
Балансировка нагрузки необходима, если в приложении ожидается или уже есть большой объем трафика, но дело усложняется, когда доходит до разработки потока аутентификации и авторизации.
Зачем балансировать нагрузку?
В сценариях с высоким трафиком — например, размещение веб-сайта социальной сети, популярного блога, API или практически любого веб-приложения с большим количеством входящих запросов — физический сервер часто оказывается перегружен обработкой всех этих запросов и отправкой нужных ответов.
Далее в статье мы рассмотрим как очевидные, так и более глубокие последствия масштабирования потока аутентификации и авторизации в системе, которая не может гарантировать, что последующие запросы от того же клиента будут обработаны тем же сервером.
Что такое балансировка нагрузки?
Если вкратце, балансировка нагрузки — это процесс распределения трафика между несколькими экземплярами сервера с применением определенного алгоритма. Аналогом будет полицейский перед платной автопарковкой, который перенаправляет вас к посту с самой маленькой очередью.

Предположим, исходный сервер, предоставленный хостинговой платформой, может обрабатывать максимум тысячу запросов в секунду, прежде чем время ожидания станет вызывать недовольство. Вы процветаете, и пользователи начинают всё активнее пользоваться вашим приложением, отсюда и трафик. Вам ведь не хочется, чтобы пользователи возмущались.
Дальше такими темпами вы реализуете балансировщик нагрузки: либо платите за экземпляр, предоставленный AWS или другим поставщиком услуг, либо тратите время на настройку своего собственного. Но балансировщик нагрузки не будет работать сам, как по волшебству. Чтобы балансировщик знал, куда перенаправить запрос, нужно несколько серверов, и это чревато новой проблемой, когда дело доходит до потока аутентификации. Посмотрим, почему это так.
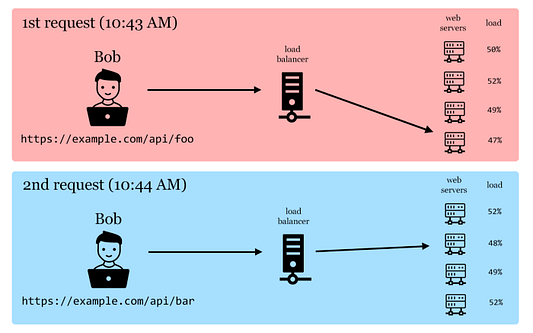
Как видите, даже если Боб отправляет два запроса к одному и тому же API за очень небольшой промежуток времени, ответ все равно обрабатывается разными экземплярами сервера. Значит, вы никак не можете предсказать, какой экземпляр в конечном итоге обработает запрос клиента. А даже если и можете, то это уже вряд ли получится, если балансировщик нагрузки будет делать свою работу как следует.
Аутентификация и авторизация
JWT, разумеется
В эпоху, когда создать веб-сайт может каждый, для аутентификации широко применяется JWT, который очень просто реализован.
И он работает. Причём быстро и вполне надёжно.
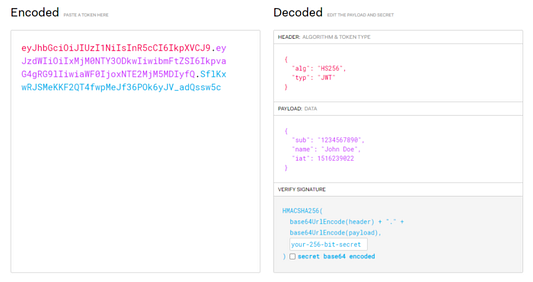
На первый взгляд кажется, что нашлось очевидное решение всех наших проблем, независимо от балансировки нагрузки. Речь о том, что JWT практически не требуется бэкенд для валидации и авторизации, информация о пользователе непосредственно встроена в токен, уменьшая необходимость в запросах к базе данных, и все данные хранятся на клиенте, экономя столь необходимую память сервера. Довольно умно, казалось бы. Но нет.
Когда вы начинаете разработку аутентификации пользователей, проблемы появляются уже при создании функции “сброс пароля”. До этого момента преимущество JWT было в том, что достоверность информации при аутентификации или авторизации проверялась без участия базы данных. Но когда пользователь решает сбросить пароль, потому что забыл его или по какой-то другой причине, вам нужен способ выйти из его аккаунта на всех остальных устройствах.
Как вы реализуете истечение доступа для вашего пользователя, не дожидаясь, пока он выйдет сам? Быстрый способ — изменить ключ шифрования. Но подождите, это приведет к истечению срока действия всех токенов ваших пользователей… Есть другая идея. Может быть, интегрировать базу данных, которая содержит все просроченные ключи, и проверять по ней? Или, может быть, в базе будут все действительные ключи? Как было бы просто: сначала проверьте, действителен ли сам JWT, а затем проверьте по базе данных, не занесен ли он в черный список.
Но подождите, разве так не отправляются в мусор пресловутые преимущества JWT — “быстродействие, отсутствие необходимости обращения к базе данных, скорость проверок”? В некотором роде. Тогда, скажете вы, надо добавить кэширование, чтобы уменьшить серфинг по базе данных. Да, это сработает, но имейте в виду: кэш также необходимо разделять между несколькими экземплярами веб-сервера, и реализация должна быть отказоустойчивой, особенно для функций, связанных с безопасностью пользователя (к примеру, сброс пароля).
Если история на этом закончится, то вам повезло. Если все пойдет хорошо, это будет не последний раз, когда вы масштабируете свое приложение. Следующим шагом будет добавление еще одного балансировщика нагрузки и другого кластера веб-серверов и, возможно, даже геомаршрутизации для отправки запросов к ближайшему доступному балансировщику нагрузки, чтобы уменьшить задержку. Готовы ли вы гарантировать согласованность между несколькими распределенными кэшами? Это большая головная боль.
Sticky session
Применение сессий дает клиенту уникальный идентификатор (назовем его ключом), и пользователь передает этот ключ в последующих запросах, чтобы сервер знал, с кем он взаимодействует. Ключи лучше всего хранить в защищенных файлах cookie, доступных только по протоколу HTTP. Сервер хранит информацию о пользователе в таблице поиска под сгенерированным ключом, и любой запрос просто использует этот ключ для извлечения данных, связанных с клиентом, который ожидает ответа. Здесь прослеживается проблема. Допустим, у вас есть несколько веб-серверов. Как гарантировать, что сессия на всех серверах с балансировкой нагрузки будет одна и та же?
“Липкие сессии” пытаются решить эту проблему, заставляя балансировщик нагрузки отправлять все последующие запросы на один и тот же веб-сервер. Частично это срабатывает, но помимо вопиющей лени (в нормальных обстоятельствах) у этого подхода также есть несколько других недостатков:
- Ваши серверы будут загружены неравномерно. Некоторые пользователи проведут на вашем сайте больше времени, чем другие.
- Балансировщик нагрузки не станет читать и обрабатывать запрос, это не его работа. Определить, откуда поступает запрос, он может только по IP-адресу, и не думаю, что мне нужно говорить вам, сколько людей используют данные с мобильных телефонов, а затем переключаются на wi-fi в кафе. В результате сессия теряется. Одним словом: неконсистентность.
Распределенные сессии
Другой достойный участник этого конкурса — распределенный кэш + состояние сеанса = распределенные сессии. По факту, сейчас состязание идет между JWT и распределенным состоянием сессии, поскольку в среде с балансировкой нагрузки и тому, и другому необходим распределенный кэш.
Или, по крайней мере, в обоих случаях распределенный кэш стоит реализовать в среде с балансировкой нагрузки, поскольку любое другое решение менее эффективно и более хлопотно. Вам вряд ли захочется хранить копию одних и тех же кэшированных данных на каждом сервере и обновлять несколько экземпляров сервера всякий раз, когда вносятся изменения.
Прежде чем рассказать, почему этот подход для крупномасштабных приложений лучше и эффективнее JWT, давайте рассмотрим принцип его работы.
Вы наверняка уже догадались, но всё-таки: что такое распределенный кэш? Распределенный кэш — это просто кэш, доступный нескольким сторонам. Он предоставляет слой согласованных данных между всеми вашими серверами. Применение простое: сервер ищет некоторую информацию, и если она кэширована, то забирает ее, и на том конец. Если это не так, то сервер получает информацию из постоянного источника (базы данных), кэширует, чтобы в будущем получить к ней скорейший доступ, а затем использует. Что особенно важно для хранения состояния сессии, срок действия данных в кэше истекает нелинейно, так что они не остаются там, когда не нужны. Если к кэшу не обращались в течение двадцати минут, то он удаляется.
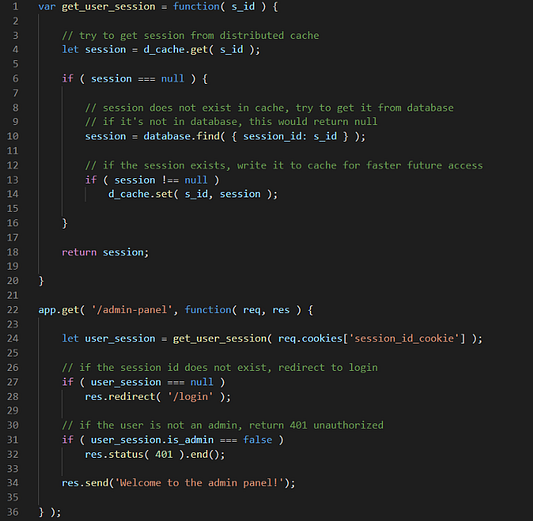
Как это сочетается с сессиями? Очень просто: вы храните сессии пользователей в распределенном кэше, а не в локальном. Пользователи делают запрос, и пользовательские сессии создаются и хранятся внутри кэш-сервера. В случае, когда последующие запросы перенаправляются на другой экземпляр, веб-сервер получает доступ к сессии клиента, извлекая состояние из распределенного кэша. Когда пользователь выполняет какое-либо действие, влияющее на его данные, изменение записывается и обновляется как в базе данных, так и в кэше. Если такие изменения базы данных выполняются асинхронно, то конечный пользователь никак не пострадает в плане скорости загрузки страницы.
Можно возразить: метод кэширования черного списка JWT предлагает те же преимущества — меньше запросов к базе данных, меньше кэширования, и очень быстрые ответы как следствие. Отчего отдавать победу именно распределенным сессиям? Есть несколько причин.
Прежде всего, JWT создавался не для того. JWT-токены должны быть переносимыми, быстрыми и простыми в проверке. Добавление еще одного уровня проверки с помощью хранилища данных (черный список или белый список) — то же самое, что реализация распределенного состояния сессии, но вместо того, чтобы пользовательская информация хранилась красиво упакованной и скрытой внутри хранилища данных, вы оставляете ее открытой в файле cookie на стороне клиента, а также храните копию JWT у себя в хранилище данных. Зачем оставлять информацию о пользователе на стороне клиента, если она уже надежно скрыта от публичного доступа, даже если данные не предполагаются настолько тайными?
Кроме того, реализация состояния сессии на стороне сервера расширяет возможности для внедрения большего количества функций в дальнейшем. В частности, открывает путь к работе с более деликатными данными о сессии клиента для усиления безопасности (например, IP-адрес последней авторизации, местоположение и т. д.). Если у вас в приложении есть функция публикации заметок, хранение содержимого заметки внутри сессии — гораздо более быстрое решение в плане поиска, чем запрос к базе данных.
Заключение
Балансируете нагрузку огромного сервиса, который требует аутентификации и авторизации? Кэш — король. Не только в плане аутентификации/авторизации.
Кэшируйте все, что можно.
На этом всё о распределенном состоянии сессии.
Читайте также:
- Иконки в веб-дизайне
- 5 основных рекурсивных задач на собеседованиях по программированию
- Создание простого веб-сервера с помощью Node.js и Express
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи: Dan Mitreanu, “Handling user authentication and authorization after load balancing your web app”




