
Предыстория и личный интерес
Не так давно компания Google предоставила во всеобщее пользование свою облачную платформу для машинного обучения — Vertex AI. Моей радости просто нет предела, поскольку я давно мечтал стать свидетелем согласованного целостного сценария рабочих процессов МО на Google Cloud. Годами данная платформа разрабатывала сервисы и инструменты, связанные с МО. И вот наконец появилась возможность объединить их все в одну интегрированную платформу.
Переполняемый большими ожиданиями я приступил к изучению документации. Надо сказать, кое-что в ней требует доработки. Она отличается внушительным объемом преимущественно отличного содержания, но при этом в ней нарушена логика структурирования материала. Документация напоминает толстый сборник статей, которые связаны между собой несколькими состряпанными в последнюю минуту одностраничниками по типу указателей. Так сразу и не разберешься, где начало. Кроме того, поскольку затруднительно определить, какие из предложенных ссылок действительно важны, то приходится отвлекаться и просматривать каждую из них.
Учитывая мою любовь к базовым сервисам, мне бы хотелось не только научиться более эффективно с ними работать, но и поделиться о них знаниями. Именно этим обусловлено появление данного руководства по Vertex AI. Отметим, что предварительный опыт работы с сервисами МО Google Cloud не требуется.
Начнем с азов и создадим нашу первую модель, обученную на Vertex AI.
Предварительные требования
Прежде всего, для достижения поставленной цели потребуются базовые знания платформы Google Cloud. Кроме того, нужно будет создать проект Google Cloud, а также настроить стандартные утилиты командной строки, такие как gcloud (Google Cloud SDK) и gsutil (Google Cloud Storage utils).
Примечание: Далее в коде и командах используются плейсхолдеры пути, такие как GCS_PATH_FOR_*. В форме gs://bucket/[folder]/[sub_folder]/ вы укажите свои собственные. Материал статьи также предполагает знание основ Tensorflow. В ней мы будем задействовать только высокоуровневые API, не требующие объяснений, поэтому вам не о чем волноваться, даже если вы не большой знаток Tensorflow.
По мере изучения статьи вы проверите, насколько ваш уровень подготовленности соответствует описанным предварительным требованиям. Если вы чувствуете, что материал выходит за рамки имеющихся у вас знаний, то вам следует поглубже изучить указанные темы, прежде чем двигаться дальше.
Постановка задачи
В данной статье мы решим довольно простую задачу классификации изображений. Как правило, всеобщее предпочтение отдается датасету MNIST. Но поскольку он представлен в серой цветовой палитре, а душа просит ярких красок, то выберем CIFAR10. Этот набор данных содержит 60 000 цветных изображений 32×32 в 10 классах, по 6000 изображений на класс. Далее вы увидите примеры этих изображений.
Подготовка среды разработки
В качестве основной среды разработки для последующего взаимодействия выбираем JupyterLab. Из нее мы сможем писать интерактивный код Python и легко получать доступ к терминалу командной строки. JupyterLab можно установить и локально. Однако если вы обладаете опытом работы в области МО, то, вероятно, этот инструмент у вас уже есть.
Советую использовать Notebook в Vertex AI (ее управляемую версию JupyterLab). Обусловлено это двумя причинами. Во-первых, в этот инструмент разработки встроены все стандартные пакеты МО. Во-вторых, его конфигурация предусматривает подсоединение к другим сервисам Google Cloud, что избавляет от досадной необходимости заморачиваться насчет настроек авторизации и подключения. И наконец, он позволяет расширять возможности локальной рабочей станции. Например, для увеличения CPU/RAM/GPU понадобится лишь блокнот Notebook с поддержкой соответствующего типа машины. В случае потребности в большем объеме диска достаточно создать диск Google Cloud и подсоединить его к виртуальной машине Notebook. С учетом того, что настроить этот инструмент довольно просто, буквально пара-тройка кликов, и к тому же данное руководство не предполагает работы с ним, то здесь я не буду загружать вас инструкциями. Но если интересно, можете самостоятельно ознакомиться с его документацией.
Весь код Python и команды из консоли по умолчанию будут выполняться в JupyterLab, если не обозначен другой способ.
Подготовка данных
Подготовка данных — первоочередная задача в любом проекте МО. В нашем случае CIFAR10 уже входит в каталог датасетов Tensorflow. Но для имитации реальной разработки проекта МО мы обработаем датасет и загрузим его в хранилище Google Cloud Storage (GCS) для последующей работы. Многие функции Tensorflow имеют встроенную поддержку GCS.Выполним эту процедуру лишь раз, после чего результат будет повторно использоваться для дальнейшего обучения и валидации модели.
В нескольких строках кода скачиваем датасет, предварительно его обрабатываем и создаем образцы Tensorflow для обучающей, контрольной и тестовой выборок.
import tensorflow as tf
(train_images, train_labels), (test_images, test_labels) = tf.keras.dataset.cifar10.load_data()
def preprocess(filename, images, labels):
with tf.io.TFRecordWriter(filename) as writer:
for image, label in zip(images, labels):
# Кодирование изображения и метки в tf.train.Example.
feature = {
# Нормализация изображение в диапазоне [0, 1].
'image': tf.train.Feature(float_list=tf.train.FloatList(value=(image/255.0).reshape(-1))),
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=label))
}
example = tf.train.Example(features=tf.train.Features(feature=feature))
writer.write(example.SerializeToString())
preprocess('train.tfrecord', train_images[:40000], train_labels[:40000])
preprocess('val.tfrecord', train_images[40000:], train_labels[40000:])
preprocess('test.tfrecord', test_images, test_labels)Затем копируем файлы в корзину GCS для дальнейшего использования. Настоятельно рекомендую сосредоточить Vertex AI Notebook (если вы его используете), корзину GCS и последующие сервисы Vertex AI в одной области. Это не только позволит повысить производительность, но и поможет предотвратить ряд непредвиденных проблем взаимодействия между областями, которые могут возникнуть в процессе работы.
gsutil -m cp *.tfrecord GCS_PATH_FOR_DATA
Проверяем, что данные в GCS доступны и закодированы корректно. Далее получаем, декодируем и отображаем несколько изображений из фалов образцов Tensorflow. Ниже представлен код валидации данных:
import matplotlib.pyplot as plt
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
dataset = tf.data.TFRecordDataset([GCS_PATH_FOR_DATA + 'train.tfrecord'])
plt.figure(figsize=(10, 10))
for i, example in enumerate(dataset.take(16)):
data = tf.train.Example()
data.ParseFromString(example.numpy())
image = tf.constant(data.features.feature['image'].float_list.value, shape=[32, 32, 3])
label = data.features.feature['label'].int64_list.value[0]
plt.subplot(4, 4, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(image.numpy())
plt.xlabel(class_names[label])
plt.show()
Обучение модели локально
Перед началом работы на Vertex AI обучим модель локально и убедимся, что все сделано правильно. Сначала готовим входные датасеты. Перед вами код создания датасета Tensorflow:
def extract(example):
data = tf.io.parse_example(
example,
# Схема образца.
{
'image': tf.io.FixedLenFeature(shape=(32, 32, 3), dtype=tf.float32),
'label': tf.io.FixedLenFeature(shape=(), dtype=tf.int64)
}
)
return data['image'], data['label']
def get_dataset(filename):
return tf.data.TFRecordDataset([GCS_PATH_FOR_DATA + filename]).
map(extract, num_parallel_calls=tf.data.experimental.AUTOTUNE).
shuffle(1024).
batch(128).
cache().
prefetch(tf.data.experimental.AUTOTUNE)
train_dataset = get_dataset('train.tfrecord')
val_dataset = get_dataset('val.tfrecord')
test_dataset = get_dataset('test.tfrecord')Затем строим модель. Ее архитектура содержит несколько сверточных слоев, за которыми следуют уплощенные полносвязные слои, и в итоге на выходе выдает вероятность 10 классов. Ниже представлен код построения модели:
from tensorflow.keras import layers, models, losses
def create_model():
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D(2, 2),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D(2, 2),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimier='adam', loss=losses.SparseCategoricalCrossentropy(), metrics=['accuracy'])
return model
model = create_model()Теперь приступаем к обучению модели.
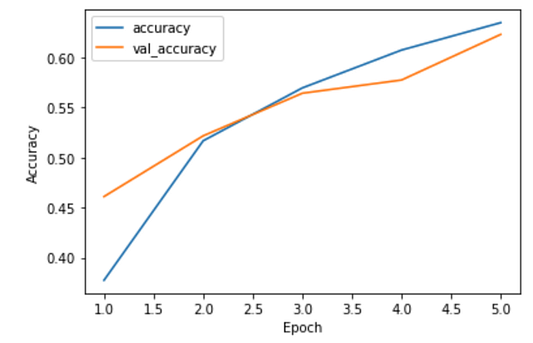
Код обучения модели:
model.fit(train_dataset, epochs=5, validation_data=val_dataset)
model.evaluate(test_dataset, verbose=2)
# Потери на выходе: 1.0985 - accuracy: 0.6060Точность модели составляет всего лишь 60% на тестовом датасете — так себе результат, требующей дальнейшей проработки. Но в настоящий момент нас больше интересует тот факт, что процесс локального обучения модели прошел от начала до конца.
Обучение модели на Vertex AI
Пришло время перемещаться в Cloud. По отношению к модели применим следующие операции:
- Нам нужно поместить ее в рамки стратегии распределенного обучения, чтобы она могла воспользоваться преимуществами аппаратного оборудования при его наличии.
- Также потребуется сохранять контрольные точки обучения на случай прерывания обслуживания машин в облаке.
- По завершении обучения экспортируем обученную модель.
Приведем окончательный код построения модели:
# Распределенная стратегия для эффективного применения имеющегося оборудования.
# В противном случае никаких операций.
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = create_model()
# Восстановление из последней контрольной точки при ее наличии.
latest_ckpt = tf.train.latest_checkpoint(GCS_PATH_FOR_CHECKPOINTS)
if latest_ckpt:
model.load_weights(latest_ckpt)
# Создание обратного вызова для сохранения проверки в конце каждой эпохи.
ckpt_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=GCS_PATH_FOR_CHECKPOINTS + CHECKPOINTS_PREFIX,
monitor='val_loss',
save_weights_only=True
)
model.fit(train_dataset, epochs=EPOCHS, validation_data=val_dataset, callbacks=[ckpt_callback])
# Экспорт модели в GCS.
model.save(GCS_PATH_FOR_SAVED_MODEL)Теперь у нас все готово для обучения модели на Vertex AI. На высоком уровне этот процесс включает следующие этапы:
- Небольшая реструктуризация кода для использования его на Vertex AI.
- Сборка дистрибутива Python и его загрузка в GCS для обеспечения к нему доступа Vertex AI.
- Запуск задания обучения посредством вызова инструмента командной строки
gcloudи указание соответствующих параметров. - Мониторинг статуса задания вплоть до его выполнения.
Реструктуризация кода
Обучающая среда на Vertex AI похожа на среду JupyterLab, а запуск задания обучения происходит аналогично локальному запуску программы Python. Такая программа у нас уже есть — достаточно лишь перенести все фрагменты кода из раздела “Обучение модели локально” в файл .py (task.py в соответствии с соглашением). Не забудьте преобразовать его для упомянутых ранее целей: распределенной стратегии, сохранения контрольных точек и экспорта модели.
Помимо этого, добавим в программу несколько эпох в качестве аргумента. Ниже представлен код аргумента модели:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', dest='epochs', type=int, default=5)
args = parser.parse_args()
# Обращаемся к аргументу как args.epochs.Попробуйте запустить обучение локально и проверьте, что все работает. При обучении на Vertex AI нам придется подождать, пока задание не будет распланировано, что занимает определенное время. Но мы ведь не хотим, чтобы оно провалилось из-за глупой ошибки.
python task.py --epochs=1
Сборка и загрузка дистрибутива Python
На этом этапе необходимо укомплектовать дистрибутив Python. Структурируем каталог следующим образом:
|-- setup.py
|-- trainer
|-- task.py
|-- __init__.pyФайл task.py — программа Python, которую мы собрали и локально протестировали. Помещаем его в каталог trainer. Файл __init__.py — пустой файл Python для разграничения модуля. Ознакомимся с основным содержимым файла setup.py:
from setuptools import find_packages
from setuptools import setup
setup(
name='trainer',
version='0.1',
packages=find_packages(),
include_package_data=True,
description='An E2E Tutorial of Vertex AI'
)В случае необходимости установить другие стандартные зависимости пакета Python вы можете объявить их в файле setup.py. Здесь же у нас все просто, поскольку мы руководствуемся демонстрационными целями.
Теперь упаковываем дистрибутив Python. Следующая команда генерирует файл trainer-0.1.tar.gz в только что созданном каталоге dist.
python setup.py sdist --formats=gztar
Копируем дистрибутив Python в GCS, чтобы Vertex AI могла получить к нему доступ.
gsutil cp dist/trainer-0.1.tar.gz GCS_PATH_FOR_PYTHON_CODE
Запуск задания обучения
Итак, у нас все готово для запуска задания обучения на Vertex AI. Документация к этому разделу немного непонятна, так что рассмотрим порядок действий.
Перед тем как продолжить, проясним следующее: мы запускаем настраиваемое задание обучения с помощью предварительно подготовленного контейнера. Задание настраиваемое, потому что мы создаем модель с нуля. Используемый контейнер — это среда, в которой выполняется код обучения. Вы могли бы обучать с помощью своего настраиваемого контейнера, содержащего заданные вами инструменты и зависимости. Но в рамках данной статьи мы не будем рассматривать этот усложненный сценарий, а сосредоточимся на простом рабочем процессе от “а” до “я”.
Запускаем обучение посредством инструмента командной строки gcloud. Vertex AI обладает встроенной подкомандой gcloud (она еще на стадии бета-тестирования).
gcloud beta ai custom-jobs create --region=us-central1 --display-name=e2e-tutorial --config=config.yaml
Основная часть команды находится в файле config.yaml. Можно также указать отдельные аргументы в командной строке, но я советую использовать файл конфигурации, учитывая немалое количество таких аргументов. Схема конфигурации также недостаточно хорошо задокументирована. Отметим, что на самом деле это параметры метода API (ссылка).
workerPoolSpecs:
machineSpec:
# Машины и GPU: https://cloud.google.com/vertex-ai/docs/training/configure-compute#указываем _gpus
machineType: n1-standard-4
acceleratorType: NVIDIA_TESLA_V100
acceleratorCount: 2
replicaCount: 1
pythonPackageSpec:
# Исполнители: https://cloud.google.com/vertex-ai/docs/training/pre-built-containers
executorImageUri: us-docker.pkg.dev/vertex-ai/training/tf-gpu.2-3:latest
packageUris: GCS_PATH_FOR_PYTHON_CODE
pythonModule: trainer.task
# Обучение в течение 15 эпох.
args: --epochs=15Мониторинг статуса задания
Команда custom-jobs create вернет ID задания для проверки статуса. Просто вызываем следующую команду для определения состояния задания.
gcloud beta ai custom-jobs describe JOB_ID --region=us-central1
Если все проходит успешно, то через несколько минут в статусе задания вы увидите JOB_STATE_SUCCEEDED. Возможен вариант проверки состояния в облачной консоли. Переходим в Vertex AI -> Training -> Custom Job и кликаем на “e2e-tutorial” для изучения подробной информации. Можно также пройти по ссылке View Logs для ознакомления с результатами задания обучения.
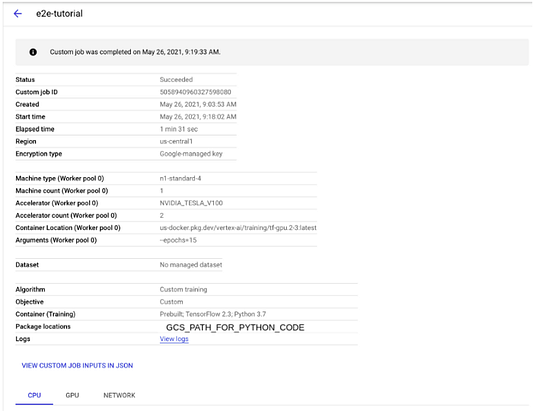
Проверка модели
Итак, мы обучили модель на Vertex AI и сохранили ее в Google Cloud Storage. Перед подведением итогов уделим внимание анализу модели в JupyterLab:
cloud_model = tf.keras.models.load_model(GCS_PATH_FOR_SAVED_MODEL)
# Компилируем модель, чтобы убедиться, что она использует правильную метрику точности.
cloud_model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy'])
cloud_model.evaluate(test_dataset, verbose=2)
# Потери на выходе:0.917 - accuracy: 0.6620Как видим, точность повысилась с 60% (локальное обучение с 5 эпохами) до 66% (обучение с 15 эпохами на Vertex AI).
Заключение
На этом все. Не забудьте очистить ресурсы Google Cloud, если вы создавали блокнот Vertex AI. Мощные виртуальные машины могут оказаться весьма дорогостоящими.
Читайте также:
- Как специалисту по обработке данных создать крутое портфолио и подключить к нему чат-бота
- Основы обработки естественного языка за 10 минут
- Автоматический анализ текста с использованием Streamlit
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Eileen Pangu: A Step-by-Step Guide to Training a Model on Google Cloud’s Vertex AI





