
Те, кто занят в сфере искусственного интеллекта, в том числе и в проекте Deepnews, часто презентуют свои новейшие модели как инновационные и эффективные средства для выполнения задач и помощи людям.
Но не будем забывать, что исходным материалом для создания этих моделей являются данные. Поэтому некоторые члены ИИ-сообщества все чаще призывают специалистов по разработке искусственного интеллекта перейти от “модельно-ориентированного” подхода к “ориентированному на данные”. Ведь оптимизация любой программы требует от разработчиков концентрации на том, что они вкладывают в свою модель, а не на коде, приводящем ее в исполнение.
В последние годы более пристальное внимание стали уделять тому, что именно подается в машины, помогающие выполнять различные задачи — от освещения качественных новостей до внесения изменений в правоохранительную сферу. Допущенные при этом ошибки могут иметь катастрофические последствия. Наряду с проблемой предвзятости из-за отсутствия исчерпывающих данных по определенным группам, все чаще поднимается вопрос о неточных данных, используемых при разработке алгоритмов.
Кертис Норткатт, научный сотрудник Массачусетского технологического института, протестировал основные наборы данных с целью выяснить, насколько верно они размечены. С помощью таких тестовых выборок можно определить, действительно ли хороша новая модель. К примеру, в базе ImageNet находятся десятки тысяч визуальный моделей, помеченных в соответствии с классом каждой из них (изображение бейсбольного мяча помечено как “бейсбольный мяч”). Таким образом, создателю новой визуальной модели, желающему убедиться в ее эффективности, есть что проверить.

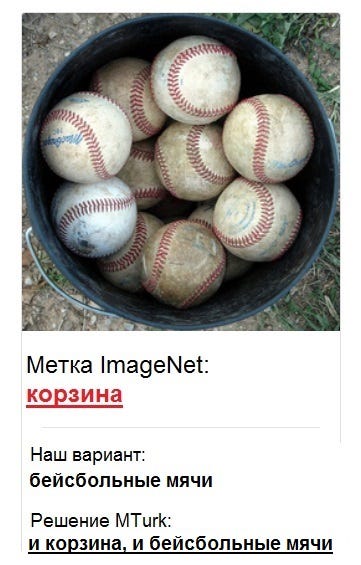
В ходе исследования Кертис Норткатт обнаружил, что значительная часть данных тестовых наборов (5,8% в случае ImageNet и выше в других проектах) была неправильно размечена. Ошибки варьировались от полностью неверного толкования изображений до неправильной идентификации породы собаки или недостаточного количества меток. Так, изображение корзины с бейсбольными мячами было помечено одной меткой “корзина” (с пропуском метки “бейсбольные мячи”), что позволяет назвать данные модели неточными и вызывает сомнение в ее эффективности. Норткатт сравнивает тестовые наборы данных с ключами к школьным экзаменационным тестам, с помощью которых учитель определяет тех, кто достоин высоких баллов и может претендовать на углубленное обучение.
“Если эти тестовые наборы ошибочны, то и наши критерии ошибочны, а значит, мы понятия не имеем, как продвигается машинное обучение”, — считает исследователь.
Конечно, трудно и довольно затратно заставить людей проверять на правильность каждый бит — тысячи строк данных. Поэтому исследование Норткатта можно считать прорывом в этой области, проложившим путь к планомерному выявлению мест, где могут быть ошибки. С помощью метода, получившего название “уверенное обучение”, он со своей командой открыл способ нахождения неверных меток путем поиска мест потенциальных ошибок, когда само изображение “убеждает” в том, что ему присвоен ложный класс (“корзина с бейсбольными мячами”, а не просто “корзина”).
Все обнаруженные ошибки были проверены людьми, в результате чего исследователи пришли к окончательному выводу: количество неверно размеченных данных сногсшибательно. Вы можете найти несколько любопытных примеров на Labelerrors.com.
Тот факт, что в разработке ИИ допускается так много ошибок, уже сам по себе достоин внимания. Но команда Норткатта пошла дальше и протестировала известные ИИ-модели сначала с ошибочными, а потом с исправленными данными. Выяснилось, что некоторые менее продвинутые, менее сложные модели лучше работают на откорректированных тестовых наборах. Это означает, что они будут эффективнее в “реальном мире”.
“Более простые модели, когда много шума, не могут адаптироваться к нему”, — такое заключение сделал Норткатт.
Проблема, по-видимому, заключается в том, что некоторые более продвинутые и сложные модели усвоили неверно помеченные данные. Это как если бы учитель готовил учеников к тесту, не имеющему правильных ответов. Вот почему тестированию на выявление неверно помеченных данных стоит подвергать наиболее популярные ИИ-модели. Так, OpenAI’s CLIP протестировал себя на ImageNet.
Что же нам делать со всеми этими ошибками? Свою лепту в решение проблемы внес Норткатт. Убежденный сторонник сохранения данных с открытым исходным кодом, он предоставил доступ к очищенным версиям тестовых наборов на своей GitHub-странице.
Помимо этого, необходимо, по-видимому, изменение самого подхода к ИИ-разработкам. Недостаточно просто анонсировать модель с верными верхними цифрами — нужно сосредоточиться на данных, которые могут повысить ее продуктивность. В Deepnews, например, уже создали англоязычный тестовый набор данных для различных категорий новостей (местных, общенациональных и т. д.). Осуществляли это вручную с человеческими метками 1, 2, 3, 4 или 5. То же самое — с аналогичными категориями новостей — делается сейчас для французов. Процесс этот новый и весьма кропотливый, ведь у разработчиков Deepnews нет общедоступного тестового набора данных, который можно было бы использовать. Однако овчинка выделки стоит: занимая немало времени, “уверенное обучение” позволит учитывать места возможных погрешностей и в результате создавать модели, максимально полезные пользователю.
Работа, подобная исследованию Норткатта, становится все более необходимой по мере того, как мы учимся разрабатывать эффективные и надежные модели искусственного интеллекта. Для тех, кто хочет углубиться в идею “уверенного обучения” и связанные с ней темы, Норткатт рекомендует ознакомиться со статьей экспертов из Калифорнийского университета в Сан-Диего, а также с проектом Snorkel.
Читайте также:
- Как ИИ меняет сферу финансов
- Искусственный интеллект оживит наших близких
- Я хочу изучать AI и машинное обучение. С чего мне начать?
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Christopher Brennan, Big AIs made with the help of bad data





