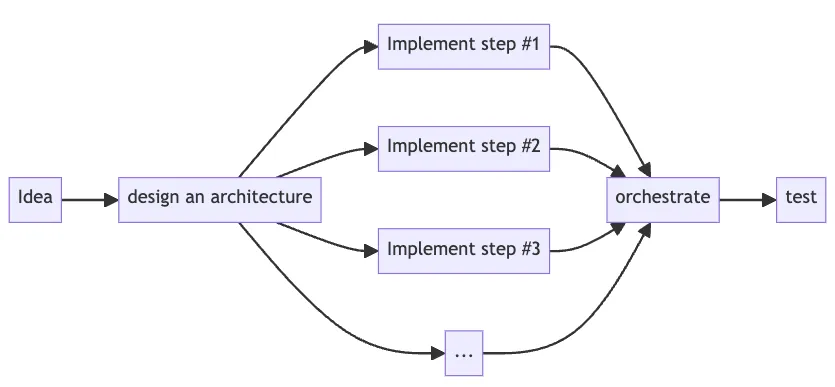
Например, чтобы реализовать «запрос SQL на нативном языке» при подходе «сверху вниз», надо начать проектировать архитектуру еще до начала работы над кодом, а затем переходить к полной реализации:
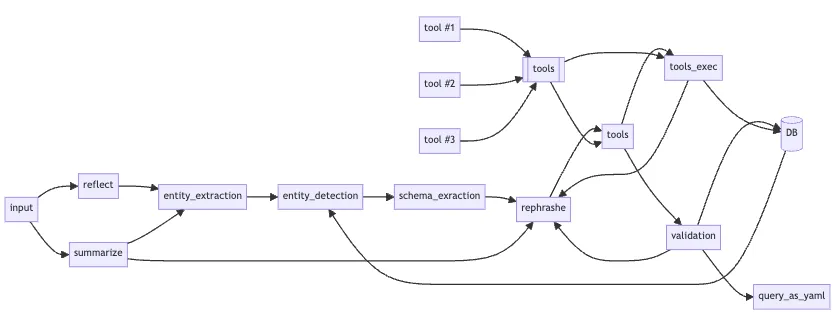
Достижение разумного баланса
Приступая к работе с LLM, вы, скорее всего, впадете в одну из крайностей: соблазнитесь переусложненной стратегией «сверху вниз» или ограничитесь суперпростым обучением на одном примере. И проиграете в любом случае.
Идеальный вариант — определить SoP и смоделировать эксперта, прежде чем писать код и экспериментировать с моделью. В реальности моделировать очень сложно; иногда может не быть доступа к такому эксперту.
По моим наблюдениям, с первого раза не удается найти подходящую архитектуру/SoP, поэтому стоит немного поэкспериментировать, прежде чем переходить к серьезным действиям. Однако это не значит, что все должно быть слишком просто. Если заранее осознаете необходимость что-то разбить на мелкие части — сделайте это.
В любом случае при разработке решения следует использовать парадигму Магического треугольника и корректно смоделировать ручной процесс.
Оптимизация решения: выжимаем лимон
На этапе экспериментирования постоянно выжимаем лимон, добавляя новые «слои сложности».
- Методы промпт-инжиниринга, например few shots (предоставление модели запроса с несколькими примерами), role assignment (присвоение модели определенной роли) или даже dynamic few-shot (динамический выбор наиболее релевантных примеров на основе конкретного контекста).
- Расширение контекстного окна от простых переменных данных до сложных RAG-потоков, что помогает улучшить результаты (RAG — Retrieval-Augmented Generation — генерация ответа, дополненная результатами поиска).
- Экспериментирование с различными моделями, по-разному выполняющих различные задачи. Кроме того, большие LLM часто не очень эффективны с точки зрения затрат, поэтому стоит попробовать более специфичные для конкретной задачи модели.
- Промпт-диета. Как выяснилось, пропускание SOP (в частности, промпта и запрашиваемого вывода) через режим «диета» обычно сокращает задержку. Уменьшая размер промпта и количество шагов, через которые должна пройти модель, можно сократить как входные данные, так и генерируемые моделью выходные данные. Вы будете удивлены, но промпт-диета иногда может даже повысить качество ответа! Имейте в виду, что диета подчас приводит к ухудшению качества, поэтому перед ее применением необходимо провести тест работоспособности.
- Разделение процесса на этапы может быть очень полезным, чтобы сделать оптимизацию подпроцесса SOP более простой и выполнимой. Однако оно может привести и к усложнению решения или снижению производительности (например, при увеличении количества обрабатываемых токенов). Чтобы смягчить побочные эффекты, стремитесь к лаконичным промптам и небольшим моделям. Как правило, разделение процесса целесообразно, когда резкое изменение системного промпта дает лучшие результаты для определенной части потока SOP.
Анатомия эксперимента с LLM
Рекомендую начинать с простого ноутбука Jupyter, используя Python, Pydantic и Jinja2.
- Используйте Pydantic, чтобы определить схему выводов модели.
- Напишите шаблоны промптов с помощью Jinja2.
- Определите структурированный формат вывода (YAML). Это позволит модели следовать «шагам рассуждения» и руководствоваться SOP.
- Обеспечьте вывод с помощью валидаций Pydantic; при необходимости повторите попытку.
- Стабилизируйте работу: структурируйте код на функциональные единицы с помощью файлов и пакетов Python.
К этому набору можно добавить openai-streaming, чтобы упростить использование стриминга (и его инструментов), LiteLLM, чтобы иметь стандартизированный SDK для различных провайдеров LLM, и vLLM для обслуживания LLM с открытым исходным кодом.
Обеспечение качества с помощью тестов работоспособности и оценок
Тесты работоспособности позволяют оценить качество проекта и установить базовый уровень успешности.
Относитесь к своему решению/программе, как к короткому одеялу: если слишком растянуть его, оно может перестать покрывать некоторые случаи использования, которые покрывало раньше.
Чтобы избежать подобных инцидентов, определите набор случаев, которые вы уже успешно покрыли, и убедитесь, что сохраняете его прежним (или, по крайней мере, что оно того стоит). Этот процесс похож на управляемое таблицей тестирование.
Оценить успешность «генеративного» решения (например, написания текста) гораздо сложнее, чем использовать LLM для других задач (таких как категоризация, извлечение сущностей и т. д.). Для такого рода задач может потребоваться привлечь более интеллектуальную модель (например, GPT4, Claude Opus или LLAMA3-70B), которая будет выступать в роли «судьи».
Стоит также попытаться включить в выходные данные «детерминированные части» перед «генеративным» выводом, поскольку такие выходные данные легче тестировать:
cities:
- New York
- Tel Aviv
vibes:
- vibrant
- energetic
- youthful
target_audience:
age_min: 18
age_max: 30
gender: both
attributes:
- adventurous
- outgoing
- culturally curious
# Игнорируем вышеуказанное, показываем пользователю только атрибут `text`.
text: Both New York and Tel Aviv buzz with energy, offering endless activities, nightlife, and cultural experiences perfect for young, adventurous tourists.
На DeepChecks, Ragas и ArizeAI представлено несколько передовых, перспективных решений, которые стоит изучить. Я нашел их особенно актуальными при оценке решений на основе RAG.
Принятие обоснованных решений: важность ретроспектив
После каждого крупного/ограниченного по времени эксперимента (контрольной точки) необходимо остановиться и принять взвешенное решение о том, стоит ли продолжать использовать этот подход и как именно.
К этому моменту у вашего эксперимента будет четкий базовый показатель успешности, а у вас — представление о том, что нужно улучшить.
Это также подходящий момент, чтобы приступить к обсуждению последствий принятого решения для продуктизации и начать «работу над продуктом».
- Как это будет выглядеть в рамках продукта?
- Каковы ограничения/проблемы? Как их можно устранить?
- Какова текущая задержка? Не слишком ли она велика?
- Каким должен быть UX? Какие UI-хаки можно использовать? Может ли помочь стриминг?
- Каковы предполагаемые расходы на токены? Можно ли использовать меньшие модели, чтобы сократить расходы?
- Каковы приоритеты? Является ли какая-либо из этих задач преградой для их достижения?
Предположим, что достигнутый базовый уровень «достаточно хорош», и вы считаете, что сможете решить выявленные проблемы. В таком случае продолжайте инвестировать в проект и улучшать его, не позволяя ему деградировать и используя тесты работоспособности.
От эксперимента к продукту: воплощение решения в жизнь
И последнее, но не менее важное: вы должны продуктивизировать свою работу. Как и при любом другом решении производственного уровня, необходимо реализовать такие концепции продакт-инжиниринга, как протоколирование, мониторинг, управление зависимостями, контейнеризация, кэширование и т. д.
Это огромная сфера разработки цифровых продуктов, но, к счастью, мы можем позаимствовать многие механизмы из классического продакт-инжиниринга и даже перенять многие из существующих инструментов.
Тем не менее важно внимательно относиться к нюансам, связанным с LLM-нативными приложениями.
- Петля обратной связи. Как мы будем измерять успех? Будет ли это просто механизм «большой палец вверх/вниз» или что-то более сложное, учитывающее принятие нашего решения? Важно собирать эти данные, чтобы в дальнейшем определить «базовый уровень» работоспособности, откорректировать результаты с помощью метода промптинга dynamic few-shots или доработать модель.
- Кэширование. В отличие от традиционной программной инженерии, кэширование при использовании генеративного ИИ может быть очень сложным. Чтобы решить проблему, рассмотрите возможность кэширования похожих результатов (например, с помощью RAG) и/или сократите генеративный вывод (с помощью строгой схемы вывода).
- Отслеживание затрат. Многим компаниям кажется очень заманчивым начать с «сильной модели» (например, GPT-4 или Opus), однако в процессе производства затраты могут быстро вырасти. Чтобы финальный счет не стал неприятным сюрпризом, обязательно измеряйте входные/выходные токены и отслеживайте их влияние на рабочий процесс (без этих практик — удачи в профилировании в дальнейшем).
- Отладка и трассировка. Убедитесь, что вы настроили инструменты, необходимые для отслеживания ввода, содержащего ошибку, на протяжении всего процесса. Обычно это включает сохранение пользовательского ввода для последующего изучения и настройку системы трассировки. Помните: «В отличие от промежуточного программного обеспечения, ИИ отказывает беззвучно!»
Заключение: ваша роль в развитии LLM-нативных технологий
Здесь может быть конец статьи, но точно не конец нашей работы. Разработка LLM-нативных приложений — итеративный процесс, который охватывает все больше случаев использования, проблем и возможностей, и постоянно улучшает LLM-нативный продукт.
Продолжая заниматься разработкой приложений на основе ИИ, оставайтесь гибким, бесстрашно экспериментируйте и не забывайте о конечном пользователе. Делитесь опытом и идеями с сообществом — вместе мы сможем расширить границы возможного LLM-нативных технологий. Исследуйте, учитесь, создавайте — возможности безграничны.
Читайте также:
- Путешествие c LLM: от PoC к производству
- Слияние больших языковых моделей с помощью mergekit
- Повышение эффективности промпт-инжиниринга путем поиска по программам в символьной записи
Читайте нас в Telegram, VK и Дзен
Перевод статьи Almog Baku: Building LLM Apps: A Clear Step-By-Step Guide





