
Представьте: у вас есть отличная идея проекта, которую вы можете реализовать с помощью LLM (большой языковой модели) и быстро довести ее до рабочего состояния PoC (Proof-of-Concept — доказательство концепции). Вы гордитесь собой и удивляетесь тому, как мало работы потребовалось, чтобы идея заработала (а все дело в магии пятистрочного промпта).
Но что дальше? Вы быстро понимаете, что при работе с LLM написание PoC — это просто, а вот создание реального, жизнеспособного продукта — тяжелая работа. Если вы попадали в похожую ситуацию, возможно, вам будет интересна эта статья.
Начало работы с LLM
Лучше всего понять весь рабочий процесс можно на примере одного из наших текущих LLM-проектов. Первую часть этого пути разделим на три этапа.
Поиск мотивации
В мире сложных продуктов и огромных объемов информации клиенты часто приходят в состояние растерянности. Иногда даже выполнение базовых операций в рамках продукта требует прочтения множества страниц документации, изнурительной навигации по страницам пользовательского интерфейса продукта или анализа большого количества информации (журналов, отчетов и других исходных материалов).
Как правило, клиент спрашивает: «Разве нельзя просто сказать своими словами, что мне нужно, и позволить системе сделать это за меня?» Ответ звучит так: «С LLM это возможно!»
Объявление цели
В данном случае целью проекта было выполнение действий над продуктами с помощью естественного языка (NL), предоставляемого клиентом.
Наш проект сначала изучает файлы спецификации API продуктов (файлы, в которых API объявлены в стандартном формате, обычно OpenAPI), а затем использует LLM для преобразования запроса на естественном языке в нужный API.
Достижение рабочего доказательства концепции (POC)
После объявления цели проекта мы переходим к стадии POC. Цель POC — убедиться в том, что идея реализуема.
Нам нужно построить базовую систему, которая получает на вход файлы спецификаций API, а также запрос пользователя на естественном языке, и выполняет запрос пользователя в результате.
Для этого мы выбрали GPT от OpenAI в качестве LLM, а LangChain — в качестве библиотеки, которая оборачивает использование LLM.
Мы написали движок, который получает входные данные, перерабатывает их в логические группы (сервисы) и загружает в библиотеку LangChain вместе с промптом, содержащим запрос пользователя и инструкции по выполнению. Для этого мы использовали цепочки, инструменты и агенты LangChain, а также функцию вызова функций OpenAI.
Следующая диаграмма показывает основных участников POC:
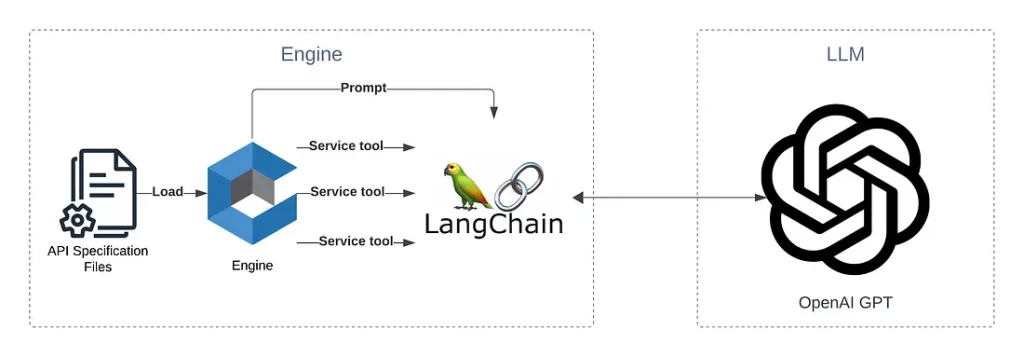
У нас есть работающее POC! А теперь начинается настоящее путешествие…
Точность прежде всего
После того как первоначальное волнение, вызванное работающим доказательством концепции, улеглось, мы стали замечать недостатки в процессе принятия решений и ответах LLM.
В индустрии программного обеспечения мы часто используем детерминированные алгоритмы (т. е. при одинаковых входных данных алгоритм всегда выдает один и тот же результат).
Мой первый совет — откажитесь от привычных детерминистских ожиданий, даже при температуре OpenAI, равной 0.
Цель заключается в том, чтобы научиться ориентироваться в этом новом для нас недетерминированном мире. Другими словами, нужно понять, как можно сделать его более предсказуемым и как справиться с различными реакциями.
Вот несколько советов.
Совет № 1: убедитесь, что используете правильный промпт
Вам нужно будет пошагово объяснить LLM, что нужно сделать. Это включает описание входных данных, их формата и значения, ожидаемого результата, его формата и значения и т. д. Иногда требуется использовать гораздо большее количество строк промпта, чем хотелось бы, или включить в промпт примеры.
В примере из сферы few-shots-обучения, приведенном ниже, вы можете увидеть преимущество добавления примера использования в промпт.
Возьмем следующий запрос: “Получи данные о пользователе «user1» и создай нового пользователя с этими данными”.
Довольно просто и понятно, ведь так? Нет, не так! Вы не поверите, если я вам расскажу, какие странные действия пыталась предпринять LLM, включая введение слова “этими” в данные нового пользователя. Если вместо этого дать LLM следующий пример в промпте, то все заработает как надо.
Запрос: “Получи сведения о сущности «User1» и создай новую сущность с именем «User2» с теми же сведениями”.
Ход мысли модели: Сначала мне нужно получить сведения о сущности «User1» с помощью инструмента “Получить сведения о сущности”. Затем нужно использовать инструмент “Автор сущности” для создания новой сущности с именем «User2» с теми же сведениями.
Совет №2: предоставьте инструментарий для LLM
Иногда LLM не знает, как самостоятельно прийти к правильному действию. В этом случае вы можете снабдить LLM набором инструментов, которые можно использовать тогда, когда LLM не знает, что делать. Этого легко достичь с помощью инструментов LangChain или вызова функций OpenAI.
Вот примеры различных инструментов, которые вы можете использовать.
- Инструмент, помогающий вычислять даты. Вы можете сделать такой запрос: “Дай мне все логи за вчерашний день”. Поскольку у LLM могут возникнуть проблемы с пониманием того, что такое “вчерашний день”, инструмент для вычисления дат поможет ей перевести понятие “вчерашний день” во временную метку, которую можно использовать.
- Пользовательский инструмент/инструмент под управлением человека для получения разъяснений от пользователя. Вы можете сделать такой запрос: “Создай нового пользователя”. Поскольку LLM может понадобиться дополнительная информация, например имя пользователя, она может использовать инструмент пользователя, чтобы спросить пользователя, какое имя ему нужно.
Совет № 3: ограничьте творческий потенциал LLM
Еще один совет — ограничивайте творческий потенциал LLM. Пусть она просит разъяснений, а не угадывает то, что ей неизвестно.
Например, в случае запроса “Создай нового пользователя с именем „user1” одним из параметров API является пароль».
LLM попытается создать пользователя со сгенерированным паролем Password123. Вероятно, это не то, что вам нужно. Вы можете проинструктировать LLM, чтобы в таких случаях она запрашивала уточнения, а не действовала наугад.
Всегда ожидайте неожиданного
Итак, мы создали движок, который поддерживает все сценарии использования и отлично работает в благоприятных условиях. Но как быть с потоками ошибок? Как насчет пограничных случаев?
Вот несколько идей, как справиться с такими ситуациями.
- Проинструктируйте LLM о том, как обработать неожиданный ответ. Сообщите LLM, что могут случаться ошибки, опишите, как их определить и что делать в случае их возникновения.
- Представьте пользователю четкое сообщение о возникновении ошибки, чтобы он мог понять, что произошло и как это исправить.
- Определите поведение автоматического восстановления. В некоторых случаях LLM способна автоматически восстанавливаться после сбоев.
Пример №1: автоисправление ошибок
“Создай пользователя с именем „user1“
LLM может запросить создание этого пользователя с автогенерируемым описанием для него, например “Это пользователь-админ!”. В этом случае возможно, что продукт вернет ошибку “Использование „!“ является недопустимым. Допускаются только буквенно-цифровые значения”. Тогда мы можем проинструктировать LLM прочитать это сообщение об ошибке и автоматически исправить себя, используя описание, не содержащее недопустимых символов.
Пример № 2: обход проблем аутентификации
“Получи пользователя с именем „user1“
Срок действия токена, который мы используем для аутентификации в системе продукта, может истечь. В этом случае продукт возвращает ошибку “Expired token” (“Истек срок действия токена”).
Мы можем поручить LLM обрабатывать проблемы аутентификации и возвращать специальное сообщение, чтобы получить возможность автоматически обновить токен и повторить запрос.
Развертывание, хостинг и основные решения
После создания движка и тонкой настройки модели нужно будет принять решения относительно развертывания. Необходимо будет взвесить множество “за” и “против” во время поиска ответов на следующие вопросы.
Где разместить движок?
Для нас это было несложно. Поскольку нашим основным поставщиком облачных услуг является AWS, мы выбрали именно этот сервис (наш выбор также объясняется стремлением использовать SaaS).
Где разместить LLM?
Мы использовали модель GPT от OpenAI, которая показала наилучшие результаты (в основном потому, что мы активно используем функцию вызова функций, которая изначально поддерживается в этой модели). После сравнительного анализа мы пришли к выводу, что лучше всего разместить эту модель, используя Azure OpenAI. Таким образом, данный проект построен на двух облачных провайдерах, но это совсем не проблема.
Какую стратегию развертывания выбрать?
Будучи сторонником бессерверных решений и решений без управления состоянием, я предпочитаю двигаться именно в этом направлении.
Это не означает, что движок нельзя размещать на статичной машине с отслеживанием состояния. Но я считаю, что с преимуществами бессерверных решений и вариантов без отслеживания состояния слишком сложно конкурировать в плане гибкости, масштабирования, развертывания и управления.
А это приводит нас к необходимости ответить на следующий вопрос.
Как сделать движок LLM независимым от сервера и состояния?
При написании движка LLM вы, скорее всего, столкнетесь с понятием “сессия” или “разговор”. В этом случае понадобится извлекать состояние этой сессии/разговора во внешнее место, которое можно загрузить при необходимости. Этим внешним местом может быть распределенный кэш или база данных, доступ к которой осуществляется с нескольких воркеров движка.
Вот шаги по извлечению состояния сессии или разговора.
- Извлечение истории сессии/разговора. Чтобы заставить LLM принимать во внимание прошлые сообщения, нужно передать ей историю разговора. История разговора — это состояние, которое нужно хранить в отдельном месте и загружать при необходимости, чтобы включить в промпт.
- Извлечение состояния LangChain. Библиотека LangChain с ее агентами и инструментами является по своему дизайну такой, которая отслеживает состояние. Она хранит в памяти множество данных, которые дают подсказки о том, как продолжить работу, что происходило до сих пор, и многое другое. Один из практических примеров, с которым мы столкнулись, — использование “инструмента для выяснения информации о пользователе”: когда LangChain решала использовать этот инструмент, она начинала выяснять информацию, а затем продолжала работу с того же места и с тем же состоянием.
Чтобы решить эту проблему, нам потребовалось глубоко проанализировать код LangChain и переписать некоторые его части для сериализации и десериализации состояния во внешнее место. Это оказалось не самой простой задачей, но тем не менее все получилось.
- Извлечение состояния проекта/приложения, не связанное с LLM. Если у вас есть состояние, не связанное с LLM, его также нужно извлечь и загрузить, когда это потребуется.
Вот пример рабочего потока движка: Получить запрос от пользователя -> Загрузить состояние из внешнего кэш-ресурса -> Обработать запрос -> LLM -> Сохранить состояние во внешний кэш-ресурс -> Вернуть ответ пользователю.
Вы также можете увидеть этот процесс на схеме ниже:
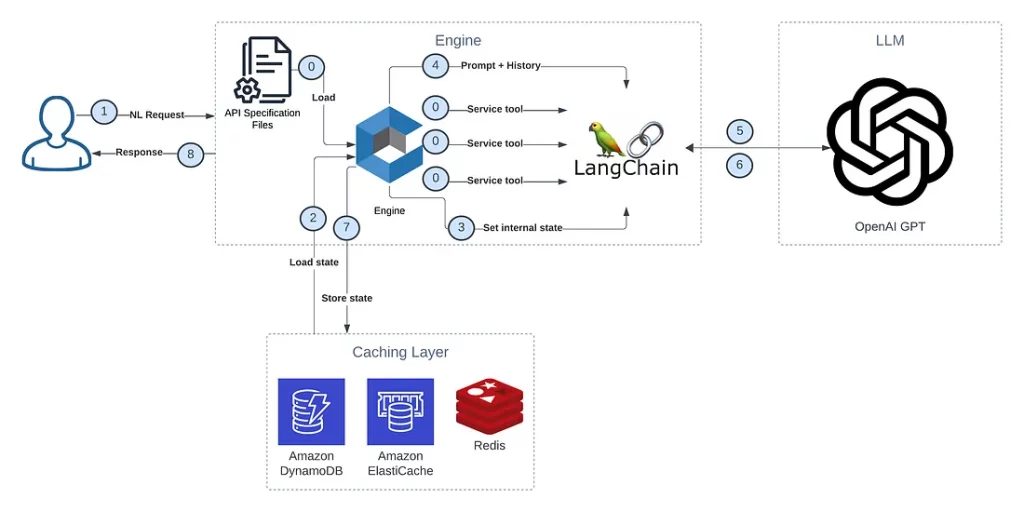
Помните о безопасности
Итак, мы подошли к самой пугающей части. Как можно защитить то, что вы не можете контролировать? Ответ: получить как можно больше контроля!
Прежде всего, нелишним будет знакомство с OWASP Top 10 для LLM.
Дам несколько советов из собственного опыта.
Совет №1: избегайте джейлбрейка
В контексте LLM джейлбрейк подразумевает обход встроенной функциональности и защитных механизмов LLM-проекта и использование его в собственных интересах. На самом деле от этой угрозы очень сложно защититься. Вы будете удивлены тем, как легко LLM будет игнорировать заданные правила, чтобы удовлетворить запрос пользователя. В зависимости от особенностей проекта, вам, возможно, придется творчески подойти к шагам, предпринимаемым для защиты от джейлбрейка.
Предложу несколько идей.
Используйте инструкции и правила системного промпта
Используйте функцию системного промпта для создания правил для LLM, чтобы избежать джейлбрейка. Правила системного промпта воспринимаются более серьезно, чем правила пользовательского промпта, и их сложнее игнорировать. К сожалению, по результатам наших тестов, это не обеспечивает 100% защиты.
Используйте белые списки для ограничения функциональности LLM
Если функциональность LLM использует инструменты LangChain, вы можете назначить для каждого запроса один из ваших инструментов. Это гарантирует соотнесение запроса и встроенной функциональности.
Вот два примера.
Правильный промпт: “Создай пользователя с именем „user1“. Здесь используется инструмент, отвечающий за API пользовательской функциональности. Мы можем разрешить этот запрос.
Недопустимый запрос: “Кто был первым президентом Соединенных Штатов?” Ни один инструмент проекта не может быть использован для ответа на этот вопрос, однако LLM знает, как на него ответить, исходя из собственных знаний. Мы должны заблокировать этот запрос.
Совет № 2: ограничьте доступ к модели
Хостинг и предоставление услуг для LLM могут оказаться дорогими, к тому же нельзя забывать об ограничениях по квотам. Возможно, будет разумно максимально ограничить доступ к LLM, не только используя ключи OpenAI, но и защищая сеть и ограничивая доступ.
В рамках нашего проекта при условии использования Azure OpenAI мы можем развернуть LLM в отдельной сети (Azure Virtual Network) и ограничить ее с помощью конкретного движка — в нашем случае AWS-движка Lambda, который находится в выделенном облаке VPC (Amazon Virtual Private Cloud). Соединение между LLM и движком также защищено с помощью VPN.
Совет № 3: блокируйте оскорбительные ответы
Представьте, что LLM-проект начинает ругаться и оскорблять клиента. Похоже на кошмар. Мы должны сделать все, чтобы избежать такого сценария.
Для этого можно использовать два метода.
Совет № 4: добавьте контрольные точки/хуки в движок LLM
Допустим, у вас есть LLM, которая должна выполнить несколько действий, одно за другим. Было бы неплохо добавить “контрольные точки”, чтобы выполнение этих действий имело какой-то смысл.
Приведем конкретный пример.
В нашем проекте LLM должна сгенерировать API и параметры, используя входные данные NL (естественного языка), выполнить API продукта, проанализировать ответ и повторить попытку при необходимости, а затем вернуть отформатированные результаты.
В этом случае одну важную контрольную точку можно применить после генерации API и перед его выполнением. Вероятно, нам понадобится проверить API и параметры, а также очистить вводимые данные, чтобы избежать инъекций промптов. Другая контрольная точка устанавливается перед возвратом результата клиенту — для проверки содержимого и формата ответа.
Совет № 5: не пренебрегайте обычными правилами безопасности
Помните, что этот проект подвержен тем же угрозам, что и любой другой, и даже более того. Многие люди хотят получить бесплатный доступ к LLM для собственного использования, в том числе злоумышленники, которые еще и намереваются завладеть запрещенными для них активами и т. д.
Обратите внимание на следующие аспекты.
- Аутентификация и авторизация. Проверяйте, имеет ли человек, который получает доступ к продукту, на это право.
- Изоляция тенантов. Сохраняйте ту же защиту в виде изоляции тенантов, что и раньше. Не позволяйте LLM-проекту стать черным ходом для доступа к конфиденциальной информации.
- Файрвол и дросселирование. Контролируйте количество получаемых запросов. Не позволяйте злоупотреблять проектом. Убедитесь, что LLM справляется с нагрузкой.
О чем еще стоит позаботиться?
Мы почти готовы к производству! Вот еще несколько моментов, которые стоит иметь в виду.
Обратная связь
Как узнать, хорошо ли LLM-проект ведет себя в производстве? Как узнать, довольны ли клиенты полученными результатами? Возможно, стоит подумать о механизме обратной связи, чтобы можно было отслеживать результаты и продолжать совершенствовать проект.
Оценка модели
Как узнать, что модель выполняет то, что должна, еще до ее выпуска? Как быть уверенным в изменениях, вносимых в модель? Оценка модели — большая и сложная тема.
Следует сделать следующее.
- Добавить тесты для охвата базовой функциональности LLM-проекта. Тесты могут отличаться от тех, к которым вы привыкли (помните, мы упоминали о навигации в новом недетерминированном мире?). Так, нельзя будет использовать точное соответствие слов. Вместо этого следует протестировать основную функциональность. В рамках нашего проекта мы можем привести пример использования, а затем проверить, был ли выбран правильный API с правильными основными параметрами.
- Использовать LLM для оценки движка LLM. Оценщик LLM может генерировать сценарии использования, давать прогнозы, а затем сравнивать их с фактическими результатами.
Юридический аспект
Начиная новый проект по созданию LLM, вам, возможно, понадобится посоветоваться с юристом, чтобы убедиться в законности своих действий.
Здесь речь может идти о получении согласия от клиентов на использование AI/Gen-AI, недопущение использования данных клиентов для обучения LLM, недопущение хранения информации о разговоре платформой для хостинга LLM, а также обеспечение соответствия требованиям (например, GDPR и т. д.).
Конец путешествия
Это диаграмма, показывающая архитектуру нашего LLM-продукта (она охватывает все, что описано в этой статье):
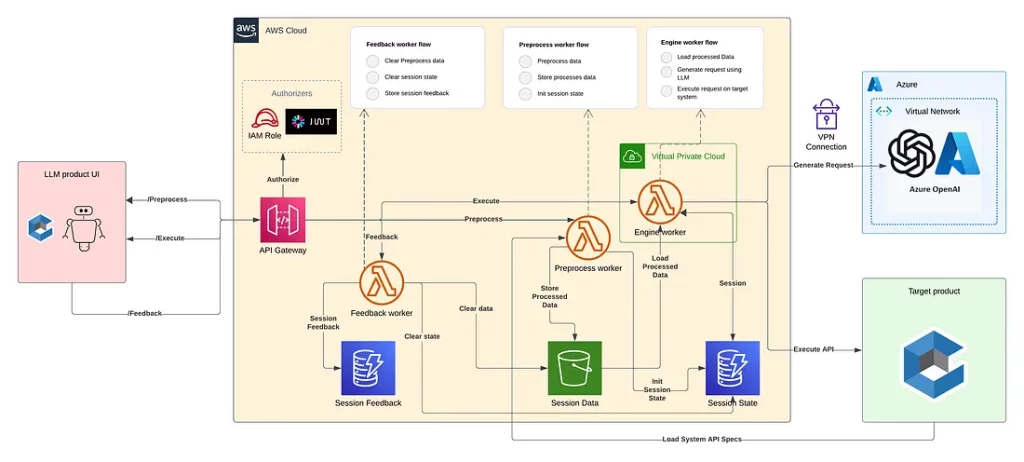
Вот основные игроки нашего процесса.
- Модель GPT. Размещена на Azure OpenAI, защищена и доступна только через AWS VPC.
- Воркер предварительной обработки. Размещается на AWS Lambda. Подготавливает данные (файлы спецификации API) в начале сессии и сохраняет обработанные данные во внешнем хранилище.
- Воркер движка. Размещается на AWS Lambda. Загружает обработанные данные и состояние, генерирует соответствующий API-запрос с помощью LLM и выполняет действие над продуктом.
- Воркер обратной связи. Размещается на AWS Lambda. Собирает и хранит отзывы о сессии и очищает ее состояние.
Читайте также:
- Глубокое погружение в векторные базы данных
- Математика, скрывающаяся за “проклятием размерности”
- Текстовой эмбеддинг: классификация и семантический поиск
Читайте нас в Telegram, VK и Дзен
Перевод статьи Adva Nakash Peleg: An LLM Journey: From POC to Production


")


