
Период проб и ошибок
Трудясь над каждой операцией на протяжении многих лет, я стремился улучшать свои навыки. Я успешно преодолевал текущие проблемы, но на их месте всегда появлялись новые.
Обычно эти проблемы были связаны с состоянием. Как бы тщательно я ни разделял все контроллеры и менеджеры, всегда находился фрагмент кода, которому требовался доступ к состоянию. Эти инциденты приводили к сбою первоначального проекта.
Повторение одного и того же действия в ожидании разных результатов — настоящее безумие. И я, в конце концов, решил положить этому конец и попробовать что-то другое.
В поисках альтернативы
Я изучал все варианты, какие только смог найти. Я разбирал успешные библиотеки в поисках подсказок по оптимизации проигрывателя.
В конце концов, я убедил свою команду приступить к созданию совершенно другой архитектуры для следующей итерации проигрывателя. Это был огромный риск. Мы действовали вслепую, руководствуясь лишь амбициями и упрямством, порожденным отчаянием. Провал был недопустим.
И мы преуспели. Мы справились с задачей в рекордно короткие сроки. Разработанный проигрыватель был надежным: мы годами обходились без наращивания основной функциональности. Он был масштабируемым: мы добавляли функции без установления взаимозависимостей. Он был расширяемым: у других команд из других компаний получалось без проблем его модифицировать. Более того, наша команда из 4–6 инженеров оказалась более продуктивной, чем другие команды из 20 человек.
Однако этот проигрыватель и его инновационный дизайн не выжили в корпоративных условиях. Поэтому хочу поделиться опытом, с трудом приобретенным моей командой.
Принцип № 1. Инкапсулируйте бизнес-логику, а не состояние
Что будет, если централизовать все части устойчивого состояния, просто убрав их из классов?
Нам пришлось задать себе этот вопрос, приступая к разработке проигрывателя. Мы собирались создать некую вариацию Redux, но в больших масштабах. Мы верили, что наличие 1 легкодоступного источника истины решит огромное количество проблем.
С чем мы остались после извлечения состояния? С большим количеством бизнес-логики, которая не имела смысла, потому что была распределена по приложению.
И тут я понял, что все дело в бизнес-логике.
Состояние — это просто временная связь между различными частями бизнес-логики.
Мы все время инкапсулировали не то, что нужно.
Пример
Представьте себе компьютерную программу в виде группы сидящих за рабочими столами гномов.
В одной комнате (назовем ее “Реактивной Комнатой”) вы даете всем гномам 1 набор задач. Каждые несколько минут они получают в свой блок IN (входящих сообщений) лист бумаги, содержащий все данные, необходимые для выполнения этих задач. Они производят вычисления (своей бизнес-логики) и отправляют результаты в блок OUT (исходящих сообщений).
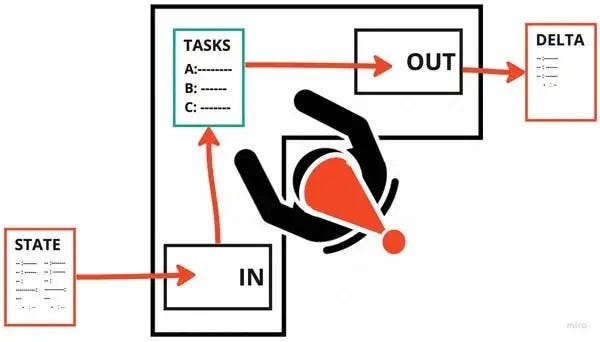
Ни для одного гнома не имеет значения, откуда берутся данные в блоке IN и куда они попадают после отправления в блок OUT. “Реактивному” гному не обязательно находиться в одной комнате с другими гномами: когда их обучают и тестируют, им можно вручать произвольные листы бумаги, чтобы убедиться в том, что они знают свое дело. Медлительных гномов быстро заменяют.
Совсем рядом, в “Комнате ориентированных объектов”, не все так упорядоченно. Здесь у каждого гнома — свой лист бумаги с секретными заметками. Они не хотят делиться этими записями из опасения, что кто-нибудь неожиданно изменит данные, поэтому у них установлен ряд блоков IN. Если кому-то понадобится что-то сделать со своими данными, он должен хорошо попросить об этом коллегу.
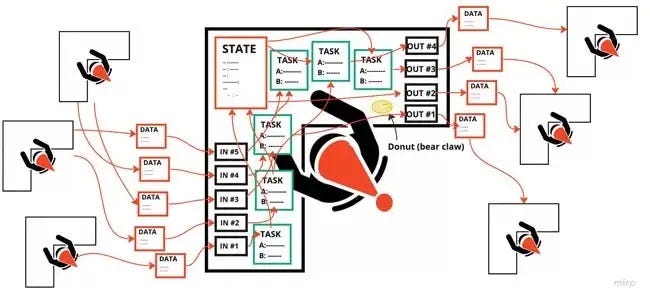
Списки задач этих гномов могут быть разрозненными и загадочными, требующими выяснения того, что делают другие гномы вокруг них. Это часто означает, что они выполняют маленькие части больших задач. Даже если каждый из них справляется со своим заданием, они не знают, как их работа влияет на другого гнома, постоянно рассылающего тревожные сообщения об ошибках, которые никто не понимает.
Итак, какая комната более продуктивна? Думаю, долго выбирать вам не придется.
Принцип №2. Отделяйте передачу сообщений от бизнес-логики
Конечно, в “Реактивной Комнате” намного проще управлять процессом.
Гномам не нужно знать, как данные попадают в их блок IN, и им не нужно беспокоиться о том, что происходит с этими данными после того, как они помещают их в блок OUT.
Но как же определить, куда направляются разные сообщения?
Отойдем от примера с гномами и обсудим реальную несвязанную систему передачи сообщений. Рассмотрим Redux.
В Redux код компонента, который должен запустить определенную бизнес-логику, отправляет действие вместе с соответствующими данными для выполнения этого действия. Это действие направляется определенному редьюсеру, который представляет собой просто функцию, принимающую данные из действия, выполняющую определенную бизнес-логику по отношению к текущему состоянию приложения и возвращающую новое состояние приложения.
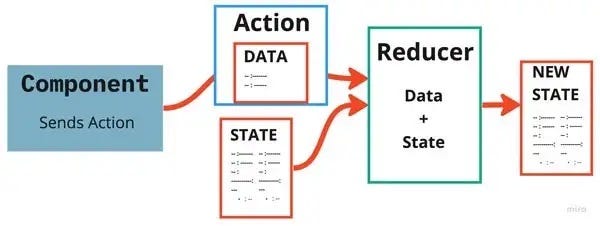
Эта схема хорошо работает с React и даже Angular, но Redux нужно расширять для обработки более сложных сценариев использования. Поэтому такая схема не очень подходит для приложений со сложным состоянием.
Однако концепция действия чрезвычайно интересна.
Действия — это не события, хотя они и похожи чем-то. Событие дает знать: что-то только что произошло (например, видео было поставлено на паузу). Действие дает знать: что-то вот-вот произойдет (например, пора поставить видео на паузу).
Действие можно рассматривать как контракт между кодом, который отправляет действие, и кодом, который его получает. Если данные, необходимые для выполнения работы, настроены правильно, можно приступать.
Мы можем использовать действия как основу для соединения сложной бизнес-логики.

Эта бизнес-логика не находится в редьюсере. Этот код должен потреблять и отправлять действия, чтобы состояние перемещалось по приложению.
Оказывается, для этого типа кода существует стандартное название.
Акторы
Рассмотрим паттерн “Актор” из реактивного программирования.
Постарайтесь представить себе реактивное программирование как программирование потоковое. Работа одного актора перетекает в работу другого, затем еще одного и т. д. Таким образом создается целая стремительная река состояния, протекающая через приложение.
Реактивные потоки обладают огромной гибкостью.
Один актор может условно отправлять различные действия, как показано на диаграмме ниже:
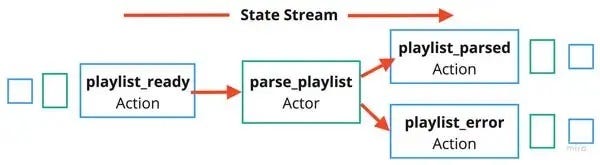
Вы можете реализовать машины состояний и включить таймеры, которые запускают другие акторы.
Кроме того, вы не ограничены одним актором для каждого действия. Их можно объединять вместе:

Существует любое количество вариантов использования, когда несколько акторов взаимодействуют с одними и теми же действиями. Можно устроить гонку, в которой побеждает первый актор, или параллельное выполнение, когда несколько акторов или даже несколько экземпляров одного и того же актора работают вместе, чтобы разделить задачу.
Библиотека Akka для среды выполнения Java предоставляет надежный набор подобных коннекторов. Однако такие библиотеки, как правило, ориентированы на внутренние системы. Я не знаю ничего подобного, что можно было бы использовать в JavaScript (был бы рад ошибаться). Для своего приложения я создал довольно простой предметно-ориентированный язык, который оказался достаточно хорош.
Главный вывод заключается в следующем: поскольку передача сообщений отделена от акторов, если потребности приложения меняются, акторы можно использовать по-разному, не меняя их реализацию.
Такая гибкость в перемещении бизнес-логики является огромным преимуществом реактивного программирования и паттерна “Актор”. Она позволяет приложениям с фиксацией текущего состояния масштабироваться с течением времени.
Принцип №3. Состояние должно быть неизменяемым
Кто знает, какие данные понадобятся актору для работы его бизнес-логики? Одна из суровых реалий разработки сложного приложения заключается в том, что очень трудно предсказать, как и когда будет использоваться состояние.
Поэтому необходимо разрешить акторам доступ ко всему состоянию. Зачем ограничивать себя? Мы работаем на стороне клиента. Передача ссылки на большой объект не так уж затратна.
Но чтобы позволить актору получить доступ ко всему состоянию, нужно установить ограничения. Состояние должно быть неизменяемым. Акторы могут читать любое состояние, но не могут напрямую перезаписывать его. Это было бы непредсказуемо и очень нетипично.
Следует также следить за тем, чтобы актор не брал на себя задачу изменения состояния, чтобы не связывать преобразование состояния с бизнес-логикой. Это может быть полезно, когда речь идет о редьюсере Redux, но в отношении масштабирования возникнут трудности.
Для обработки изменения мы используем объект delta.
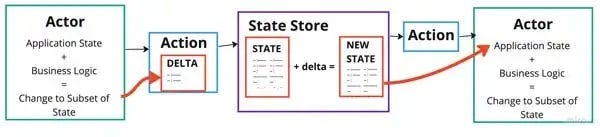
Объект delta может быть типизирован и связан с определенным действием. Это позволяет выполнять валидацию во время компиляции и выполнения.
Центральный State Store позволяет заменить процесс мутации. Вы используете seamless-immutable, но хотите больше скорости? Обновитесь до immutable.js, и никакие другие части приложения не потребуют изменений.
Читайте также:
- Как ускорить full-stack разработку, не создавая API
- Современное приложение выбирает… Redux, Context или Recoil?
- Что такое Редьюсеры: Как использовать их без Redux
Читайте нас в Telegram, VK и Дзен
Перевод статьи Daniel Niland: Three Core Principles of Decoupled Applications





