
Данные многое вам скажут, если вы готовы слушать.
— Джим Бергесон
Данные можно назвать Богом. Все на свете проверяется только благодаря данным. Вы не сможете претендовать на свою собственность, имущество, если у вас нет подтверждающих данных. Невозможно даже удостоверить свою личность при отсутствии соответствующих данных. Все, что мы делаем, покупаем или продаем, порождает данные. Разве это не удивительно?
В настоящее время мы нуждаемся в данных так же сильно, как в кислороде. Данные стали одной из базовых потребностей в нашей жизни. А знаете ли вы, что представляют собой данные в области науки о данных и искусственного интеллекта? Поговорим об этом.
Что такое данные?
Данные — это набор фактической информации, такой как количества, размеры, описания или наблюдения. Данными могут быть цифры, текст, изображение, аудио, видео, графики, таблицы, шаблоны и т. д. Компании анализируют данные своих заказчиков и клиентов, чтобы понимать их поведение.
Зачем нам нужны данные?
Данные могут предоставить нам информацию и ценные сведения о поведении определенной категории людей, сообщества или организации. Крупные компании, такие как Google, Facebook, Amazon, изучают наши модели поведения с помощью данных, чтобы узнать наши потребности, жизненные ситуации, настроения, образ жизни, и рекомендуют нам продукты, музыку, видео, которые отвечают нашему выбору.
Типы данных
В зависимости от формата, данные можно разделить на две группы:
1. Структурированные.
2. Неструктурированные.
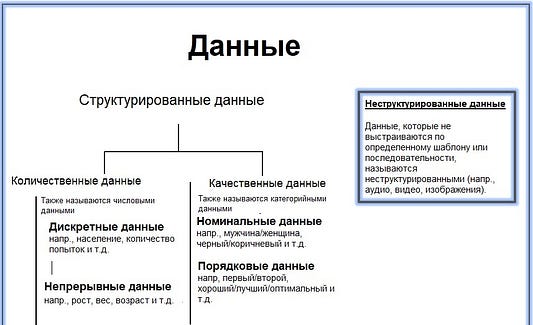
Структурированные данные
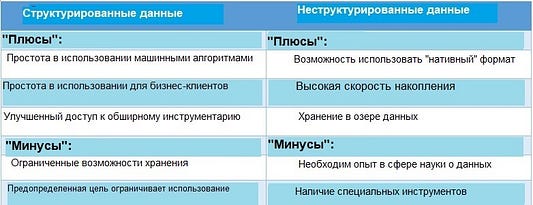
Данные, имеющие заранее определенный формат, называются структурированными. Как правило, они хранятся в RDBMS — реляционных СУБД (системах управления базами данных). Структурированные данные обычно состоят из цифр или текста. Структурированные данные занимают меньше времени при обработке по сравнению с неструктурированными данными. Структурированные данные бывают двух типов:
- качественные;
- количественные.
Качественные данные
Качественные данные, также известные как категориальные данные, представляют характеристики объекта; пол, семейное положение, рейтинг и т.д.
Категориальные переменные, в зависимости от количества значений в категории, подразделяются на два вида:
- двоичные (или дихотомические): имеют два значения (например, Мужчина/Женщина, Истина/Ложь, Да/Нет и т. д.);
- политомные: имеют более двух значений (например, Рейтинг: Первый/Второй/Третий; Семейное положение: Женат/Не женат/Разведен и т. д.).
На основе шкал измерений категориальные переменные делятся на следующие виды:
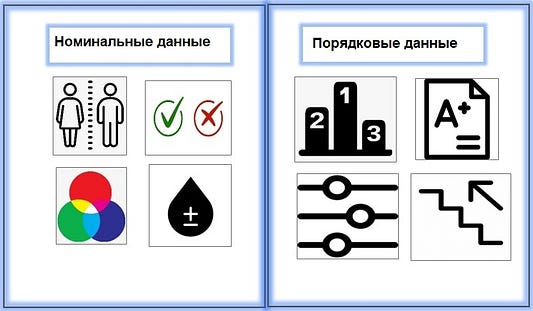
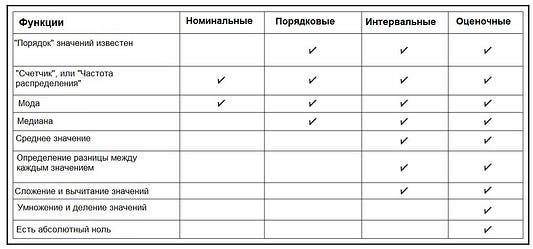
- номинальные: категориальные переменные, в которой порядок данных не имеет значения, например, Пол, Цвет волос, значения типа Bool, Группы крови и т. д. (ПРИМЕЧАНИЕ: мы можем, если нужно, кодировать номинальные переменные числами, но в произвольном порядке; при этом любые вычислительные операции, будь то вычисление среднего арифметического, медианы или стандартного отклонения, бессмысленны);
- порядковые: категориальные переменные, в которых важен порядок данных. например, Рейтинг, Оценки, Уровни, Этажи и т. д.
- интервальные: для категориальных переменных, измеренных на интервальной шкале, значимы как порядок, так и точные различия между значениями, например, Температура, значение рН, Кредитный рейтинг.
- оценочные: категориальные переменные, измеренные на шкале отношений, содержат порядок, точные значения и абсолютный ноль; следовательно, они используется как для описательной, так и для логической статистики, например, для Плотности, Скорости и т. д.
Количественные данные
Данные, которые могут быть выражены в виде чисел и представляют собой измеренные значения, называются количественными. Они также известны как числовые данные. На основе значений числовые данные подразделяются на две группы:
- Дискретные — данные, которые являются счетными и могут принимать как числовые, так и категориальные значения, в зависимости от использования. Переменная, представляющая дискретный набор данных, называется дискретной переменной. Дискретные данные всегда имеют фиксированное на данный момент значение, например, Возраст, Количество учащихся в классе, Количество планет и т. д.
- Непрерывные — переменные с бесконечным числом числовых значений в определенном диапазоне, например, Вес, Рост и т. д.
ПРИМЕЧАНИЕ: процентные значения также являются непрерывными данными.
Неструктурированные данные
Любые данные, хранящиеся в собственном формате, называются неструктурированными данными. К ним относятся изображения, аудио, видео, сообщения в чате. Для использования неструктурированных данных требуется их предварительная обработка с целью интеллектуального анализа.
Структурированные и неструктурированные данные
Сбор данных
Чтобы выполнить аналитическую работу, самое важное, что нам нужно, — это собрать данные. Сбор данных может осуществляться несколькими способами. Рассмотрим некоторые из них.
Сбор первичных исходных данных
При этом методе необработанные данные генерируются вручную. Осуществляется такой процесс с помощью онлайн-опросов, интервью, наблюдений и т. д. Использование необработанных данных имеет как “плюсы”, так и “минусы”.
Преимущества:
- возможность получить именно ту информацию, которая необходима;
- надежность и оригинальность полученных данных;
- никаких проблем с разрешением на использование данных;
- приобретение актуальной и свежей информации.
Недостатки:
- потребность в большом количестве времени;
- высокая стоимость;
- необходимость в дополнительной очистке и модификации перед анализом.
Сбор данных из вторичных источников
При этом методе используются сохраненные данные. Источниками являются базы данных или веб-сайты с открытым исходным кодом для сбора и анализа данных.
Преимущества:
- не отнимает много времени;
- легкодоступность;
- как правило, вторичные данные отформатированы в таблицы.
Недостатки:
- требуется разрешение на доступ.
- сомнительная надежность данных.
Веб-скрейпинг
При этом методе данные извлекаются из веб-страниц. С помощью некоторых библиотек и общих знаний о HTML можно легко собрать данные с веб-сайтов. Как правило, мы используем веб-скрейпинг при анализе обзоров и комментариев. Библиотеки Python, используемые для веб-скрейпинга, — request, BeautifulSoup, Pandas, Selenium.
ПРИМЕЧАНИЕ: Не все веб-сайты поддерживают веб-скрейпинг. Вам нужно получить разрешение на извлечение данных с таких веб-ресурсов. Несанкционированный сбор данных — это преступление.
Формат файлов
Данные хранятся в нескольких форматах. Рассмотрим наиболее часто используемые файлы данных:
- CSV-файлы: файлы значений с разделителями-запятыми представляют собой обычные текстовые файлы, в которых значения строк разделены запятыми. Каждая строка файла представляет собой запись данных, а запятые разделяют запись на разные поля. CSV-файлы обычно встречаются в электронных таблицах и базах данных.
- XLSX-файлы: файлы MS Excel хранятся в формате xlsx. В этих файлах значения находятся в строках и столбцах. XLSX-файлы обычно встречаются в электронных таблицах и базах данных.
- TXT-файлы: текстовые файлы представлены в формате txt. В файлах этого типа мы храним текстовые данные.
- JSON-файлы: JSON буквально означает “JavaScript Object Notation” (“нотация объектов JavaScript”). Эти файлы представляют собой упрощенный текстовой открытый стандарт, предназначенный для обмена данными через Интернет.
Примерами наиболее распространенных файлов являются изображения, PDF-файлы, HTML.
Заключение
Вы получили базовое представление о данных. Оно необходимо каждому, кто хочет изучать науку о данных. Знание основ этой науки значительно облегчит вам большую часть будущей работы. Благодарим за то, что остались с нами до конца.
Читайте также:
- Как специалисту по обработке данных создать крутое портфолио и подключить к нему чат-бота
- Основы обработки естественного языка за 10 минут
- LeetCode - удаление дублей из отсортированного массива
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Nitin Kumar Singh, Data





