
Вступление
В сегодняшней IT-индустрии хранение и извлечение данных приложений базируется на объектно-ориентированных языках программирования и реляционных базах данных. Базы данных хранят большой объем информации в одном месте. Наряду с этим, они предоставляют эффективный способ поиска записей, чтобы легко и быстро добраться до нужных данных.
Но при работе с объектами есть одна функция, которую база данных не поддерживает, — это хранение самих объектов, поскольку в ней хранятся только реляционные данные. Данные в виде объектов обеспечивают абстракцию и переносимость.
Существует ли метод, с помощью которого возможно напрямую хранить и извлекать объекты в реляционной базе данных? Ответ — да, такая возможность есть. Название этой техники — ORM.
Объектно-реляционное отображение (Object Relational Mapping, ORM)
ORM устраняет несоответствие между объектной моделью и реляционной базой данных. Само название предполагает отображение объектов в реляционные таблицы. Технология ORM преобразует объекты в реляционные данные и обратно. Возникает вопрос: как это делается?
По сути, имя переменной экземпляра присваивается имени столбца, а его значение формирует строку в реляционной базе данных. Теперь вопрос в том, нужно ли объявлять таблицу в базе данных для хранения объектов. Ответ — нет, ORM сделает это за нас, объявив типы данных для столбцов такими же, как и для переменных экземпляра.
Однако для этого нужно выполнить небольшую настройку и сообщить ORM, как будут отображаться объекты. В Java ORM работает с обычными старыми классами объектов Java (POJO), объекты которых необходимо сопоставить. Эти классы по сути состоят из частных переменных экземпляра, параметризованного конструктора с общедоступными геттерами и сеттерами.
Наряду с параметризованным конструктором класс POJO должен иметь открытый конструктор без аргументов, поскольку он необходим ORM для сериализации. Поскольку параметризованный конструктор присутствует, compile не будет добавлять конструктор аргументов самостоятельно, поэтому придется делать это вручную.
Что такое Hibernate?
Hibernate — это высокопроизводительный инструмент объектно-реляционного сопоставления с открытым исходным кодом для языка программирования Java. Он был выпущен в 2001 году Гэвином Кингом и его коллегами из Cirrus Technologies в качестве альтернативы Entity Beans (объектным бинам) в стиле EJB2.
Этот фреймворк отвечает за решение проблем несоответствия объектно-реляционного импеданса. В Java есть спецификация под названием Java Persistence API (JPA), которая описывает управление объектами в реляционной базе данных. Hibernate — это всего лишь реализация JPA.
Архитектура Hibernate
Обсудим компоненты, из которых состоит Hibernate. Hibernate имеет многоуровневую архитектуру и позволяет работать, даже не зная базовых API, реализующих объектно-реляционное сопоставление. Hibernate находится между Java-приложением и базой данных. Архитектура Hibernate подразделяется на четыре уровня:
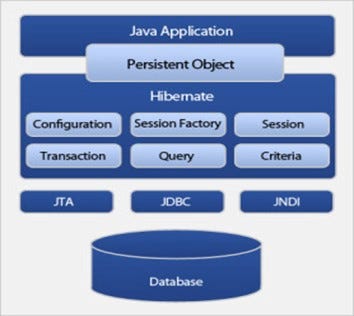
- уровень Java-приложения;
- уровень фреймворка;
- уровень API;
- уровень базы данных.
На приведенной выше диаграмме показаны все четыре слоя. Поток данных между Java-приложением и базой данных выполняется с использованием постоянного объекта, определенного Hibernate. Уровень инфраструктуры Hibernate состоит из различных объектов, таких как конфигурация, фабрика сеансов, сеанс, транзакция, запрос и критерии. Эти объекты создаются вручную, по мере необходимости.
Объект конфигурации. Первый объект Hibernate, который должен присутствовать в любом Hibernate-приложении. Он активирует платформу Hibernate. Объект конфигурации создается только один раз во время инициализации приложения. Это родительский объект — именно из него создаются все остальные. Он проверяет, является ли файл конфигурации синтаксически правильным или нет. Он предоставляет свойства конфигурации и сопоставления, необходимые Hibernate.
Объект фабрики сеансов. Фабрика сеансов — это массивный потокобезопасный объект, используемый несколькими потоками одновременно. Таким образом, в приложении он должен быть создан только один раз и сохранен для последующего использования. Для каждой базы данных необходим отдельный объект фабрики сеансов. Фабрика сеансов отвечает за настройку Hibernate посредством свойств конфигурации, предоставляемых объектом конфигурации.
Объект сеанса. Облегченный объект, который создается каждый раз, когда нужно взаимодействовать с базой данных. Постоянные объекты сохраняются и извлекаются с помощью объекта сеанса. Это не потокобезопасный объект, поэтому его следует уничтожить после завершения взаимодействия.
Объект транзакции. Представляет собой единицу работы с базой данных. Это необязательный объект, но его следует использовать для обеспечения целостности данных и в случае возникновения какой-либо ошибки — выполнять откат.
Объект запроса. Объект запроса нужен для записи запросов и выполнения операций CRUD в базе данных. Можно написать запрос на SQL или воспользоваться языком запросов Hibernate (HQL). В процессе реализации вам станет известно о HQL больше.
Объект критериев. С его помощью выполняются объектно-ориентированные запросы для извлечения объектов из базы данных.
Как настроить Hybernate?
Во-первых, нужно установить Hibernate у себя в проекте. Можно загрузить jar-файл или воспользоваться более удобным способом, например, применить maven. Так и поступим. Загрузим зависимость hibernate, определенную в POM.xml.
Фреймворк Hibernate должен знать, как сопоставлять объекты, учетные данные сервера базы данных, где будут храниться и откуда будут извлекаться объекты, и еще несколько свойств. Вопрос в том, как передать всю эту информацию в Hibernate.
Эта настройка выполняется с помощью двух XML-файлов.
- hibernate.cfg.xml содержит свойства гибернации, такие как диалект, класс драйвера, URL-адрес сервера базы данных, имя пользователя и пароль.
- Файл сопоставления содержит взаимосвязь сопоставления между Java-объектами и таблицами базы данных. Имя файла должно соответствовать шаблону <тип объекта>.hbm.XML. Например, если мы хотим работать с объектом типа “Employee”, имя файла будет Employee.hbm.xml.
XML-файлы необходимо поместить в папку META-INF внутри src/main/resources. Третий компонент, который понадобится в настройке, — это класс POJO, который мы обсуждали ранее.
Рассмотрим пример работы с объектом Flight. В качестве переменных экземпляра он содержит идентификатор (ID), номер рейса, место отправления, место прибытия, дату рейса и тариф. Идентификатор будет первичным ключом таблицы.
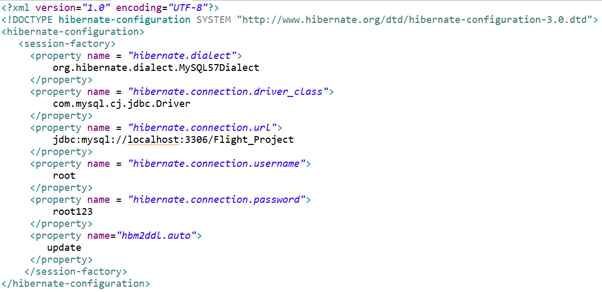
Приведенное выше изображение — это hbm.cfg.xml. Как видите, все свойства определены внутри тега hibernate-configuration. Внутри тега session-factory указываются свойства базы данных, к которой необходимо подключиться.
Свойство hbm2ddl.auto проверяет или экспортирует язык определения данных схемы при создании объекта фабрики сеансов. Здесь мы прописали операцию обновления, которая обновит базу данных, не затрагивая ранее записанные данные. Недостает еще нескольких, таких как проверка, создание и создание-удаление.
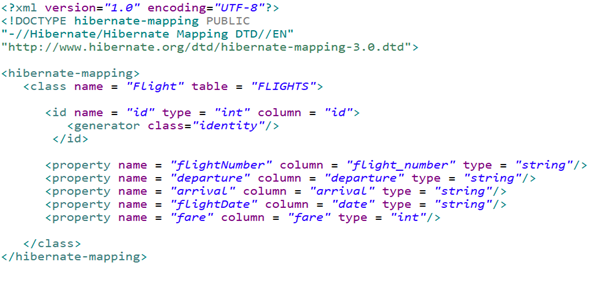
Приведенный выше XML-код относится к файлу сопоставления. Все свойства определены внутри тега hibernate-mapping. Тег class предназначен для определения имени класса POJO и имени таблицы, которые будут созданы внутри базы данных в качестве атрибутов, а отношения сопоставления — в качестве значений.
Первичный ключ определяется внутри тега id. Мы определяем имя переменной экземпляра внутри атрибута name. Имя столбца и тип данных указаны в атрибутах column и type соответственно. Теги generator предоставляют стратегию, с помощью которой необходимо выполнить автоинкремент. Все остальные сопоставления переменных экземпляра предоставляются внутри тегов свойств property.
Настало время, когда нужно создать класс POJO для рейсов (Flights), объекты которого будут сохраняться в таблице FLIGHTS. Здесь есть также пустой конструктор по умолчанию, необходимость которого мы обосновали ранее.

Один вопрос, который наверняка приходит вам в голову: если мы, Java-разработчики, пользуемся инструментарием Java, зачем выполнять настройку с использованием XML? Есть ли какой-нибудь другой способ? Ответ таков: да, но только частично.
От файла сопоставления можно избавиться с помощью аннотаций, но конфигурационный XML-файл все еще необходим. Аннотации — мощный способ определения взаимосвязи между объектом и реляционной моделью. Они начинаются с @.
Нужно просто добавить аннотации внутри класса POJO. Отдельного файла не требуется:
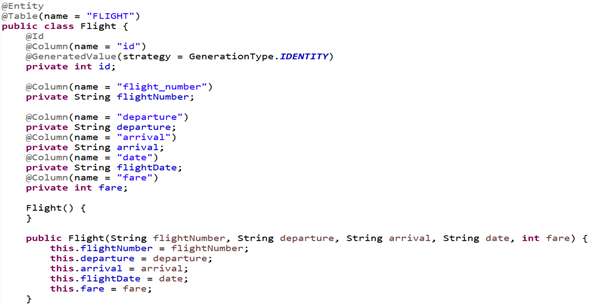
Аннотацию необходимо указывать непосредственно над объявлением поля.
@Entityсообщает Hibernate, что этот класс — компонент сущности, и его объекты должны быть постоянными.@Tableприменяется для указания имени создаваемой таблицы в базе данных.@Idиспользуется для определения первичного ключа. Можно также добавить совместно несколько полей, чтобы создать составной ключ.@GeneratedValueопределяет стратегию инкремента в поле. Это необязательный параметр — если он не определен с помощью@Id, применяется стратегия по умолчанию.@Columnопределяет, как поле сопоставляется со столбцом в таблице. Аннотация принимает такие атрибуты, как имя столбца, определение столбца, возможность принимать null-значение, уникальность и т. д. В отличие от XML-файлов, здесь не нужно указывать тип, поскольку он берется непосредственно из поля.
Реализация Hibernate
Попробуем, наконец, выполнить CRUD-операции с помощью Hibernate. Для этого создадим класс с именем DAO. Но еще до этого нам понадобится объект фабрики сеансов. Есть два способа его создания. Если мы работаем без аннотации, то поступим вот так:

Другой способ будет определен в приведенном ниже примере. Процедура создания всех остальных объектов одинакова для обоих вариантов.
Первый пример — добавление объектов рейса Flight в базу данных. Создаем метод addFlight, который сохраняет объект в базе данных. Далее выполняется транзакция в режиме try-catch, чтобы в случае возникновения какой-либо проблемы удалось выполнить откат, а в противоположном случае — транзакция была зафиксирована в таблице.
Операция сохранения
Метод сохранения в объекте сеанса выполняет задачу вставки объекта.

Операция обновления
Теперь продвинемся вперед и попробуем обновить уже существующие в таблице данные.

Мы создали метод updateFlightNumber, в котором сначала извлекаем объект Flight с заданным идентификатором, а затем обновляем номер рейса методом-сеттером. После этого вызываем update-метод, чтобы обновить существующую сущность.
Примечание: если вам хочется вывести объекты, извлеченные из базы данных, на консоль, добавьте метод toString() в класс POJO, иначе выведется хэш-код.
Операция удаления
В базе данных есть только один объект с id=1. Попытаемся удалить этот объект.
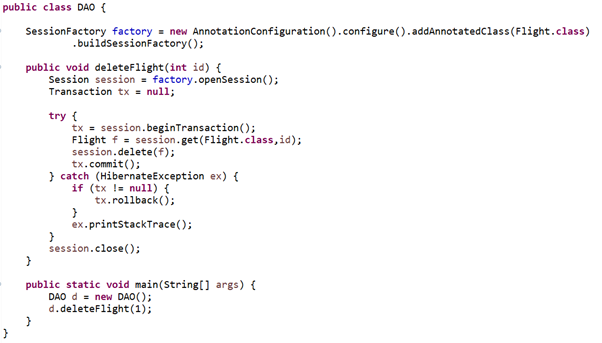
После выполнения метода deleteFlight таблица становится пустой. В приведенном выше коде мы сначала извлекли объект по его идентификатору и передали его методу удаления. Если все пойдет хорошо, транзакция окажется зафиксирована, в противном случае выполнится откат.
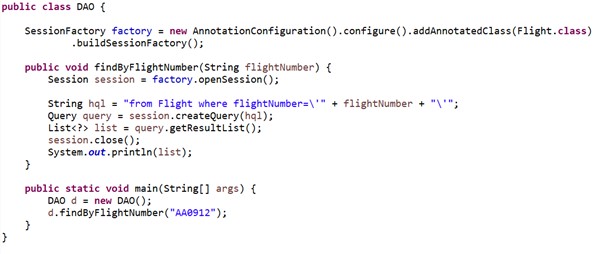
И еще одно: хотим ли мы обновить объект в базе данных или удалить его, нам понадобится значение его первичного ключа. Однако у нас не всегда есть возможность его получить. Кроме того, для этого необходимо выполнять сложные операции с данными. Цели можно достичь с помощью HQL, аналогичного SQL, но он удаляет шаблонный код. Это означает, что теперь не нужно использовать операторы select с запросами.
Все, что мы изучили, также можно повторить, посмотрев это видео.
Читайте также:
- Не самые очевидные советы по написанию DTO на Java
- 3 применения исключений, которые улучшат навыки программирования на Java
- Учимся избегать null-значений в современном Java. Часть 1
Читайте нас в Telegram, VK и Дзен
Перевод статьи Reetinder Bhullar: Java Hibernate





