
1. Что такое априорное распределение?
Априорная вероятность — это вероятность события до того, как мы получили дополнительные данные.
В байесовском выводе априорное распределение — это наше предположение о вероятности, основанное на уже имеющихся знаниях.
2. Что такое сопряженное априорное распределение?
Сопряженное априорное распределение невозможно понять без знания байесовского вывода.
(Байесовский вывод — интуиция и примеры)
Далее я предполагаю, что вы знаете принципы априорного, выборочного и апостериорного распределений.
Суть сопряженного априорного распределения
Для некоторых функций вероятности, если выбрать определенную априорную, апостериорная вероятность будет принадлежать тому же семейству распределений, что и эта априорная. Такое априорное распределение называется сопряженным.
На примерах объяснить проще. Ниже я привожу код для расчета апостериорного распределения биномиальной вероятности. θ — это вероятность успеха, и наша задача выбрать θ, которая максимизирует апостериорную вероятность:
import numpy as np
import scipy.stats as stats
success_prob = 0.3
data = np.random.binomial(n=1, p=success_prob, size=1000) # успех - это 1, неудача - 0.
# Область определения θ
theta_range = np.linspace(0, 1, 1000)
# Априорная вероятность P(θ)
a = 2
b = 8
theta_range_e = theta_range + 0.0001
prior = stats.beta.cdf(x = theta_range_e, a=a, b=b) - stats.beta.cdf(x = theta_range, a=a, b=b)
# Выборочное распределение (или функция правдоподобия) P(X|θ)
likelihood = stats.binom.pmf(k = np.sum(data), n = len(data), p = theta_range)
Существуют две вещи, которые затрудняют вычисление апостериорной вероятности. Во-первых, мы вычисляем апостериорную вероятность для каждой θ.
Зачем? Затем, что мы нормализуем апостериорную вероятность (строка 21). Даже если вы решите не нормализовывать ее, конечной задачей будет — найти апостериорный максимум (Оценка апостериорного максимума). Чтобы найти максимум, нам нужно рассмотреть каждого кандидата — правдоподобие P(X|θ) для каждой θ.
Во-вторых, если нет замкнутой формулы апостериорного распределения, нам нужно найти максимум с помощью численной оптимизации (например, градиентного спуска или метода Ньютона).
3. Как помогает сопряженное априорное распределение?
Зная, что априорное распределение является сопряженным, вы можете пропустить вычисление posterior = likelihood * prior. К тому же, если ваше априорное распределение имеет замкнутую форму, вы уже знаете, каким должен быть апостериорный максимум.
В примере выше бета-распределение является сопряженным априорным распределением биномиального распределения. Что это значит? На этапе моделирования мы уже знаем, что апостериорное распределение тоже будет бета-распределением. Следовательно, после большего количества экспериментов, вы можете вычислить апостериорную вероятность простым добавлением количества успехов и неудач к существующим параметрам α, β, соответственно, вместо перемножения функции вероятности и априорного распределения. Это очень удобно! Доказательство ниже.
В науке о данных или машинном обучении модель никогда не бывает полностью завершена — вам постоянно нужно обновлять ее с поступлением новых данных (вот зачем мы используем байесовский вывод).
Вычисления в баейсовском выводе бывают довольно трудоемкими, иногда даже неразрешимыми. Но если использовать формулу замкнутой формы с сопряженным априорным распределением, вычислить их становится проще простого.
4. Доказательство
Когда мы используем бета-распределение в качестве априорного, апостериорное распределение биномиального правдоподобия также является бета-распределением.
Бета порождает бета
Как выглядит плотность вероятности биномиального и бета-распределений?

Давайте подставим их в знаменитую формулу Байеса.
θ — вероятность успеха.
x — число успешных исходов.
n — общее число попыток, следовательно, n-x — это число неудач.
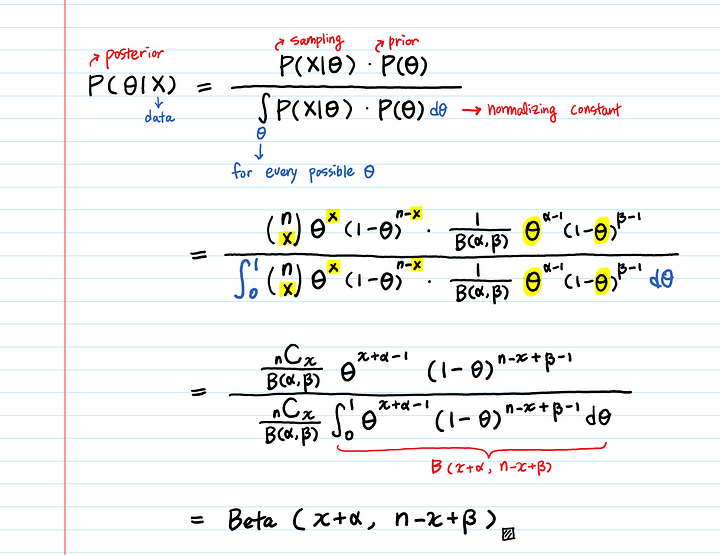
Априорное распределение P(θ) соответствовало Beta(α, β). После получения x успехов и n-x неудач из экспериментов, апостериорное распределение также становится бета-распределением с параметрами (x+α, n-x+β).
5. Сопряженное априорное распределение
Бета-распределение является сопряженным априорным распределением для распределений Бернулли, биномиального, отрицательного биномиального и геометрического (распределения, включающие в себя успех и неудачу).
<Beta posterior>
Beta prior * Bernoulli likelihood → Beta posterior
Beta prior * Binomial likelihood → Beta posterior
Beta prior * Negative Binomial likelihood → Beta posterior
Beta prior * Geometric likelihood → Beta posterior
<Gamma posterior>
Gamma prior * Poisson likelihood → Gamma posterior
Gamma prior * Exponential likelihood → Gamma posterior
<Normal posterior>
Normal prior * Normal likelihood (mean) → Normal posterior
Вот почему эти распределения (бета, гамма и нормальное) часто используются в качестве априорных.
И если вы изначально выбрали правильное априорное распределение, то даже после всех экспериментов и перемножения функции правдоподобия на априорное распределение окончательное распределение будет таким же, как и априорное.
Сопряженное априорное распределение P(θ) в уравнении:
P(θ) such that P(θ|D) = P(θ)
Сопряженное априорное = Удобное распределение
Несколько замечаний:
- Когда мы используем сопряженное априорное распределение, последовательная оценка (обновление расчетов после каждого наблюдения) дает такой же результат, что и групповое распределение.
- Чтобы найти апостериорный максимум, вам не нужно нормализовывать произведение функции вероятности (выборочного распределения) и априорного распределения (интегрирования всех возможных θ в знаменателе).

Максимум можно найти и без нормализации. Однако, если вам нужно сравнить апостериорные вероятности из разных моделей или рассчитать точечные оценки, нормализация необходима.
Читайте также:
- Рекуррентная нейронная сеть с головы до ног
- Объясняем производящую функцию моментов
- 3 функции Pandas, которые стоит использовать чаще
Перевод статьи Aerin Kim: Conjugate Prior Explained





