
В статье рассмотрим процесс создания простого чат-бота с памятью, способного отвечать на вопросы о ваших собственных данных CSV.
В последнее время я экспериментировал с возможностями больших языковых моделей (LLM), создавая всевозможные продукты. Настало время поделиться результатами работы.
Для предстоящей работы воспользуемся LangChain и Streamlit. LangChain поможет связать gpt-3.5 с данными, а Streamlit займется созданием пользовательского интерфейса для чат-бота.
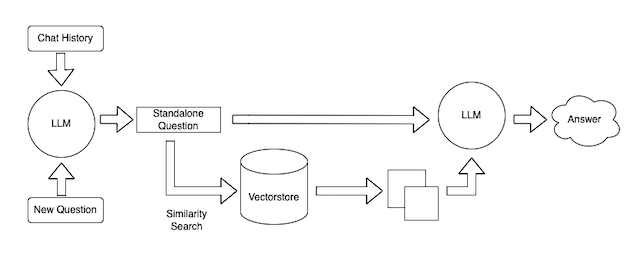
В отличие от ChatGPT с ограниченным контекстом данных, предоставляющего максимум 4096 токенов, этот чат-бот способен обрабатывать данные CSV и управлять большой базой данных благодаря использованию векторных представлений (англ. embeddings) и векторного хранилища.
Код
Приступаем к практике! Разработаем чат-бот на основе данных CSV с минимальным синтаксисом Python.
Примечание. Данный код является упрощенной версией созданного мной чат-бота. Он не оптимизирован для снижения затрат API OpenAI. С более производительной и оптимизированной версией чат-бота можно ознакомиться по ссылке на репозиторий GitHub или просто протестировать приложение chatbot-csv.com.
- Сначала устанавливаем нужные библиотеки:
pip install streamlit streamlit_chat langchain openai faiss-cpu tiktoken
- Импортируем библиотеки, необходимые для чат-бота:
import streamlit as st
from streamlit_chat import message
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import FAISS
import tempfile
- Предлагаем пользователю ввести ключ API OpenAI и скачать файл CSV в качестве основы для создания чат-бота.
- Для тестирования чат-бота с меньшими затратами можно воспользоваться легковесным файлом CSV:
fishfry-locations.csv.
user_api_key = st.sidebar.text_input(
label="#### Ваш ключ OpenAI API 👇",
placeholder="Paste your openAI API key, sk-",
type="password")
uploaded_file = st.sidebar.file_uploader("upload", type="csv")
- Загружаем файл CSV с помощью класса CSVLoader из LangChain:
if uploaded_file :
#Применяется tempfile, поскольку CSVLoader принимает только file_path
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(uploaded_file.getvalue())
tmp_file_path = tmp_file.name
loader = CSVLoader(file_path=tmp_file_path, encoding="utf-8")
data = loader.load()
- Класс
CSVLoaderпозволяет разделить файл CSV на уникальные строки. Проверим это, отобразив содержимое данных:
st.write(data)
0:"Document(page_content='venue_name: McGinnis Sisters\nvenue_type: Market\nvenue_address: 4311 Northern Pike, Monroeville, PA\nwebsite: http://www.mcginnis-sisters.com/\nmenu_url: \nmenu_text: \nphone: 412-858-7000\nemail: \nalcohol: \nlunch: True', metadata={'source': 'C:\\Users\\UTILIS~1\\AppData\\Local\\Temp\\tmp6_24nxby', 'row': 0})"
1:"Document(page_content='venue_name: Holy Cross (Reilly Center)\nvenue_type: Church\nvenue_address: 7100 West Ridge Road, Fairview PA\nwebsite: \nmenu_url: \nmenu_text: Fried pollack, fried shrimp, or combo. Adult $10, Child $5. Includes baked potato, homemade coleslaw, roll, butter, dessert, and beverage. Mac and cheese $5.\nphone: 814-474-2605\nemail: \nalcohol: \nlunch: ', metadata={'source': 'C:\\Users\\UTILIS~1\\AppData\\Local\\Temp\\tmp6_24nxby', 'row': 1})"
- Разделение файла CSV позволяет предоставить его векторному хранилищу
vectorstore(FAISS), используя векторные представления OpenAI. - Векторные представления преобразуют части, разделенные CSVLoader, в векторы. Эти векторы представляют собой индекс на основе содержимого каждой строки файла.
- На практике, когда пользователь делает запрос, в векторном хранилище выполняется поиск, и наиболее подходящие индексы возвращаются в модель LLM. Затем она перефразирует содержимое найденного индекса и предоставляет пользователю отформатированный ответ.
- Для лучшего понимания рекомендуется углубленно изучить концепции векторного хранилища и векторных представлений.
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(data, embeddings)
- Далее добавляем цепочку
ConversationalRetrievalChain. Обеспечиваем ее нужной моделью чатаgpt-3.5-turbo(илиgpt-4) и векторным хранилищем FAISS, которое содержит файл, преобразованный в векторы посредствомOpenAIEmbeddings(). - Это цепочка позволяет получить чат-бот с памятью и одновременно использовать
vectorstoreдля поиска соответствующей информации из документа.
chain = ConversationalRetrievalChain.from_llm(
llm = ChatOpenAI(temperature=0.0,model_name='gpt-3.5-turbo'),
retriever=vectorstore.as_retriever())
- Данная функция передает вопрос пользователя и историю беседы в
ConversationalRetrievalChainдля генерации ответа чат-бота. st.session_state[‘history’]сохраняет историю беседы пользователя, когда он находится на сайте Streamlit.
При желании добавить улучшения в данный чат-бот переходите по ссылке на GitHub.
def conversational_chat(query):
result = chain({"question": query,
"chat_history": st.session_state['history']})
st.session_state['history'].append((query, result["answer"]))
return result["answer"]
- Инициализируем сеанс чат-бота, создавая
st.session_state[‘history’]. Вслед за этим в чате отображается первое сообщение. [‘generated’]соответствует ответам чат-бота.[‘past’]соответствует сообщениям, исходящими от пользователя.- Контейнеры не обязательны, но помогают улучшить UI, размещая область вопроса пользователя под сообщениями чата.
if 'history' not in st.session_state:
st.session_state['history'] = []
if 'generated' not in st.session_state:
st.session_state['generated'] = ["Hello ! Ask me anything about " + uploaded_file.name + " 🤗"]
if 'past' not in st.session_state:
st.session_state['past'] = ["Hey ! 👋"]
#контейнер для истории чата
response_container = st.container()
#контейнер для текстового ввода пользователя
container = st.container()
- После настройки
session.stateи контейнеров переходим к созданию части UI, которая позволяет пользователю вводить и отправлять вопрос в функциюconversational_chatс вопросом пользователя в качестве аргумента.
with container:
with st.form(key='my_form', clear_on_submit=True):
user_input = st.text_input("Query:", placeholder="Talk about your csv data here (:", key='input')
submit_button = st.form_submit_button(label='Send')
if submit_button and user_input:
output = conversational_chat(user_input)
st.session_state['past'].append(user_input)
st.session_state['generated'].append(output)
- Эта часть UI отображает сообщения пользователя и чат-бота на сайте Streamlit с помощью модуля
streamlit_chat.
if st.session_state['generated']:
with response_container:
for i in range(len(st.session_state['generated'])):
message(st.session_state["past"][i], is_user=True, key=str(i) + '_user', avatar_style="big-smile")
message(st.session_state["generated"][i], key=str(i), avatar_style="thumbs")
- Осталось только запустить скрипт:
streamlit run name_of_your_chatbot.py #запуск с именем вашего файла
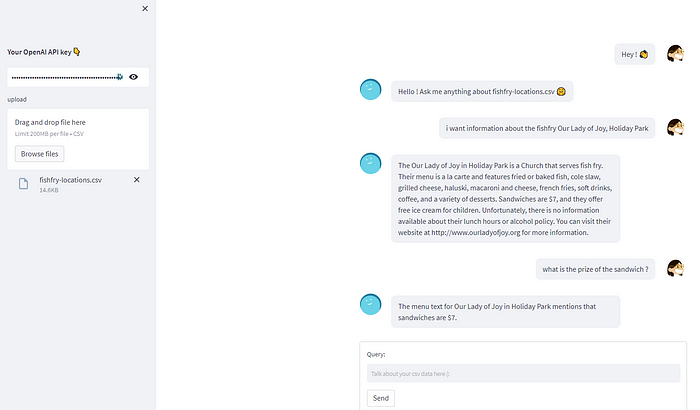
Сработало! Мы создали чат-бот, работающий с LangChain, OpenAI, Streamlit и отвечающий на вопросы на основе файла CSV!
Полный проект представлен по ссылке GitHub.
Читайте также:
- Взгляд в будущее: перспективы развития и влияния ИИ на изобразительное искусство и повседневную жизнь
- Как создать веб-приложение для преобразования речи в текст с Node.js
- FastAPI, Flask или Streamlit: что выбрать для веб-разработки?
Читайте нас в Telegram, VK и Дзен
Перевод статьи Yvann: Build a Chatbot on Your CSV Data With LangChain and OpenAI

")



